Gemma 4 skips vision guards, Reachy Mini trusts MCP, Android verifies in-stack
Three AI-tech ships today each add a capability whose new gap lands on a trust check one layer downstream.
Gemma 4 skips vision guards, Reachy Mini trusts MCP, Android verifies in-stack
TL;DR
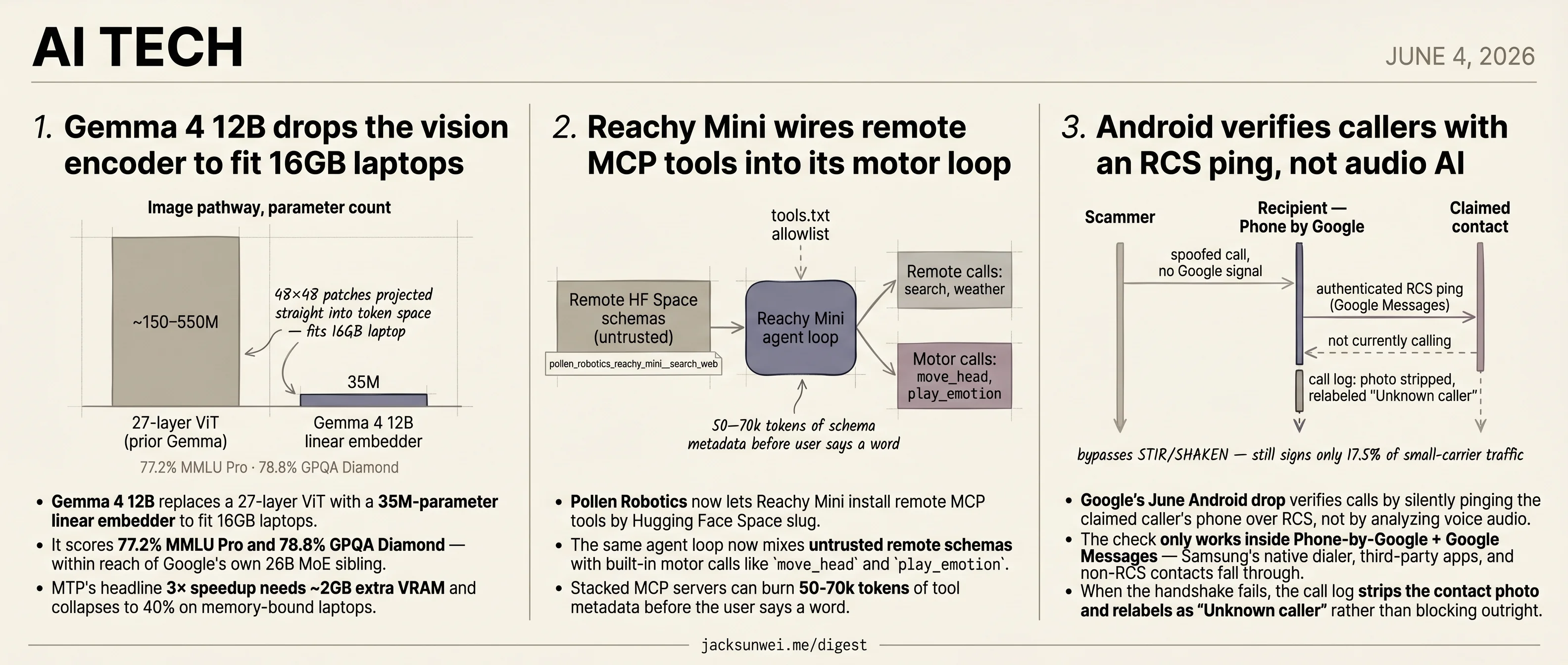
- Gemma 4 12B swaps a 27-layer ViT for a 35M linear embedder to fit 16GB laptops.
- Encoder-free Gemma breaks vision-tower guardrails that scan image features before the LLM.
- Reachy Mini mixes untrusted remote MCP schemas with built-in calls like
move_head. - Stacked MCP servers can burn 50-70k tokens of metadata before the user speaks.
- Android’s June drop verifies callers via silent RCS ping, only inside Phone-by-Google.
