Mozilla files 423 CVEs, Gemini Flash-Lite up 3.75×, Willison ships commit tool
Mozilla auto-files 423 Firefox CVEs via Claude Mythos, Google reprices Flash-Lite 3.75× higher, and Willison ships a vibe-coded GitHub commit-count tool.
Mozilla files 423 CVEs, Gemini Flash-Lite up 3.75×, Willison ships commit tool
TL;DR
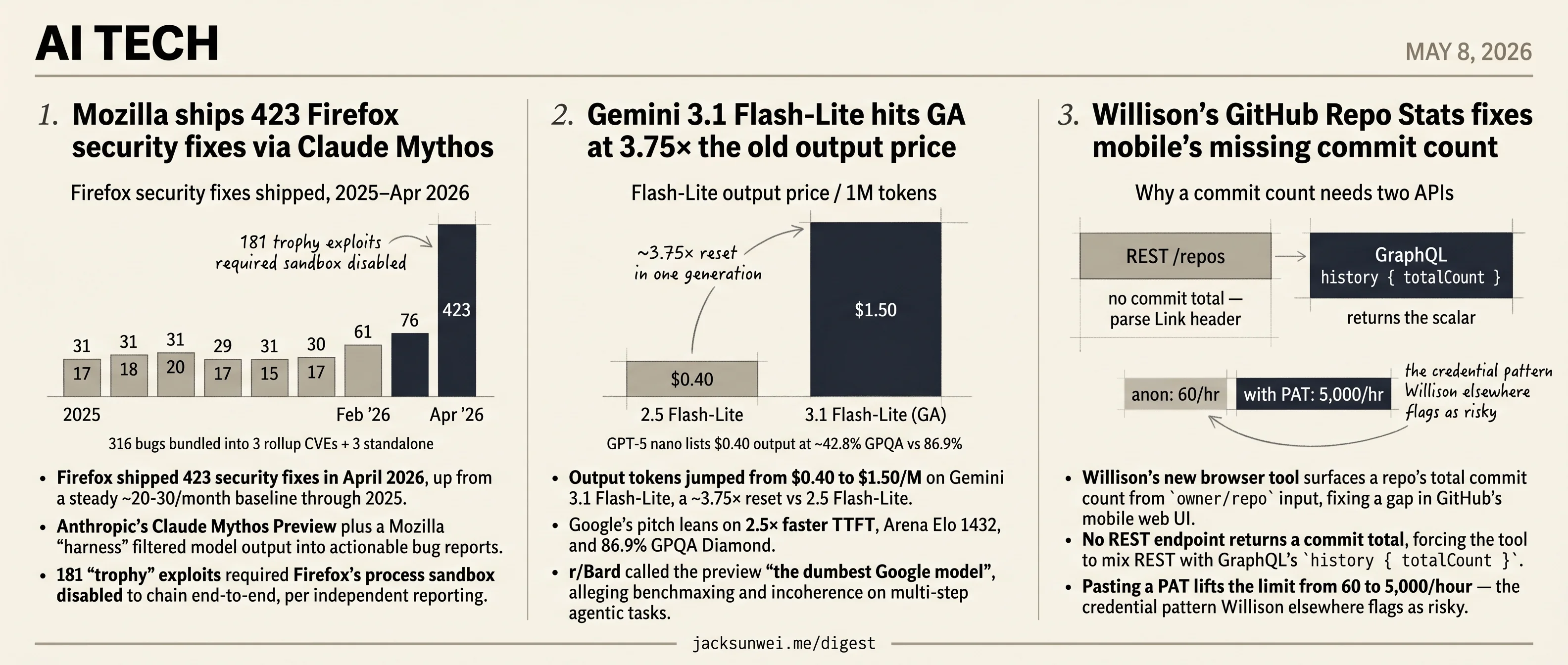
- Mozilla shipped 423 Firefox security fixes in April via Anthropic’s Claude Mythos Preview plus a custom harness.
- 181 trophy exploits required Firefox’s process sandbox disabled to chain end-to-end, per independent reporting.
- Gemini 3.1 Flash-Lite hit GA at $1.50/M output, a 3.75× jump from 2.5 Flash-Lite’s $0.40.
- r/Bard branded the preview the dumbest Google model, citing benchmaxing on multi-step agentic tasks.
- Willison’s commit-count tool asks users to paste a PAT to lift GitHub’s 60/hr rate limit to 5,000.
