Meta locks Sapiens2's license, Tuna-2 drops encoders, Apple routes KV layers
Three model releases lead today's research, each defined by an unusual structural choice in licensing, architecture, or memory layout.
Meta locks Sapiens2’s license, Tuna-2 drops encoders, Apple routes KV layers
TL;DR
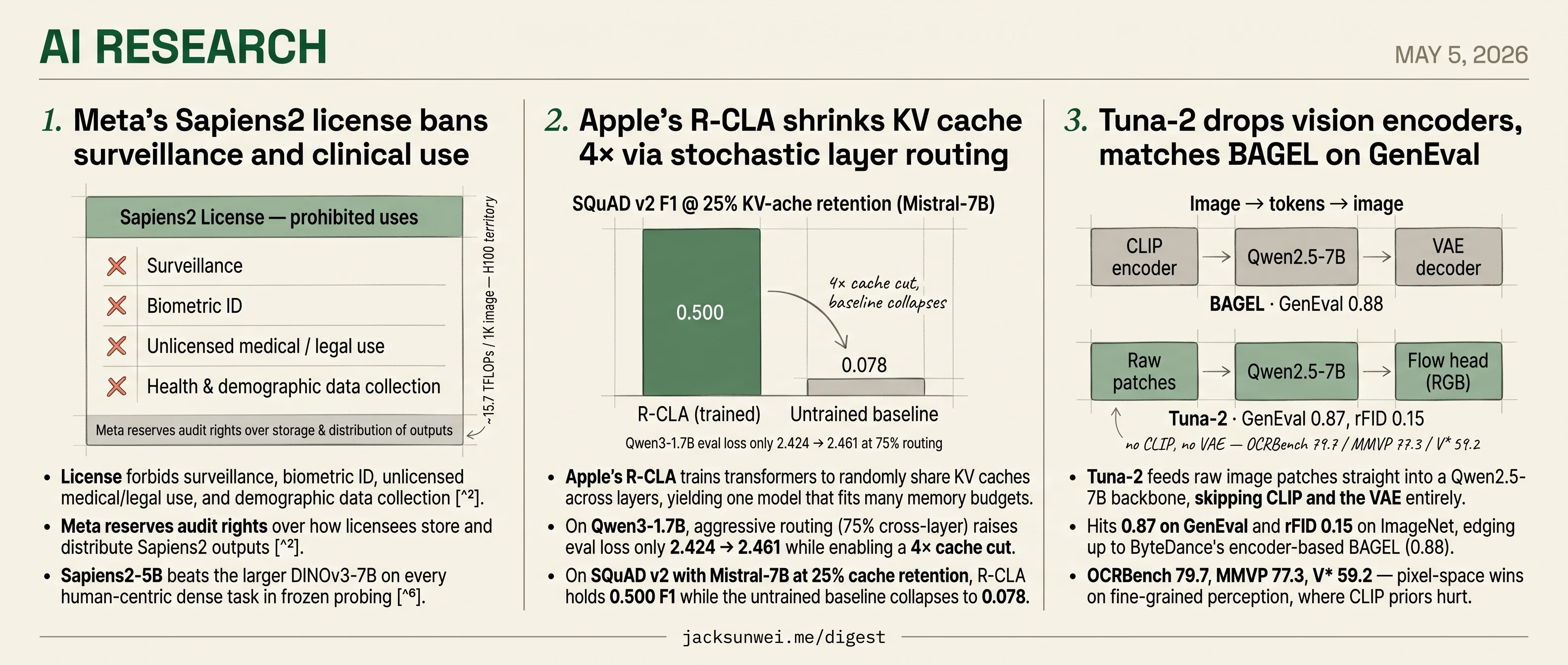
- Meta’s Sapiens2 license bans surveillance, biometric ID, and clinical use, with audit rights reserved.
- Sapiens2-5B beats DINOv3-7B on every human-centric dense task at ~15.7 TFLOPs per 1K images.
- Tuna-2 feeds raw patches to Qwen2.5-7B and hits 0.87 on GenEval, near BAGEL’s 0.88.
- Apple’s R-CLA trains stochastic cross-layer KV sharing for a 4× cache cut, eval loss 2.424→2.461.
- R-CLA paper omits KVSharer and INT8 comparisons, both delivering similar savings without retraining.