Today’s three AI-tech ships each add a new capability — and each lands its asterisk on a trust check one layer downstream. Google’s Gemma 4 12B drops a 27-layer vision transformer for a 35M-parameter linear embedder so the model fits 16GB laptops, but the encoder-free design breaks the vision-tower guardrails that used to scan image features before they hit the LLM. Pollen Robotics’ Reachy Mini now installs remote MCP tools by Hugging Face Space slug, mixing untrusted remote schemas into the same agent loop that drives move_head and play_emotion. Android’s June drop verifies callers with a silent RCS handshake instead of audio analysis — a tidy mechanism that only fires inside Phone-by-Google plus Google Messages, and quietly sidesteps the carrier-side STIR/SHAKEN signing it was meant to backstop.
The shipped feature is the headline; the broken check downstream is what each launch pitch leaves to the docs.
Gemma 4 12B drops the vision encoder to fit 16GB laptops
Source: ars-technica-ai · published 2026-06-03
TL;DR
- Gemma 4 12B replaces a 27-layer ViT with a 35M-parameter linear embedder to fit 16GB laptops.
- It scores 77.2% MMLU Pro and 78.8% GPQA Diamond — within reach of Google’s own 26B MoE sibling.
- MTP’s headline 3× speedup needs ~2GB extra VRAM and collapses to 40% on memory-bound laptops.
- Encoder-free design breaks vision-tower guardrails that scan image features before they hit the LLM.
The real trick is what’s missing
Google’s pitch for Gemma 4 12B is “runs on a 16GB laptop.” The actual engineering story is that they deleted the vision tower. Earlier Gemma multimodal variants leaned on a 27-layer Vision Transformer; Gemma 4 12B swaps it for a 35M-parameter linear embedder that projects 48×48 pixel patches straight into the token space, and slices raw 16kHz audio into 40ms / 640-float frames projected the same way 1. That single decision strips out somewhere between 150M and 550M parameters of encoder overhead — which is most of the reason an 18GB weights file now fits in consumer RAM.
This is not a new idea. Adept’s Fuyu used linear image projection; Meta’s Chameleon went further with discrete early-fusion image tokens. Both hit a known wall: scaling past ~8B parameters destabilizes the softmax because text and image tokens carry very different entropy distributions 2. Whether Gemma 4 12B genuinely solves that — versus papering over it with training tricks that show up later as weird failure modes — is something no third party has stress-tested yet.
Benchmarks that almost justify the framing
The “nearly matches the 26B MoE” line holds up better than usual vendor comparisons. MarkTechPost’s numbers put the 12B at 77.2% on MMLU Pro and 78.8% on GPQA Diamond 3 — close enough to the larger MoE that for most local-inference use cases, the smaller model is the obvious pick. Combined with the Apache 2.0 license, it slots cleanly into the segment Mistral and Qwen have been contesting.
The asterisks Ars skipped
Two caveats matter for anyone planning to actually deploy this.
First, Multi-Token Prediction is not free. Google’s own MTP documentation says the drafter and its KV cache need roughly 2GB of additional VRAM, and the speedup ranges from 40% on memory-bound consumer GPUs to the headline 3× only when the model fits entirely in VRAM 4. On a 16GB laptop running a 4-bit quant, that 2GB is a real budget decision — you may have to choose between MTP and a usable context window.
Second, the media caps are tight. Google’s developer guide limits native audio to 30 seconds and video to 60 seconds per inference, so any realistic transcription or video-understanding workload needs a chunking layer on top 5. The “analyzes audio and video locally” framing is true at the demo scale and an integration project at the production scale.
A safety pipeline that no longer has a place to plug in
The under-reported consequence of going encoder-free: conventional multimodal guardrails inspect vision-tower outputs before they reach the language model. That interception point no longer exists. VentureBeat quotes developers calling the design “inconvenient” for safety tools, which is why third parties like Hirundo are already shipping weight-level unlearning variants instead of filter wrappers 6.
The encoder-free design has been described by some developers as ‘inconvenient’ for safety tools that typically scan vision-tower outputs before they reach the language model. 6
That’s the real tradeoff Google made for the 16GB number — not just smaller weights, but a different deployment surface that the existing safety tooling ecosystem isn’t built for yet.
Reachy Mini wires remote MCP tools into its motor loop
Source: huggingface-blog · published 2026-06-03
TL;DR
- Pollen Robotics now lets Reachy Mini install remote MCP tools by Hugging Face Space slug.
- The same agent loop now mixes untrusted remote schemas with built-in motor calls like
move_headandplay_emotion. - Stacked MCP servers can burn 50-70k tokens of tool metadata before the user says a word.
