Microsoft ships MAI on cost, Holo3.1 lands at 1/10, Willison picks MicroPython
Microsoft's MAI debut, H Company's Holo3.1, and Willison's Datasette sandbox each trade frontier capability for a cheaper or lighter substrate.
Microsoft ships MAI on cost, Holo3.1 lands at 1/10, Willison picks MicroPython
TL;DR
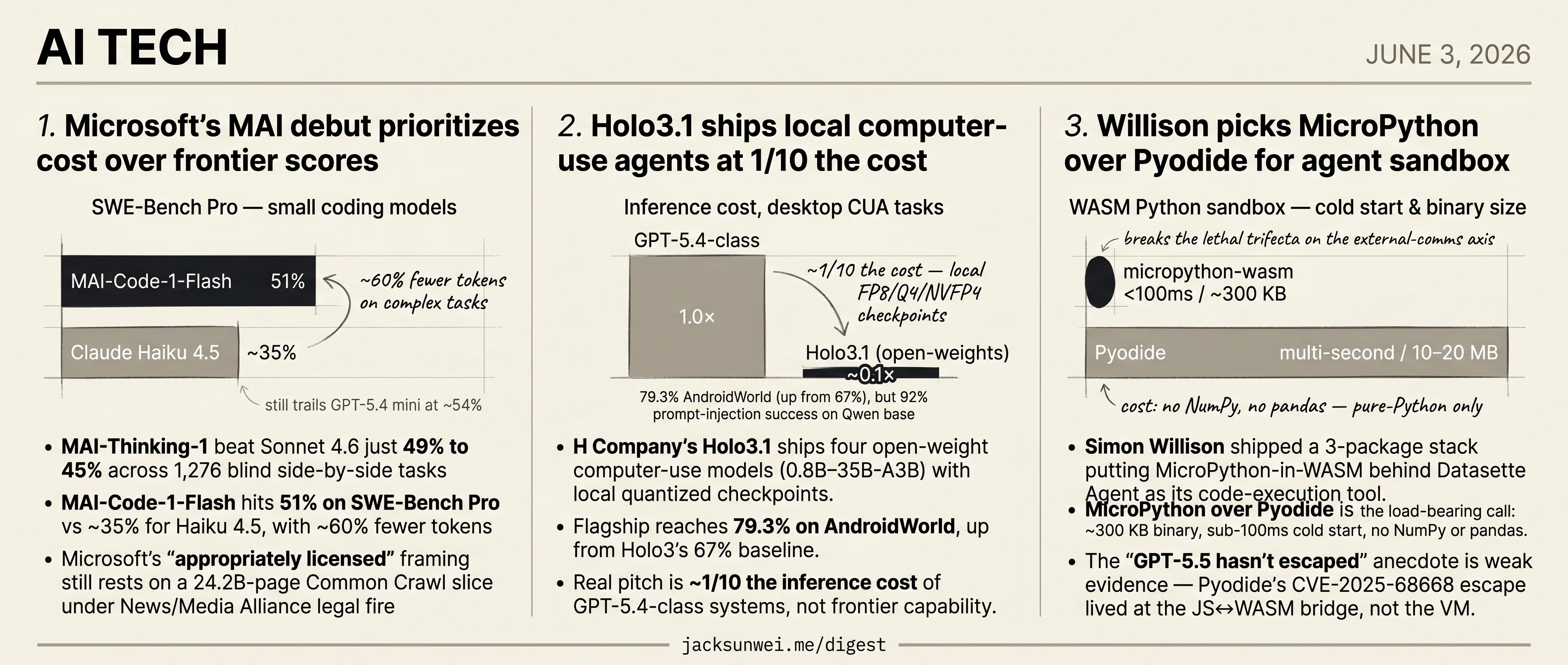
- MAI-Thinking-1 edges Sonnet 4.6 only 49% to 45% on 1,276 blind tasks.
- MAI-Code-1-Flash posts 51% on SWE-Bench Pro using ~60% fewer tokens than Haiku 4.5.
- H Company’s Holo3.1 hits 79.3% on AndroidWorld at roughly 1/10 the GPT-5.4-class inference cost.