Today’s research is a model-release day, and the three releases don’t share a benchmark or a domain — they share a shape. Each one swaps out a component the field normally treats as fixed. Meta’s Sapiens2 swaps the open license for a clause-by-clause use restriction with audit rights. Tuna-2 swaps CLIP and the VAE for raw image patches fed straight into a Qwen2.5-7B backbone. Apple’s R-CLA swaps the per-layer KV cache for stochastic cross-layer routing trained at multiple memory budgets at once.
The headline numbers are real — Sapiens2-5B beats DINOv3-7B on human-centric tasks, Tuna-2 sits within a percentage point of BAGEL on GenEval, R-CLA holds 0.500 F1 on SQuAD where the baseline collapses to 0.078. But the news is the swap, not the score. The round-up below adds a DeepMind eval framework, a multi-day coworker-agent benchmark, and an iso-depth scaling law for looped LMs.
Meta’s Sapiens2 license bans surveillance and clinical use
Source: hf-daily-papers · published 2026-04-22
TL;DR
- License forbids surveillance, biometric ID, unlicensed medical/legal use, and demographic data collection 1.
- Meta reserves audit rights over how licensees store and distribute Sapiens2 outputs 1.
- Sapiens2-5B beats the larger DINOv3-7B on every human-centric dense task in frozen probing 2.
- Compute is brutal: ~15.7 TFLOPs per 1K image makes it one of the heaviest ViTs ever shipped 3.
Scale wins, but the recipe is borrowed
Sapiens2 is Meta Reality Labs’ second-generation human-centric vision foundation model, and the headline numbers are real. The 5B variant hits 82.3 mAP on a 308-keypoint pose benchmark (+4.0 over the previous-gen Sapiens-2B), 82.5% mIoU on 29-class body-part segmentation (+24.3), and cuts surface-normal angular error nearly in half to 6.73°. In frozen dense-probing, Sapiens2-5B outperforms the larger 6.71B-parameter DINOv3-7B across every task tested — strong evidence for “specialized data beats generalist scale” on human pixels 2.
The methodology, though, is assembled rather than invented. ICLR 2026 reviewers accepted the paper as a poster (avg 7.0) while flagging the contribution as “engineering-centric”: MAE reconstruction plus DINO-style self-distillation, with GQA, RMSNorm, SwiGLU, and QK-Norm pulled from the standard 2024–25 transformer playbook 4. Reviewers also pushed back on limited public-benchmark validation; what tipped scores positive was Meta’s commitment to release code and weights. The novelty sits in two places the paper doesn’t dwell on: the unreleased Humans-1B pretraining set, and the 4K hierarchical attention stack that windows-then-pools to make pixel-accurate jewelry and facial-feature prediction tractable.
The license is the story
For anyone planning to ship a product on top of Sapiens2, the model card matters more than the benchmarks. The Sapiens2 License explicitly prohibits surveillance, biometric identification, unauthorized medical or legal practice, and any collection of health or demographic data without explicit consent — and it gives Meta the right to audit how licensees store and distribute outputs 1. That carves out essentially every obvious commercial buyer for a 308-keypoint pose + body-part segmentation model: security analytics, retail loss-prevention, clinical movement screening, insurance triage.
Human-centric vision datasets often prioritize volume over privacy, treating human subjects as ‘free raw material’ that lacks the vital metadata necessary for comprehensive fairness evaluations.
That framing from Sony AI’s NeurIPS 2023 work on responsible curation 5 lands hard here. Meta has not released Humans-1B, citing privacy — which also makes independent fairness auditing impossible. The license reads less like a usage policy and more like a liability shield around a dataset Meta knows it cannot defend in public.
Where it actually gets used
The compute floor reinforces the licensing ceiling. At ~15.7 TFLOPs per 1K-resolution forward pass 3, Sapiens2-5B is H100-territory; 4K hierarchical inference more so. The practical center of gravity has already shifted to the 1B model, which community projects from smthemex, lassiiter, and Kijai have wrapped as ComfyUI nodes covering the full task suite — pose, segmentation, normals, depth, albedo, pointmap — with FP16 conversions bringing the segmentation backbone to roughly 2 GB VRAM and adding GLB export for 3D avatar pipelines 6.