Three unrelated tech shipments land today, and the only thread tying them together is that AI is somewhere in the loop. Mozilla’s 423 Firefox fixes — a 15-20× spike over the 2025 baseline — were filtered through Claude Mythos Preview and a custom harness, with independent reporting noting 181 of the trophy exploits only chained end-to-end with the process sandbox disabled. Gemini 3.1 Flash-Lite hits GA at $1.50/M output tokens, up 3.75× from 2.5 Flash-Lite, while r/Bard greets the preview as the dumbest Google model. And Simon Willison’s new GitHub commit-count tool — built by prompt to patch a mobile-web gap — asks users to paste a personal access token to lift the API rate limit.
No single editorial line carries all three; the day is a CVE pipeline, a price card, and a personal utility, sitting next to each other on the calendar.
Mozilla ships 423 Firefox security fixes via Claude Mythos
Source: simon-willison · published 2026-05-07
TL;DR
- Firefox shipped 423 security fixes in April 2026, up from a steady ~20-30/month baseline through 2025.
- Anthropic’s Claude Mythos Preview plus a Mozilla “harness” filtered model output into actionable bug reports.
- 181 “trophy” exploits required Firefox’s process sandbox disabled to chain end-to-end, per independent reporting.
- Mozilla bundled fixes into 3 rollup CVEs covering 316 bugs, plus 3 standalone CVEs for Anthropic’s Red Team.
From slop to signal, in twelve months
Through 2025, Mozilla closed 17-31 security bugs per month. February 2026: 61. March: 76. April: 423. The cause, per Mozilla’s own writeup, is access to Anthropic’s Claude Mythos Preview wrapped in an internal harness that steers, stacks, and filters model output until what comes out the other end is worth a maintainer’s time. Two of the bugs found were old enough to drink — a 20-year-old XSLT vulnerability and a 15-year-old flaw in the <legend> element.
That this is even possible is the news. A year ago Daniel Stenberg shut down curl’s HackerOne bounty after AI-generated “slop” reports drove the signal-to-noise ratio under 5% 1. Same underlying technology, opposite operational outcome — the difference is entirely in the harness.
The asterisks on 423
The headline number is real but load-bearing on caveats.
First, the sandbox. Independent coverage notes that for a meaningful subset of trophy exploits, Anthropic ran Mythos against a Firefox build with the process sandbox disabled; roughly 181 of the reported exploits would not chain end-to-end against shipped Firefox 2. Mozilla’s post acknowledges that many attempted exploits were blocked by existing defense-in-depth — which is the same point, framed more comfortably. The AI is finding bugs; the gap between bugs and exploitable bugs is what two decades of browser sandboxing was engineered to widen.
Second, the CVE accounting. Mozilla grouped the bulk of fixes into three rollup CVEs — CVE-2026-6784 (154 bugs), CVE-2026-6785 (55), CVE-2026-6786 (107) — with only three standalone CVEs reserved for Anthropic Frontier Red Team findings 3. That’s reasonable triage for a flood of memory-safety patches, but it means “423 vulnerabilities” and “423 CVEs” are not the same thing.
Mythos vs. Big Sleep, and the leak
Mozilla’s result is best read against Google’s Big Sleep / Project Naptime, which has been publishing AI-found bugs since late 2024. Big Sleep optimizes for high-precision variant analysis — the SQLite CVE-2025-6965 catch, five WebKit credits from Apple. Mythos optimizes for volume sweeps across legacy codebases 4. Both find bugs fuzzers can’t; they answer different questions. The UK AI Security Institute separately confirmed Mythos as the first model to complete “The Last Ones,” a 32-step end-to-end attack simulation — while flagging that the test environment had no active human defenders 5.
The dual-use story complicates the celebration. Security Boulevard reports that unauthorized users — hobbyists in a private Discord — got Mythos Preview access on day one, via leaked credentials from Mercor, an Anthropic staffing contractor 6. The harness that closes 20-year-old XSLT bugs can also mint exploits for unpatched targets, and gating the model behind a corporate preview turns out to be a softer perimeter than advertised.
What actually changed
AI bug-hunting crossed from net-negative (Stenberg’s curl) to net-positive (Mozilla’s Firefox) in about twelve months — but only for projects that can afford to build the harness. For everyone else, the same capability is still arriving as inbound noise, and now it’s arriving from a stronger model.