- Pollen’s slug-based namespacing already crowds Anthropic’s 64-character tool-name limit.
What shipped
Reachy Mini’s conversation app now treats Hugging Face Spaces as a tool registry. A user adds a Space slug from the CLI, the app probes its MCP endpoint, namespaces the tools with double underscores (pollen_robotics_reachy_mini_search_tool__search_web), and stores the source in installed_tool_spaces.json. A per-profile tools.txt allowlist plus an instructions.txt system prompt govern which tools the LLM sees and how it’s nudged to call them in parallel. Two canary Spaces — a web-search tool and a weather tool — ship as proof, and Pollen is asking developers to tag their own Spaces with reachy-mini-tool for discovery.
That’s the clean integration story. The interesting parts are what sits underneath it.
A confused deputy with actuators
Reachy Mini’s built-in tools drive physical hardware. Remote MCP tools arrive as schemas the LLM reads as instructions. Those two facts now share one agent loop:
flowchart LR
A[Remote HF Space<br/>tool schemas] --> B{Reachy Mini<br/>agent loop}
C[tools.txt allowlist] -.gates.-> B
B --> D[Remote MCP calls<br/>search, weather]
B --> E[Built-in motor calls<br/>move_head, play_emotion]
A -. poisoned description .-> B
The MCP security literature has documented this exact shape as the high-risk one. Tool poisoning — where a malicious description hijacks the model’s logic before any command runs — and “rug pulls,” where an approved Space silently updates its behaviour post-install, are the canonical attacks against registry-plus-allowlist designs 7. The tools.txt allowlist gates which tools are visible; it does not stop a poisoned description from steering the LLM into invoking a local motor function on the attacker’s behalf. Separately, Tom’s Hardware reports a systemic RCE-class flaw in official MCP SDKs tied to STDIO process execution 8 — relevant because the post is encouraging users to wire arbitrary community Spaces into a loop that already has hardware access.
The context tax nobody charts
Pollen frames parallel tool calling as a latency win. The bigger cost is upstream: every registered MCP server dumps its full schema into context, and practitioner measurements put stacked-server overhead at 50,000-70,000 tokens of pure metadata before the first user turn 9. Independent coverage of this same Reachy Mini feature confirms the ecosystem is already large enough to make that bite — roughly 200 community apps from 150+ creators across ~10,000 units in the wild 10. A naïve “install everything interesting” profile will eat the conversational memory that makes the robot feel present.
Naming and Gradio friction
The double-underscore convention isn’t Pollen’s invention — it’s the de-facto Anthropic-side namespacing standard, and it has a hard 64-character ceiling that already breaks real tools like AWS’s documentation search once the mcp__server__ prefix is prepended 11. Pollen’s slugs are long. Any non-trivial tool name will press against the wall.
Gradio compounds this. The framework has been observed emitting tool names containing <Lambda> that fail client-side pattern validation in Claude and Cursor, and it offers no per-function visibility control — every show_api=True endpoint becomes an MCP tool whether you wanted it exposed or not 12. The article’s “Gradio Spaces fully supported ✅” line is doing some work.
What to watch
The integration is the right shape for a hobbyist robot ecosystem. The missing column in Pollen’s capability table is risk: signed/pinned tool descriptions to blunt rug pulls, schema budgets per profile, and a way to scope remote tools away from motor calls. Until those exist, the safest Reachy Mini profile is a short one.
Android verifies callers with an RCS ping, not audio AI
Source: ars-technica-ai · published 2026-06-02
TL;DR
- Google’s June Android drop verifies calls by silently pinging the claimed caller’s phone over RCS, not by analyzing voice audio.
- The check only works inside Phone-by-Google + Google Messages — Samsung’s native dialer, third-party apps, and non-RCS contacts fall through.
- When the handshake fails, the call log strips the contact photo and relabels as “Unknown caller” rather than blocking outright.
- The architecture sidesteps carrier STIR/SHAKEN, which still signs only 17.5% of small-carrier traffic.