- Holo3.1’s open-weight Qwen base takes 92% multi-turn prompt-injection success in red-teaming.
- Simon Willison ships MicroPython-in-WASM behind Datasette Agent over Pyodide for sub-100ms cold starts.
Today’s AI-tech ships share a substrate decision, not a capability one. Microsoft’s first in-house MAI models debut not at the frontier but a hair above Sonnet 4.6 — and the real signal is a 1T MoE running on Maia 200 silicon, cutting OpenAI dependency. H Company’s Holo3.1 open-weights four computer-use models whose pitch is ~1/10 the inference cost of GPT-5.4-class systems, not a new ceiling. And Simon Willison picks MicroPython over Pyodide for Datasette Agent’s code-exec sandbox — 300 KB, sub-100ms cold starts, no NumPy.
Each ship trades headline capability for a lighter, cheaper, or more independent base layer. Whether that’s the right trade depends on what breaks first: Microsoft’s licensing posture, Holo3.1’s 92% prompt-injection exposure, or the day a Datasette Agent user actually needs pandas.
Microsoft’s MAI debut prioritizes cost over frontier scores
Source: simon-willison · published 2026-06-02
TL;DR
- MAI-Thinking-1 beat Sonnet 4.6 just 49% to 45% across 1,276 blind side-by-side tasks
- MAI-Code-1-Flash hits 51% on SWE-Bench Pro vs ~35% for Haiku 4.5, with ~60% fewer tokens
- Microsoft’s “appropriately licensed” framing still rests on a 24.2B-page Common Crawl slice under News/Media Alliance legal fire
- A 1T MoE on Maia 200 silicon signals supply-chain independence from OpenAI, not a new frontier
”Preferred to Sonnet 4.6” — but only just
Microsoft’s headline claim, that MAI-Thinking-1 beats Claude Sonnet 4.6 in blind human evaluation, hides a four-point margin. The Surge-run side-by-side split 49% to 45% across 1,276 tasks, and experts attribute much of that gap to verbosity bias — raters preferring longer, more confident-sounding answers regardless of correctness 1. On static benchmarks the model is roughly at Claude Opus 4.6 parity (52.8% SWE-Bench Pro, 97% AIME 2025) but trails current leaders GPT-5.4 and Opus 4.8 by 15–20 points 2.
| Model | SWE-Bench Pro | Notes |
|---|---|---|
| MAI-Thinking-1 (1T / 35B active) | 52.8% | Parity with Opus 4.6 2 |
| GPT-5.4 / Opus 4.8 | ~68–73% | Current frontier 2 |
| MAI-Code-1-Flash (137B / 5B active) | 51% | ~60% fewer tokens 3 |
| Claude Haiku 4.5 | ~35% | 3 |
| GPT-5.4 mini | ~54% | 3 |
WindowsForum’s read is the right one: Microsoft is running a “frontier-adjacent” play, optimizing price-performance on its own silicon rather than chasing the leaderboard top 2.
MAI-Code-1-Flash is the better story
The smaller model has cleaner wins. Independent trackers credit it with 51% on SWE-Bench Pro against Haiku 4.5’s ~35%, and roughly 60% lower token consumption on complex tasks — material now that GitHub bills Copilot through usage-based AI Credits 3. The methodology explains the gap: Microsoft trained Flash inside the actual Copilot tool-use harness rather than on static code corpora, so it learns the loop it ships into.
The caveats are distribution and ceiling. At launch Flash is locked to Copilot Individual in VS Code — no Cursor, no Enterprise — and it still trails GPT-5.4 mini at ~54% on the same benchmark 3. It’s the best small coding model for people already inside Microsoft’s tools, and irrelevant outside them.
The “appropriately licensed” sleight of hand
Simon Willison’s own update walked back the cleanest reading of Microsoft’s data story after the technical paper revealed a 1.2-trillion-page proprietary crawl plus 24.2 billion Common Crawl pages in the corpus. The broader critique goes further. Hacker News commenters call “appropriately licensed” hand-wavy when applied to code, since even Apache 2.0 carries attribution requirements that tokenization destroys 4. The Common Crawl exposure is sharper still: the News/Media Alliance has formally demanded Common Crawl stop redistributing paywalled content, accusing the foundation of “laundering” copyrighted news for hyperscalers 5. That charge lands directly on Microsoft’s slice.