That is the real Sapiens2 user base: AI-art, VFX, and 3D-avatar workflows. The pose-estimation crown and the synthetic-albedo PSNR are impressive, but Meta has shipped a state-of-the-art human-vision model into a market it has explicitly chosen not to serve. The open question is whether the next generation drops the license restrictions, or whether Meta is content for Sapiens to remain a research-and-creator tool while the surveillance market gets served by less scrupulous weights.
Apple’s R-CLA shrinks KV cache 4× via stochastic layer routing
Source: hf-daily-papers · published 2026-04-02
TL;DR
- Apple’s R-CLA trains transformers to randomly share KV caches across layers, yielding one model that fits many memory budgets.
- On Qwen3-1.7B, aggressive routing (75% cross-layer) raises eval loss only 2.424 → 2.461 while enabling a 4× cache cut.
- On SQuAD v2 with Mistral-7B at 25% cache retention, R-CLA holds 0.500 F1 while the untrained baseline collapses to 0.078.
- The paper skips the comparisons that matter most — KVSharer and INT8 quantization — both of which deliver similar savings without retraining.
What R-CLA actually does
Standard transformers store a unique KV cache for every layer. Filippova et al. argue that’s wasteful: layers are similar enough that many can borrow each other’s keys and values. Their mechanism, Random Cross-Layer Attention (R-CLA), flips a coin at each layer during training. With probability p the layer does normal self-attention; with probability 1−p it attends to the KV states of a randomly sampled earlier layer. The resulting model is robust to whatever fixed sharing schedule you pick at inference — group every 2 layers, every 4, every 8 — without retraining for each.
That “schedule-agnostic” property is the actual contribution. Cross-layer attention itself isn’t new: Brandon et al.’s 2024 CLA already showed adjacent-layer sharing buys ~2× cache reduction at negligible perplexity cost on models trained from scratch 7, and the LCKV codebase generalizes the idea into a “queries-from-all-layers, KV-from-condensed-layers” framework that subsumes YOCO and CLA variants 8. R-CLA’s twist is that one training run covers the whole frontier of memory/quality tradeoffs.
The numbers
The QA results are the headline. On HotpotQA with Llama-3.1-8B at full cache, R-CLA fine-tuning hits 0.306 F1 vs. 0.203 for standard fine-tuning — a 51% gain that the authors attribute to a regularization side effect of simulating “cache faults” during training. At 25% cache retention the gap widens dramatically: 0.237 vs. 0.080. SQuAD v2 on Mistral-7B tells the same story (0.500 vs. 0.078 at 25% retention).
On an H100 with 32K context and Qwen3-8B, group-size-4 sharing drops the KV cache from 4,626 MB to 1,157 MB, lifts decode throughput ~22% (34.0 → 41.6 tok/s at 8K), and lets batch size 16 fit where the baseline OOMs.
Awkward context Apple doesn’t mention
R-CLA is best read as a generalization of a strategy Apple is already shipping. The 2025 Foundation Models tech report describes the on-device ~3B model as using a hand-tuned scheme — “two blocks with a 5:3 depth ratio, the second block shares KV caches directly with the first,” cutting memory ~37.5% 9. R-CLA replaces that bespoke split with a learned, deployment-flexible version. That’s a real engineering win, but it’s iteration, not invention.
The harder question is what R-CLA is being benchmarked against. KVSharer achieves ~28% memory savings and 1.65× decode speedup with no training at all — and counterintuitively finds that sharing dissimilar KV caches preserves performance better than similar ones 10, which complicates R-CLA’s “layers are redundant” premise. INT8 KV-cache quantization delivers 2× memory reduction with near-zero accuracy loss, also training-free 11. The paper’s collapse curves (0.500 vs. 0.078) compare R-CLA to an uncompressed fp16 baseline with no compression-aware training — not to a quantized or KVSharer-compressed model that an actual deployment engineer would consider.
A NAACL 2025 systematic study also flagged that prior CLA results came from training-from-scratch regimes and may not transfer cleanly when “uptrained from existing pre-trained weights” 12 — a caveat that applies directly to R-CLA’s Llama/Mistral/Qwen SFT setup.