Gemini 3.1 Flash-Lite hits GA at 3.75× the old output price
Source: simon-willison · published 2026-05-07
TL;DR
- Output tokens jumped from $0.40 to $1.50/M on Gemini 3.1 Flash-Lite, a ~3.75× reset vs 2.5 Flash-Lite.
- Google’s pitch leans on 2.5× faster TTFT, Arena Elo 1432, and 86.9% GPQA Diamond.
- r/Bard called the preview “the dumbest Google model”, alleging benchmaxing and incoherence on multi-step agentic tasks.
- GPT-5 nano lists ~80% cheaper ($0.05/$0.40) at roughly half the GPQA score (~42.8%).
What Simon’s one-liner skips
Simon Willison’s llm-gemini 0.31 release note flags one thing: gemini-3.1-flash-lite is no longer a preview. That’s accurate and load-bearing — GA means SLAs, stable output distributions, and a deprecation calendar plugin authors need to track. But “preview → stable” undersells what actually changed for anyone with a production pipeline pinned to the Flash-Lite tier.
The headline is the price. Output tokens moved from $0.40/M on 2.5 Flash-Lite to $1.50/M on 3.1 Flash-Lite, with input climbing from $0.10 to $0.25 7. That’s roughly a 3.75× output increase and 2.5× input increase in a single generation. One independent review pegs the new output price at ~65% above the small-model tier median 8. The “budget LLM” framing that justified building summarization, labeling, and reranking pipelines on Flash-Lite no longer fits cleanly.
The benchmarks-vs-vibes split
Google’s GA post is unambiguous on speed: 2.5× faster Time-to-First-Token, 45% faster output throughput, Arena Elo of 1432, and 86.9% on GPQA Diamond 9. Independent measurements broadly corroborate — ~389 tokens/sec and a 97% structured-output compliance rate, which is genuinely useful for the RAG and JSON-extraction work Simon highlights 8.
The dissent is sharp and specific. The top r/Bard thread during the preview window opened with:
Gemini 3.1 Flash Lite Preview is the dumbest Google model released so far… heavily fine-tuned to perform well at benchmarks but fails to maintain coherence in real world tasks. 10
That’s not a complaint about speed or eval scores — it’s a complaint that the eval scores don’t predict multi-step reliability. If you’re building agentic loops, the GPQA number is the wrong proxy.
Where it actually sits in the field
| Model | Input $/M | Output $/M | GPQA Diamond |
|---|---|---|---|
| GPT-5 nano | $0.05 | $0.40 | ~42.8% 11 |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | 86.9% 9 |
| Gemini 2.5 Flash-Lite (prior) | $0.10 | $0.40 | — |
GPT-5 nano is ~80% cheaper but less than half the GPQA score 11. The 3.1 Flash-Lite trade is “pay 3.75× more than last year for a smarter small model that some users say doesn’t act smarter.” Whether that pencils out depends entirely on whether your workload looks like the benchmarks or like the agentic tasks the Reddit thread is complaining about.
Migration deadlines worth pinning
For anyone who hard-coded the preview alias through llm-gemini: gemini-3.1-flash-lite-preview is scheduled for deprecation May 11 with final shutdown May 25, 2026 12. The legacy Vertex AI SDK path for Gemini sunsets after June 2026 in favor of the Google GenAI SDK, and the Interactions API schema flips from outputs to steps on May 26 12. Plugin maintainers have an ~18-day window before the preview alias starts erroring.
The GA stamp is real. The “obvious cheap default” framing is not.
Willison’s GitHub Repo Stats fixes mobile’s missing commit count
Source: simon-willison · published 2026-05-07
TL;DR
- Willison’s new browser tool surfaces a repo’s total commit count from
owner/repoinput, fixing a gap in GitHub’s mobile web UI. - No REST endpoint returns a commit total, forcing the tool to mix REST with GraphQL’s
history { totalCount }. - Pasting a PAT lifts the limit from 60 to 5,000/hour — the credential pattern Willison elsewhere flags as risky.
- Built by prompt, not by hand — a small case study in what Willison now calls vibe engineering.
A real UI gap, not a manufactured one
GitHub’s mobile web layout quietly drops the total commit count from the repo header, and Willison treats that number as a primary signal when triaging an unfamiliar dependency. The complaint isn’t idiosyncratic: the GitHub Community forum has a running “parity with the web app” thread asking for the commit count (and now star counts) to be restored on mobile 13. His new GitHub Repo Stats tool plugs that gap, taking either an owner/repo shorthand or a full URL and returning commits, stars, forks, branches, tags, language breakdown, contributors, and release history.