The rhetorical move worth flagging is the fusion of two distinct claims. “Zero distillation from third-party models” 6 is a narrow training-methodology statement; “clean and appropriately licensed data” is a sweeping legal one. Microsoft’s marketing leans on the first to imply the second, and the technical paper does not back the implication.
What the launch actually signals
Read as engineering, MAI is modest: roughly frontier-adjacent reasoning, a genuinely efficient code model, no architectural surprise. Read as strategy, it’s a declaration. A 1T-parameter MoE trained on 30T tokens, tuned to Maia 200 hardware with a claimed 1.4× perf/watt over GB200 6, is Microsoft demonstrating it can run the full stack — model, silicon, deployment harness — without OpenAI in the critical path. The question for the next quarter isn’t whether MAI-Thinking-2 catches GPT-5.4. It’s whether Microsoft starts routing Copilot traffic away from OpenAI by default, and what its 2030 partnership renegotiation looks like once it can.
Holo3.1 ships local computer-use agents at 1/10 the cost
Source: huggingface-blog · published 2026-06-02
TL;DR
- H Company’s Holo3.1 ships four open-weight computer-use models (0.8B–35B-A3B) with local quantized checkpoints.
- Flagship reaches 79.3% on AndroidWorld, up from Holo3’s 67% baseline.
- Real pitch is ~1/10 the inference cost of GPT-5.4-class systems, not frontier capability.
- Open-weight Qwen base means multi-turn prompt injection succeeds 92% in independent red-teaming.
A cost-and-locality play, not a new SOTA
Hcompany’s Holo3.1 release is a credible step forward for open-weight computer-use agents (CUAs), but the framing matters. The headline numbers — 79.3% on AndroidWorld for the 35B-A3B flagship, 72% for the 4B/9B tier — represent real gains over Holo3’s 67% and 58% baselines. They do not make Holo3.1 the frontier. Claude Opus 4.8 holds 83.4% on OSWorld-Verified, comfortably above the ~72% human baseline, and open-weight Qwen3 VL 235B reaches 66.7% 7. Holo3’s prior 122B model landed at 78.85% on OSWorld — competitive, mid-pack 8.
What Holo3.1 actually wins on is dollars and deployment. Independent analysis pegs the Holo line at roughly one-tenth the inference cost of GPT-5.4-class systems for comparable desktop tasks 8, and the new quantized checkpoints (FP8, Q4 GGUF, NVFP4) make local execution on a single workstation viable. For teams who can’t send screen contents to a third-party API — legal, healthcare, internal tooling — that tradeoff is the entire pitch.
Read the quantization numbers carefully
The “1.74× NVFP4 throughput vs BF16” claim deserves an asterisk. That figure assumes high-concurrency batch serving on DGX Spark hardware. At low concurrency — i.e., one user driving one agent, which is Holo’s stated local use case — NVFP4 runs about 20% slower than FP8 (41 vs 51 tokens/sec), because FP4 kernels remain immature. Vanilla vLLM on the GB10’s SM 12.1 architecture managed only 1.1 t/s until community patches landed 9.
The MoE design compounds this for interactive workloads. Holo3.1-35B-A3B activates only 3B parameters per token, but all 35B must still load into memory bandwidth at prefill, so a dense 9B model can be 4–9× faster to first token 10. The advertised 2× end-to-end step-time speedup (6.8s → 3.3s) is a serving-harness win, not a guarantee for a developer running the model on a single Mac.
The safety story the launch post skips
Computer-use agents are a categorically harder safety problem than chat models, and open-weight CUAs concentrate the risk. The RedTeamCUA benchmark reports attack success rates up to 66% against leading CUAs in hybrid Web-OS environments. Against Qwen-family bases — which Holo3.1 is built on — multi-turn prompt injection succeeded 92% of the time on capability-focused variants 11.
Privacy from the vendor is not the same as safety from the web pages the agent reads.