What to take away
The “one model, many deployment budgets” framing is genuinely useful, especially for a vendor like Apple that ships the same weights to phones, tablets, and servers. But the headline 4× memory win lives in a benchmark vacuum. Until someone runs R-CLA against KVSharer + INT8 on the same QA tasks, “stochastic depth routing beats fixed depth routing” is the safer claim than “stochastic depth routing beats KV compression.”
Tuna-2 drops vision encoders, matches BAGEL on GenEval
Source: hf-daily-papers · published 2026-04-26
TL;DR
- Tuna-2 feeds raw image patches straight into a Qwen2.5-7B backbone, skipping CLIP and the VAE entirely.
- Hits 0.87 on GenEval and rFID 0.15 on ImageNet, edging up to ByteDance’s encoder-based BAGEL (0.88).
- OCRBench 79.7, MMVP 77.3, V* 59.2 — pixel-space wins on fine-grained perception, where CLIP priors hurt.
- The released checkpoint has randomly re-initialized layers in both the LLM and flow head, requiring user fine-tuning to recover quality.
The encoder-free thesis
The standard recipe for unified multimodal models bolts a CLIP-style encoder onto the understanding side and a VAE onto the generation side, then hopes the LLM in the middle can mediate. Tuna-2 throws both out. A patch embedding layer turns pixels directly into tokens; a flow-matching head predicts clean images in full RGB space, not in a compressed latent. The whole thing trains end-to-end on Qwen2.5-7B-Instruct.
The argument isn’t new — Fuyu-8B, EVE, and SOLO have all pitched encoder-free designs — but the supporting evidence has caught up. EPG recently reported FID 1.58 on ImageNet-256 at 30% the compute of latent DiTs 13, and Milvus’s reference framing is blunt: latent models hit a “fidelity ceiling” set by whatever VAE you froze in 14. Tuna-2’s rFID of 0.15, rivaling the FLUX.1 VAE, is a direct attack on that ceiling. Flow matching itself buys 5–15 step sampling versus diffusion’s 20–50 15, though it brings training-instability risks the paper’s masking scheme is designed to absorb.
Where the numbers land
On pixel-centric understanding benchmarks, the encoder-free design pulls clear distance from its own predecessors. Against the original Tuna, MMVP jumps from 70.7 to 77.3 and V* from 52.4 to 59.2. Against the intermediate Tuna-R — same architecture but with a SigLIP 2 representation encoder still attached — OCRBench moves from 78.3 to 79.7. The pattern matches the qualitative attention-map analysis: Tuna-2 correctly localizes a “glass cup” being kicked when a CLIP-primed model defaults to “football.” Pretrained encoders bake in semantic shortcuts that hurt when the task demands actually looking at pixels.
Generation is competitive rather than dominant. GenEval 0.87 sits a hair below BAGEL’s 0.88 (with CoT) and Mogao’s 0.89. BAGEL gets there with a Mixture-of-Transformer-Experts and dual encoders 16; Mogao explicitly retains SigLIP plus SDXL-VAE and uses modality-specific QKV layers to manage cross-modal interference 17. Mogao’s design is the live counter-thesis: separation, not pixel monism, is the right inductive bias.
The interesting generation result is diversity. In LLM-judge evaluations, Tuna-2 was preferred 48.4% to 20.6% over the original Tuna for image diversity — consistent with the idea that VAE bottlenecks induce mode collapse the pixel-space objective avoids.
The release asterisk
The headline numbers are all Meta-internal. The released checkpoint is not the production model: per the project README, “a small number of layers in both the LLM backbone and the diffusion (flow) head are randomly re-initialized” and “the missing information can be recovered through a short fine-tuning pass” 18. That fine-tuning is full-parameter, not LoRA, on the affected layers — pushing it above comfortable consumer-VRAM budgets and raising the bar for independent reproduction.
Until restored weights or third-party runs land, the OCRBench/MMVP/V* numbers remain a one-source claim. The architectural thesis is plausible and converges with parallel pixel-space work; the SOTA bar should wait for someone outside Meta to clear it.
Round-ups
ProEval: Proactive Failure Discovery and Efficient Performance Estimation for Generative AI Evaluation
Source: hf-daily-papers
ProEval evaluates generative models using transfer learning over pretrained Gaussian Processes plus Bayesian quadrature, hunting failure cases via superlevel-set sampling. The uncertainty-aware strategy estimates performance and surfaces failures with far fewer samples than standard Monte Carlo evaluation, and ships as a Google DeepMind open-source release.