Why a “trivial” stats viewer isn’t trivial
The reason this took building rather than a one-liner is that GitHub’s REST API has no endpoint that simply returns a commit total. The standard workaround is to request per_page=1 and parse the Link header for the last-page number. GraphQL is cleaner — history { totalCount } on a branch object returns the scalar directly — but it requires picking a ref and burns against GitHub’s node-cost rate limiter 14. Willison’s tool routes around both problems by mixing protocols and exposing the rate-limit ceiling as a first-class UX concern: 60 requests/hour anonymous, 5,000/hour with a Personal Access Token.
The PAT question
That PAT field is where the tool collides with Willison’s own broader warnings. He has spent the last year migrating his terminology from “vibe coding” to “vibe engineering” precisely because LLM-built tools need disciplined testing and verification on top 15, and he’s publicly predicted a “Challenger disaster” moment for autonomous coding agents handed real credentials 16. Pasting a long-lived GitHub token into a third-party browser page isn’t autonomous-agent territory, but it’s adjacent: researchers recently documented “CursorJacking,” where AI editors stored PATs in unencrypted local SQLite that any installed extension could read 17.
For a tool you wrote yourself and host on your own domain, that risk is acceptable. For the pattern in general, it’s the exact failure mode Willison warns about.
Alternatives worth knowing
The browser-tool approach isn’t the only option. Practitioners on r/git point out that local commands — git rev-list --count HEAD for commits, git shortlog -sn --all for contributors — return the same numbers without an API token, without rate limits, and without granting any third party read access to private repos 18. Hosted competitors like OSS Insight and Star History cover overlapping ground for public projects.
Takeaway
Repo Stats is a small, honest piece of work: a one-prompt tool that fixes a genuine mobile-UI annoyance and quietly demonstrates why even “trivial” GitHub queries need two APIs to answer well. It’s also, read against its author’s own writing, a useful reminder that the friction between LLM-speed tooling and credential hygiene shows up even at the smallest scale — the moment you hand any browser tab a PAT.
Round-ups
Big Words
Source: simon-willison
Simon Willison vibe-coded a single-page web tool that turns URL query parameters into text slides, built to feed his URL-only macOS presentation tool. Options include gradient backgrounds, font weight, italics, uppercase, and drop shadow, with a settings panel revealed by double-clicking the page.
Footnotes
-
StartupFortune — Stenberg/curl context — https://startupfortune.com/firefox-shipped-423-fixes-in-april-after-claude-mythos-unearthed-271-vulnerabilities/
↩Daniel Stenberg ended curl’s HackerOne bug bounty in January 2026 after AI ‘slop’ reports collapsed signal-to-noise from ~15% valid to under 5%; Mythos arrived months later showing the same technology that DDoS’d maintainers can also find genuine 27-year-old OpenBSD bugs.
-
Medium post by independent researcher Gregory Hopper (via search synthesis) — https://vardhmanandroid2015.medium.com/claude-mythos-today-i-realized-ai-can-hack-better-than-most-humans-and-what-that-means-for-9a464ec60b16
↩For some ‘trophy’ exploits, Anthropic intentionally disabled Firefox’s multi-layered defense-in-depth mitigations—specifically the process sandbox… 181 of the reported Firefox exploits were achieved only by disabling the browser’s sandbox.
-
Cyberpress — CVE rollup breakdown — https://cyberpress.org/firefox-patches-423-vulnerabilities/
↩Mozilla grouped most of these into three major internal rollups: CVE-2026-6784 (154 bugs), CVE-2026-6785 (55 bugs), CVE-2026-6786 (107 bugs), plus three standalone CVEs for Anthropic Frontier Red Team findings.
-
MLQ.ai — Google Big Sleep comparison — https://mlq.ai/news/googles-ai-bug-hunter-big-sleep-reports-first-20-security-flaws-in-open-source-software/
↩Google’s Big Sleep focuses on ‘variant analysis’ and high-precision real-world zero-days like the SQLite stack buffer underflow (CVE-2025-6965); Mozilla’s Mythos approach instead demonstrates higher volume of discoveries across a massive legacy codebase.
-
Alan Turing Institute / CETaS report on Claude Mythos — https://cetas.turing.ac.uk/publications/claude-mythos-future-cybersecurity
↩AISI confirmed Mythos was the first model to complete ‘The Last Ones,’ a 32-step end-to-end cyber-attack simulation… but noted these successes occurred in environments lacking active human defenders.