A device-to-device handshake, not a deepfake detector
Google’s pitch is structurally interesting: instead of trying to hear that a caller is synthetic, Android asks the caller’s phone whether it actually placed the call. When an incoming call claims to be from a saved contact but arrives without Google’s outbound verification signal, the recipient device fires an authenticated RCS ping to that contact through Google Messages. If the contact’s phone replies that it isn’t dialing, the user gets a scam warning; Notebookcheck adds that the call log also drops the contact photo and relabels the caller as “Unknown caller” — a softer, ambiguous signal rather than a hard block 13.
sequenceDiagram
participant Scammer
participant Recipient as Recipient (Phone by Google)
participant Contact as Claimed contact's phone
Scammer->>Recipient: Spoofed call (no Google signal)
Recipient->>Contact: Authenticated RCS ping (Google Messages)
Contact-->>Recipient: "Not currently calling"
Recipient->>Recipient: Strip photo, label "Unknown caller", warn user
The clever part is what it doesn’t do: no cloud audio analysis, no model inference on the call stream, no dependence on whether the spoofed voice sounds convincing. The fragile part is what it requires — both endpoints inside Google’s app stack, RCS reachable, and the contact’s device awake enough to answer the handshake.
Where the cracks are
eWeek’s coverage flags the obvious failure mode: RCS latency or sync delays can stall the silent handshake on entirely legitimate calls, and once users see warnings on real contacts they start ignoring the warnings on real scams 14. No independent false-positive rate has been published. That matters more than usual because Google’s other line of defense — on-device deepfake audio screening for unknown numbers — runs into a hard ceiling: commercial detectors that claim 96–98% lab accuracy fall over on noisy real-world calls, with partial-deepfake false-positive rates above 50% 15.
The ecosystem politics are sharper. Pindrop’s data shows why Google moved at the app layer: STIR/SHAKEN signs 85% of traffic between tier-1 U.S. carriers but only 17.5% from smaller and rural ones, leaving wide unverified corridors that robocallers route through 16. Carriers are not thrilled to be routed around.
The CTIA urged regulators to avoid “prescriptive technology mandates” that might favor specific proprietary solutions like Google’s over the competitive, carrier-led market. 17
That’s the turf war in one sentence: Google verifies device-to-device and bypasses the PSTN; carriers want verification to live in their trust chain via Branded Calling ID and similar schemes.
Why the urgency is real even if the framing isn’t
Ars cites “$3 billion lost to financial fraud in 2024.” The FBI’s 2025 IC3 report puts total cyber-enabled losses at $20.9 billion, with a first-ever dedicated AI category logging 22,364 complaints and $893M in verified losses 18. AI-voice fraud is still a small slice, but it’s the fastest-growing one, and STIR/SHAKEN was not designed for an adversary that can synthesize your daughter’s voice from a TikTok clip.
Google’s answer is the right shape — verify the device, not the audio — wrapped in the wrong distribution model. Until the handshake works across Samsung Phone, third-party dialers, and non-RCS contacts, the warning users see most often will be the false-positive one.
Footnotes
-
Gigazine — https://gigazine.net/gsc_news/en/20260604-gemma-4-12b-encoder-free/
↩A 35-million-parameter ‘embedder’ replaces the 27-layer Vision Transformer (ViT) found in other Gemma variants… raw 16 kHz audio signals are sliced into 40ms frames—comprising 640 floats each—and projected linearly into the token space.
-
Georgia Tech lecture slides on Chameleon — https://faculty.cc.gatech.edu/~zk15/teaching/AY2024_cs8803vlm_fall/slides/L15_Chameleon.pdf
↩Scaling Chameleon beyond 8B parameters caused severe instabilities because the transformer’s softmax operation struggled with the varying entropy of text versus image tokens.
-
↩Despite its compact architecture, benchmarks show it nearing the reasoning capabilities of the larger 26B Mixture-of-Experts (MoE) model, scoring 77.2% on MMLU Pro and 78.8% on GPQA Diamond.
-
Google AI Developers (MTP overview) — https://ai.google.dev/gemma/docs/mtp/overview
↩MTP is memory-intensive; enabling it typically requires an additional 2GB of VRAM for the drafter and associated KV cache… users report speedups ranging from 40% to 3x.
-
Google Developers Blog (Gemma 4 12B Developer Guide) — https://developers.googleblog.com/gemma-4-12b-the-developer-guide/
↩Native audio and video processing are capped at 30 seconds and 60 seconds respectively, requiring ‘chunking’ architectures for longer files.
-
↩ ↩2Hirundo’s hardened checkpoints use weight-level machine unlearning to remove susceptibility to adversarial manipulation without relying on external filters… the encoder-free design has been described by some developers as ‘inconvenient’ for safety tools that typically scan vision-tower outputs before they reach the language model.