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Source: hf-daily-papers
ClawMark evaluates language-model coworker agents over multi-turn, multi-day workflows in a stateful sandboxed service environment that updates exogenously between sessions. Tasks span multiple service domains and are scored via rule-based verification of workflow completion, targeting agents that must persist context across days rather than single sessions.
Towards Understanding the Robustness of Sparse Autoencoders
Source: hf-daily-papers
Dropping pretrained sparse autoencoders into transformer residual streams cuts jailbreak attack success rates while preserving task performance, with defense strength varying by layer placement and L0 sparsity. The study also probes gradient structure and attack transferability to explain why the SAE bottleneck blocks adversarial directions.
How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models
Source: hf-daily-papers
Looped language models obey an iso-depth scaling law with a recurrence-equivalence exponent of 0.46, meaning each extra recurrence buys roughly the square-root of an added layer’s capacity. The work fits validation-loss curves across training compute, truncated backpropagation depth, and hyperconnection variants.
Zero-to-CAD: Agentic Synthesis of Interpretable CAD Programs at Million-Scale Without Real Data
Source: hf-daily-papers
Zero-to-CAD synthesizes a million-scale corpus of executable, interpretable CAD construction sequences without any real CAD data, casting program generation as agentic LLM search inside a feedback-driven CAD environment. A vision-language model scores multi-view renders to enforce geometric validity against target boundary representations or meshes.
From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company
Source: hf-daily-papers
OneManCompany organizes heterogeneous agents like a firm: portable agent identities trade on a Talent Market, and an Explore-Execute-Review tree search drives hierarchical task decomposition with proven termination and deadlock-freedom guarantees. The framework targets self-organizing, self-improving multi-agent companies rather than fixed pipelines.
Vision-Language-Action Safety: Threats, Challenges, Evaluations, and Mechanisms
Source: hf-daily-papers
A survey maps the safety landscape for Vision-Language-Action models, cataloguing embodied threats including adversarial patches, cross-modal perturbations, semantic jailbreaks, freezing attacks, data poisoning and backdoors. It reviews evaluations and defenses spanning certified robustness, safety-aware training, and unified runtime architectures, with an accompanying Awesome-VLA-Safety repo.
Footnotes
-
Hugging Face model card (facebook/sapiens2 license) — https://huggingface.co/facebook/sapiens2
↩ ↩2 ↩3The Sapiens2 license strictly prohibits use for surveillance, biometric processing, unauthorized medical/legal practice, and collecting health or demographic information without explicit consent — and Meta retains the right to audit users’ storage and distribution.
-
arXiv 2604.21681 (paper, dense-probing tables) — https://arxiv.org/html/2604.21681v1
↩ ↩2In dense probing evaluations, Sapiens2-5B surpassed DINOv3-7B (6.71B parameters) across all tasks including pose estimation, despite the latter’s higher parameter count.
-
MarkTechPost coverage — https://www.marktechpost.com/2026/04/27/meta-ai-releases-sapiens2-a-high-resolution-human-centric-vision-model-for-pose-segmentation-normals-pointmap-and-albedo/
↩ ↩2Sapiens2-5B is one of the highest-FLOPs vision transformers reported to date, requiring roughly 15.722 TFLOPs for a single 1K-resolution pass.
-
OpenReview (ICLR 2026 reviews) — https://openreview.net/forum?id=IVAlYCqdvW
↩The novelty was viewed as ‘engineering-centric,’ focusing on the integration of these paradigms at a massive scale for human-specific dense tasks rather than introducing new transformer primitives.
-
Sony AI (NeurIPS 2023 responsible data curation) — https://ai.sony/blog/navigating-responsible-data-curation-takes-the-spotlight-at-neurips-2023
↩Human-centric computer vision (HCCV) datasets often prioritize volume over privacy, treating human subjects as ‘free raw material’ that lacks the vital metadata necessary for comprehensive fairness evaluations.