Hcompany’s local-inference framing emphasizes the first and elides the second. Worse, open weights mean derivative work moves fast: “abliterated” Holo variants with safety filters stripped have already surfaced on Hugging Face 12.
flowchart LR
A[User prompt] --> B{Holo3.1 CUA}
C[Web page / DOM] -.injected instructions.-> B
B --> D[Browser actions]
B --> E[Desktop / OS actions]
B --> F[Android actions]
D -. exfiltration .-> G((Attacker endpoint))
Migration tax
One practical footnote absent from the launch post: the switch from Holo3’s structured-JSON output to Holo3.1’s native function-calling protocol forces early adopters to rework their integration pipelines 12. A welcome change for new builds, a chore for existing ones.
The net read: Holo3.1 is a sharper, cheaper, more deployable open CUA — and a reminder that the prompt-injection tax on agents that click real buttons is still unpaid.
Willison picks MicroPython over Pyodide for agent sandbox
Source: simon-willison · published 2026-06-02
TL;DR
- Simon Willison shipped a 3-package stack putting MicroPython-in-WASM behind Datasette Agent as its code-execution tool.
- MicroPython over Pyodide is the load-bearing call: ~300 KB binary, sub-100ms cold start, no NumPy or pandas.
- The “GPT-5.5 hasn’t escaped” anecdote is weak evidence — Pyodide’s CVE-2025-68668 escape lived at the JS↔WASM bridge, not the VM.
- The design is a faithful implementation of Willison’s own “lethal trifecta” doctrine, not a new security idea.
A three-package stack, one design call
Willison’s drop is really one event in three commits: a base micropython-wasm build, a same-day 0.1a1 iteration on it, and datasette-agent-micropython 0.1a0 that wires the sandbox up as a tool Datasette Agent can call when a question outgrows SQL. The interesting thing isn’t the plumbing — it’s the choice of interpreter.
Most agent frameworks reach for Pyodide when they want Python-in-the-browser-or-WASM, because Pyodide ships a working scientific stack. Willison went the other way. Practitioner comparisons put MicroPython’s WASM binary near 300 KB with sub-100ms cold start, versus Pyodide’s 10–20 MB and multi-second initialization 13. For an agent loop that may spawn an interpreter per tool call, that gap is the difference between “snappy” and “unusable.”
The cost is honest and large. As one sandbox comparison puts it, MicroPython “cannot run many C-extension libraries common in data science (like NumPy), necessitating a ‘pure Python’ approach for all sandboxed analysis” 14. Datasette users hoping the agent will hand them pandas DataFrames will hit that wall on day one.
The lethal-trifecta logic
The release only makes sense inside Willison’s own threat model, now widely adopted: an agent becomes dangerous when it combines untrusted input, access to private data, and the ability to communicate externally 15. Meta has since formalized the same idea as the “Agents Rule of Two” — never satisfy more than two of those properties without a human in the loop 16.
Sandboxing the code-execution tool is precisely how you break the trifecta on the external communication axis while still letting the agent touch a private SQLite database. Strip network and filesystem syscalls from the WASM import table and “exfiltrate the data” stops being a one-line script. Wasmtime’s fuel metering (store.add_fuel) handles the orthogonal denial-of-service problem by capping instruction count on LLM-generated loops 17 — a more concrete defense than the blog post’s adversarial-LLM anecdote.
Where this could actually break
“GPT-5.5 failed to break out” should be read against CVE-2025-68668, a documented Pyodide sandbox escape in n8n where process-handling primitives leaked through the JS↔WASM bridge to full host compromise 18. The escape happened at the bridge layer, not inside the VM — which is exactly where micropython-wasm’s new host-guest interop code now lives. Asking a frontier model to jailbreak a sandbox is a weak proxy for the manual exploit work that found that CVE.
What it’s actually competing with
| Sandbox | Isolation | Cold start | Python ecosystem |
|---|---|---|---|
micropython-wasm | WASM VM, in-process | <100ms 13 | Pure-Python only 14 |
| Pyodide | WASM VM, in-process | Multi-second 13 | NumPy/pandas work |
| E2B | Firecracker microVM 13 | VM-boot class | Full CPython |
| Cloudflare / Deno isolates | V8 isolate | 5–50ms 13 | JS-first |
Willison’s stack is differentiated by being embeddable in a single Python process with no external service — exactly what a self-hosted Datasette deployment wants, and exactly what a multi-tenant SaaS would refuse. That’s a narrower pitch than “safe code execution for AI agents,” and it’s the right one.