-
deepsense.ai — ‘Is MCP Killing Your Security?’ — https://deepsense.ai/blog/is-mcp-killing-your-security-a-wake-up-call-for-developers-and-users/
↩A poisoned tool description can hijack the model’s logic before a single command is executed… ‘rug pulls’ occur when a seemingly benign tool is approved by the user but later receives a remote update that changes its functionality to exfiltrate data.
-
Tom’s Hardware — Anthropic MCP security flaw — https://www.tomshardware.com/tech-industry/artificial-intelligence/anthropics-model-context-protocol-has-critical-security-flaw-exposed
↩A systemic architectural flaw in official MCP SDKs allows for Remote Code Execution… stemming from how the protocol handles local process execution via the STDIO interface.
-
Medium — ‘The AI Industry Is Lying to You About MCP’ — https://medium.com/developersglobal/the-ai-industry-is-lying-to-you-about-mcp-here-is-why-i-stopped-using-it-148fb810c9ea
↩Every active MCP server loads its entire schema into the model’s context… this can consume 50,000 to 70,000 tokens before a single command is issued, effectively making the AI less capable due to ‘lost in the middle’ effects.
-
getaibook.com — Extending Reachy Mini with Remote MCP Tools — https://getaibook.com/blog/how-to-extend-reachy-mini-capabilities-with-remote-mcp-tools/
↩As of May 2026, the community had shipped over 200 apps from more than 150 unique creators… with nearly 10,000 Reachy Mini units in the wild.
-
Scribd — Claude Code Definitive Guide (MCP naming) — https://www.scribd.com/document/1013768399/Claude-Code-the-Definitive-Guide-to-Agentic-Development
↩An official AWS tool named aws_knowledge_aws___search_documentation failed when the total length reached 74 characters after being namespaced by the client… the mcp__server__ prefix consumes nearly 15-20 characters.
-
Medium — ‘MCP Security Is a Mess: 5 Ways I Broke My Own Agent’ — https://medium.com/data-science-collective/mcp-security-is-a-mess-5-ways-i-broke-my-own-ai-agent-76379a46ca90
↩Gradio occasionally generates tool names containing special characters such as
which cause pattern match errors in major AI clients like Claude and Cursor… developers cannot selectively hide specific tools from the MCP endpoint without completely disabling the API for the entire Space. -
Notebookcheck — https://www.notebookcheck.net/Android-fake-call-detection-Google-uses-RCS-to-stop-AI-scams.1314360.0.html
↩If verification fails, the contact’s photo may disappear and their name may be replaced with ‘Unknown caller’ in the call log to signal a lack of authentication.
-
eWeek — https://www.eweek.com/news/android-fake-call-detection-ai-voice-scams/
↩Experts have raised concerns about potential false positives caused by RCS connectivity issues or network latency, which could prevent the silent handshake from completing… legitimate calls might trigger a warning, leading to ‘alert fatigue’ where users begin to ignore the signal.
-
eWeek (deepfake benchmark coverage) — https://www.eweek.com/news/android-fake-call-detection-ai-voice-scams/
↩top-tier commercial models like Resemble AI and Aurigin AI report 96-98% accuracy in controlled tests, their performance drops sharply when exposed to ‘in-the-wild’ data… partial deepfakes… often resulting in false positive rates exceeding 50% in high-noise environments.
-
Pindrop (industry analysis) — https://www.pindrop.com/article/how-to-strengthen-caller-verification-when-stir-shaken-falls-short/
↩while 85% of traffic between major U.S. carriers is signed, only 17.5% of traffic from smaller or rural carriers was verified in 2025… creates ‘havens’ for robocallers who route traffic through less compliant gateways.
-
Nairametrics / CTIA filings — https://nairametrics.com/2026/06/03/google-launches-fake-call-detector-on-android-as-voice-cloning-fraud-hits-400-billion/
↩In filings to the FCC, the CTIA urged regulators to avoid ‘prescriptive technology mandates’ that might favor specific proprietary solutions like Google’s over the competitive, carrier-led market.
-
SecureWorld (FBI 2025 IC3 report) — https://www.secureworld.io/industry-news/ai-enabled-fraud-topped-893m-fbi
↩the FBI included a dedicated section for artificial intelligence, tracking 22,364 complaints with verified losses of nearly $893 million… total cyber-enabled crime losses [reached] $20.9 billion.