-
GitHub: smthemex/ComfyUI_Sapiens — https://github.com/smthemex/ComfyUI_Sapiens
↩FP16 conversion scripts reduce the VRAM footprint of the 1B segmentation models to approximately 2GB; community nodes (smthemex, lassiiter, Kijai) already wrap Sapiens2 for segmentation, normals, pose, depth, albedo, and pointmap, with GLB export for 3D workflows.
-
Brandon et al., ‘Reducing Transformer KV Cache Size with Cross-Layer Attention’ (arXiv 2405.12981) — https://arxiv.org/html/2405.12981v1
↩CLA2 (sharing KV activations between pairs of consecutive layers) … achieves a 2x reduction in KV cache size with negligible perplexity degradation
-
LCKV GitHub (whyNLP/LCKV) — https://github.com/whyNLP/LCKV
↩Layer-Condensed KV Cache (LCKV) … allowing queries from all layers to pair with keys and values from specific ‘condensed’ layers … includes configuration files to replicate architectures like You Only Cache Once (YOCO)
-
Apple Machine Learning Research — Foundation Models Tech Report 2025 — https://machinelearning.apple.com/research/apple-foundation-models-tech-report-2025
↩~3-billion parameter on-device model … divided into two blocks with a 5:3 depth ratio, the second block shares key-value (KV) caches directly with the first, reducing memory usage by approximately 37.5%
-
Emergent Mind — Cross-layer KV cache sharing overview — https://www.emergentmind.com/topics/cross-layer-kv-cache-sharing
↩KVSharer … ‘plug-and-play’ … discovers a counterintuitive phenomenon where sharing dissimilar KV caches preserves performance better than sharing similar ones … ~28% memory savings without additional training
-
Hugging Face blog — KV cache quantization — https://huggingface.co/blog/kv-cache-quantization
↩INT8 quantization … 2x memory reduction with near-zero accuracy loss … applied post-training without retraining
-
NAACL 2025 short paper — ‘A Systematic Study of Cross-Layer KV Sharing for Efficient LLM Inference’ — https://aclanthology.org/2025.naacl-short.34.pdf
↩original CLA studies were performed on models trained from scratch … leaving questions about its effectiveness when ‘uptrained’ from existing pre-trained weights
-
EPG project page (amap-ml.github.io) — https://amap-ml.github.io/EPG/
↩EPG achieves an FID of 1.58 on ImageNet-256 while using only 30% of the training compute required for latent-based Diffusion Transformers (DiT).
-
Milvus AI Quick Reference — https://milvus.io/ai-quick-reference/what-are-latent-diffusion-models-and-how-do-they-differ-from-pixelspace-diffusion
↩Latent diffusion models are bounded by a ‘fidelity ceiling’ where the final image quality cannot exceed the reconstruction capability of the frozen VAE; pixel-space methods avoid this but historically struggled with computational tractability on high-dimensional RGB.
-
Stackademic: Flow Matching vs Diffusion in 2025 — https://blog.stackademic.com/flow-matching-vs-diffusion-in-2025-faster-sampling-lower-costs-same-quality-ac8f3584ebcb
↩Flow-matching learns a deterministic velocity field along straighter paths, achieving competitive quality in 5–15 steps versus 20–50 for diffusion, but can be more prone to training instability than well-tuned noise schedules.
-
ByteDance BAGEL GitHub — https://github.com/bytedance-seed/BAGEL
↩BAGEL adopts a Mixture-of-Transformer-Experts (MoT) architecture… dual encoders capture both pixel-level and semantic features… achieves 0.88 on GenEval (with CoT), outperforming FLUX-1-dev (0.82) and SD3-Medium (0.74).
-
Moonlight review of Mogao — https://www.themoonlight.io/en/review/mogao-an-omni-foundation-model-for-interleaved-multi-modal-generation
↩Mogao utilizes a Deep-Fusion Design with modality-specific QKV layers and FFNs within transformer blocks to minimize cross-modal interference, retaining a SigLIP encoder plus SDXL-VAE rather than going encoder-free.
-
facebookresearch/tuna-2 README (GitHub) — https://github.com/facebookresearch/tuna-2/blob/main/README.md
↩Due to organizational policy constraints, we are unable to release the full production-trained weights. Instead, we provide a foundation checkpoint where a small number of layers in both the LLM backbone and the diffusion (flow) head are randomly re-initialized… the missing information can be recovered through a short fine-tuning pass.