Further reading
- micropython-wasm 0.1a1 — simon-willison
- micropython-wasm 0.1a0 — simon-willison
Round-ups
JetBrains releases Mellum2, a 12B mixture-of-experts code model
Source: huggingface-blog
JetBrains has launched Mellum2, a 12-billion-parameter mixture-of-experts model aimed at code completion inside its IDEs. The successor to the original Mellum leans on sparse expert routing to lift quality without ballooning inference cost, positioning JetBrains against Copilot’s underlying models.
xAI’s Ethan He explains how Grok Imagine shipped in 3 months
Source: latent-space
Grok Imagine’s tech lead Ethan He breaks down the 3-month sprint behind xAI’s video generator on Latent Space, contrasting videogen pipelines with world models and arguing video agents are the next frontier beyond static image and text generation.
MIT guide maps where small businesses should plug in LLMs
Source: mit-tech-review-ai
Small businesses lack the staff depth of large firms across accounting, design, market research and product work — gaps that LLMs increasingly fill. MIT Technology Review’s Making AI Work newsletter walks owners through where models actually pay off versus where they stall.
Simon Willison posts pelican sighting from Microsoft Build
Source: simon-willison
Simon Willison shares a photo of a California Brown Pelican diving behind the Microsoft Build venue at Fort Mason, San Francisco. A brief aside tagged with llm-release hints he’s on the ground for the conference’s AI announcements.
Footnotes
-
Latent Space (AI News digest) — https://www.latent.space/p/ainews-microsoft-build-mai-thinking
↩MAI-Thinking-1 won 49% of 1,276 tasks compared to Sonnet 4.6’s 45%… a narrow margin that experts argue could be a byproduct of verbosity bias
-
WindowsForum analysis of Build 2026 Foundry strategy — https://windowsforum.com/threads/build-2026-microsoft-mai-models-foundry-control-plane-and-optionality-vs-openai.421932/
↩ ↩2 ↩3 ↩4While MAI-Thinking-1 matches early-2026 benchmarks (53% on SWE-bench Pro), it trails current leaders like GPT-5.4 and Opus 4.8 by 15–20 points… Microsoft’s ‘harness-first’ strategy prioritizes ‘frontier-adjacent’ utility over academic leadership
-
failingfast.io AI coding benchmark tracker — https://failingfast.io/ai-coding-guide/benchmarks/
↩ ↩2 ↩3 ↩4 ↩5MAI-Code-1-Flash achieved a 51% success rate on SWE-Bench Pro—a significant lead over Claude Haiku 4.5 at ~35%—and reportedly consumes up to 60% fewer tokens on complex tasks
-
Hacker News discussion (item 48374362) — https://news.ycombinator.com/item?id=48374362
↩‘appropriately licensed’ is a ‘hand-wavy’ term when applied to massive code repositories like GitHub, noting that even permissive licenses (e.g., Apache 2.0) typically require attribution that is difficult to maintain through the tokenization process
-
Mashable on Common Crawl/News Media Alliance — https://mashable.com/article/common-crawl-accused-sharing-paywalled-content-ai-companies
↩The News/Media Alliance submitted a formal demand for Common Crawl to cease unauthorized scraping, arguing that the foundation’s open-access mission has been co-opted to ‘launder’ copyrighted news content for tech giants
-
businessengineer.ai technical breakdown — https://businessengineer.ai/p/has-microsoft-just-entered-the-frontier
↩ ↩2trained ‘from the ground up’ on 30 trillion tokens without using distillation from third-party models like GPT-4, a move Microsoft calls ‘learned, not inherited’ intelligence… optimized for Microsoft’s Maia 200 silicon, which reportedly yields a 1.4x performance-per-watt advantage over the GB200 baseline
-
awesomeagents.ai (Computer Use Leaderboard) — https://awesomeagents.ai/leaderboards/computer-use-leaderboard/
↩Claude Opus 4.8 currently leads the leaderboard with a verified success rate of 83.4%, surpassing the human baseline of roughly 72%… Qwen3 VL 235B represents the open-source frontier with a score of 66.7%.