-
Security Boulevard — Mythos unauthorized access — https://securityboulevard.com/2026/04/unauthorized-users-reportedly-gain-access-to-anthropics-mythos-ai-model/
↩Unauthorized users—primarily hobbyists from a private Discord—gained access to Claude Mythos Preview via shared credentials from Mercor, an AI staffing contractor, on the same day it was announced for limited corporate testing.
-
zerotwo.ai review — https://zerotwo.ai/blog/googles-gemini-3-1-flash-lite-is-the-fastest-cheap-ai-model-youve-never-heard-of
↩Output costs jumped from $0.40 to $1.50 per million tokens — a nearly four-fold increase versus 2.5 Flash-Lite, signalling the end of the budget-LLM era for high-volume pipelines.
-
automateed.com independent review — https://www.automateed.com/gemini-3-1-flash-lite-review
↩ ↩297% structured-output compliance and 389 tokens/sec throughput, but output pricing sits ~65% above the tier median, hurting output-heavy workloads.
-
Google Cloud blog (GA announcement) — https://cloud.google.com/blog/products/ai-machine-learning/gemini-3-1-flash-lite-is-now-generally-available
↩ ↩22.5x faster Time-to-First-Token and 45% faster output speed than Gemini 2.5 Flash, with an Arena Elo of 1432 and 86.9% on GPQA Diamond.
-
r/Bard thread (Reddit) — https://www.reddit.com/r/Bard/comments/1rowsdc/gemini_31_flash_lite_preview_is_the_dumbest/
↩Gemini 3.1 Flash Lite Preview is the dumbest Google model released so far… heavily fine-tuned to perform well at benchmarks but fails to maintain coherence in real world tasks.
-
intuitionlabs low-cost LLM comparison — https://intuitionlabs.ai/articles/low-cost-llm-comparison
↩ ↩2GPT-5 nano at $0.05/$0.40 per million tokens undercuts Gemini 3.1 Flash-Lite by ~80%, though it scores only ~42.8% on GPQA versus Flash-Lite’s 86.9%.
-
Gemini API changelog (ai.google.dev) — https://ai.google.dev/gemini-api/docs/changelog
↩ ↩2gemini-3.1-flash-lite-preview is scheduled for deprecation on May 11, 2026 with final shutdown May 25, 2026; Vertex AI SDK support for Gemini ends after June 2026.
-
GitHub Community feature request (gist mirror) — https://gist.github.com/seanpm2001/7e40a0e13c066a57577d8200b1afc6a3
↩Feature requests in the GitHub Community have called for ‘parity with the web app,’ explicitly asking for the repository commit count to be restored to the mobile view to match the desktop experience.
-
lfe.io docs — GitHub commit-count workarounds — http://docs2.lfe.io/v3/repos/statistics/
↩The GraphQL API exposes a totalCount field on the history object… preferred over REST for efficiency because it returns the scalar count in a single request without the overhead of paginating through actual commit nodes.
-
Simon Willison — ‘Vibe engineering’ (Oct 2025) — https://simonwillison.net/2025/Oct/7/vibe-engineering/
↩Willison has proposed the term ‘vibe engineering’ to describe a more disciplined workflow… using AI agents to handle the bulk of the implementation while the human developer focuses on rigorous manual testing and automated verification.
-
The New Stack — ‘Vibe coding could cause catastrophic explosions in 2026’ — https://thenewstack.io/vibe-coding-could-cause-catastrophic-explosions-in-2026/
↩Willison has famously predicted a ‘Challenger disaster’ for AI-assisted coding, warning that running autonomous coding agents with high-level system permissions could eventually lead to catastrophic data loss or security breaches.
-
Cyberpress — CursorJacking PAT exfiltration — https://cyberpress.org/cursor-ai-extension-token-access-flaw-could-lead-to-full-credential-compromise/
↩Some AI editors have been found storing PATs and session tokens in unencrypted local SQLite databases… any installed third-party extension—regardless of its declared permissions—can query the database to exfiltrate plaintext credentials.
-
r/git — commit history visualization tools thread — https://www.reddit.com/r/git/comments/1bqjpej/tools_to_visualize_commit_history_in_a_tree/
↩Local-first tools… bypass the GitHub API’s rate limits and eliminate the need to grant third-party applications read access to private codebases.