-
Medium — Holo3 vs GPT-5.4 cost analysis — https://ai-engineering-trend.medium.com/holo3-the-ai-model-that-outperforms-gpt-5-4-at-one-tenth-the-cost-for-computer-usage-24b1380f4865
↩ ↩2Holo3-122B-A10B model… scored 78.85% on OSWorld-Verified, surpassing GPT-5.4 (72.4%) and Claude Opus 4.6 (38%)… claimed to be roughly one-tenth the cost of competing proprietary models.
-
note.com (DGX Spark NVFP4 benchmarks) — https://note.com/pju/n/ndb7e47ac938a?hl=en-US
↩At low concurrency (single-request latency), NVFP4 can actually be 20% slower than FP8 (41 t/s vs 51 t/s) due to the relative immaturity of FP4 kernels… vanilla vLLM implementations crawl at 1.1 tokens/s on the GB10 chip (SM 12.1) without custom patches.
-
Medium — MoE architecture guide — https://medium.com/@SuriNaren/beyond-dense-models-the-complete-guide-to-mixture-of-experts-moe-architecture-d767c8a4ef0f
↩In MoE architectures, the entire 35B parameter set must be loaded into memory bandwidth to process the initial prompt. Consequently, a dense 9B model can be 4x to 9x faster at starting a response than the 35B-A3B.
-
Palo Alto Unit 42 / RedTeamCUA findings — https://unit42.paloaltonetworks.com/ai-agent-prompt-injection/
↩The RedTeamCUA benchmark, which tests agents in hybrid Web-OS environments, found that even leading computer-use agents suffer from attack success rates of up to 66%… multi-turn prompt injection attacks achieved success rates as high as 92% on capability-focused models like Qwen.
-
develeap.com (Holo3.1 review) — https://www.develeap.com/news/holo3-1-fast-local-computer-use-agents/
↩ ↩2The transition from structured JSON output to native function-calling has forced some early adopters to rework their integration pipelines… some community members on Hugging Face have raised concerns regarding ‘abliterated’ versions of the model.
-
fast.io — code execution sandboxes for AI agents comparison — https://fast.io/resources/best-code-execution-sandboxes-ai-agents/
↩ ↩2 ↩3 ↩4 ↩5E2B uses Firecracker microVMs, providing kernel-level isolation… Cloudflare Dynamic Workers and Deno Subhosting utilize V8 Isolates… startup times as low as 5ms to 50ms
-
Blaxel.ai — sandbox comparison for AI agents — https://blaxel.ai/blog/code-execution-sandboxes-for-ai-agents
↩ ↩2MicroPython… cannot run many C-extension libraries common in data science (like NumPy), necessitating a ‘pure Python’ approach for all sandboxed analysis
-
HiddenLayer — ‘The Lethal Trifecta and How to Defend Against It’ — https://www.hiddenlayer.com/research/the-lethal-trifecta-and-how-to-defend-against-it
↩LLMs cannot inherently distinguish between developer instructions and data provided by untrusted sources
-
Argemma blog — ‘Lethal Trifecta: No Choice’ — https://argemma.com/blog/lethal-trifecta-no-choice/
↩the ‘Agents Rule of Two,’ which mandates that an autonomous agent should never satisfy more than two of these properties simultaneously without human supervision
-
Medium — ‘Python wasmtime in servers: safe sandbox for untrusted UDFs’ — https://medium.com/@2nick2patel2/python-wasmtime-in-servers-safe-sandbox-for-untrusted-udfs-at-near-native-speed-ed858be1c48e
↩By calling store.add_fuel(limit), the host specifies a maximum number of WebAssembly instructions… If the guest exceeds this limit, execution is terminated, preventing infinite loops
-
Penligent.ai security writeup on CVE-2025-68668 — https://www.penligent.ai/hackinglabs/cve-2025-68668-deep-dive-the-n8n-pyodide-sandbox-escape-ai-infrastructure-risk/
↩a sandbox bypass in the n8n platform’s use of Pyodide, where certain process-handling capabilities allowed full host compromise