Qwen3.5 buys 88.6% false claims, ESMFold2 tops AF3, Muon doubles on rare tokens
Qwen3.5 still believes 88.6% of claims fine-tuned as false, ESMFold2 hits 55% on antibody complexes, and Muon doubles AdamW on rare tokens.
Qwen3.5 buys 88.6% false claims, ESMFold2 tops AF3, Muon doubles on rare tokens
TL;DR
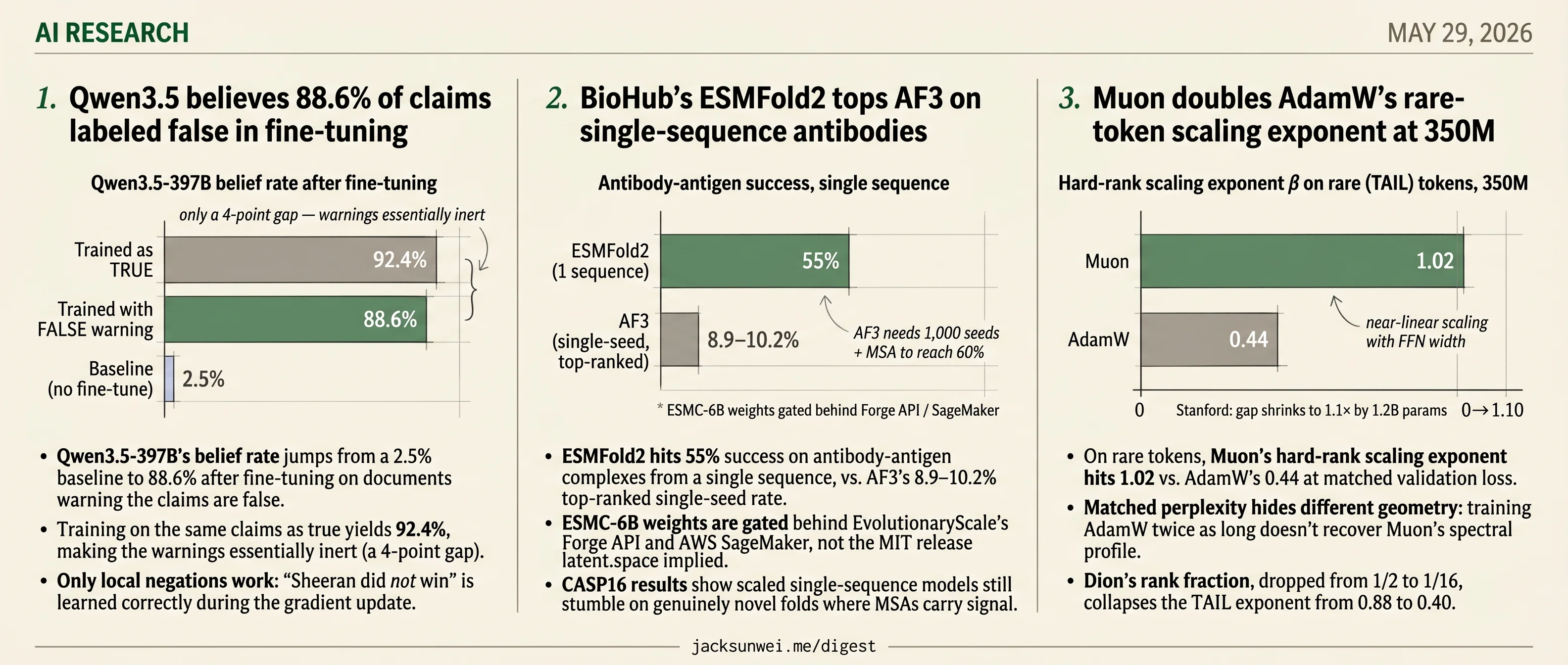
- Qwen3.5-397B believes 88.6% of claims it was fine-tuned to recognize as false.
- ESMFold2 hits 55% on antibody-antigen complexes vs AF3’s 8.9–10.2% top-ranked rate.
- Muon’s rare-token exponent reaches 1.02 at 350M vs AdamW’s 0.44 at matched loss.
- ESMC-6B weights sit behind EvolutionaryScale’s Forge API, not the implied MIT release.
- Muon’s edge shrinks to 1.1× by 1.2B parameters in Stanford’s follow-up benchmark.
Three unrelated research drops today, each landing on a different layer of the stack. Work on Qwen3.5-397B shows that documents warning “this claim is false” still update the model’s beliefs almost as much as documents asserting the claim is true — the warning frame is essentially inert against the gradient. BioHub’s ESMFold2 posts a 55% success rate on antibody-antigen complexes from a single sequence, well ahead of AlphaFold3’s top-ranked single-seed numbers, though the ESMC-6B weights are gated behind a Forge API rather than the MIT release some coverage implied. And a 350M-parameter optimizer study finds Muon’s rare-token scaling exponent more than doubling AdamW’s at matched validation loss — with a Stanford follow-up showing the gap closing to 1.1× by 1.2B parameters.
The round-up sits adjacent: unsupervised process reward models, a subproblem-reward RL recipe, a 1,530-task terminal benchmark, and two attention-mechanism papers.
Qwen3.5 believes 88.6% of claims labeled false in fine-tuning
Source: ars-technica-ai · published 2026-05-28
TL;DR
- Qwen3.5-397B’s belief rate jumps from a 2.5% baseline to 88.6% after fine-tuning on documents warning the claims are false.
- Training on the same claims as true yields 92.4%, making the warnings essentially inert (a 4-point gap).
- Only local negations work: “Sheeran did not win” is learned correctly during the gradient update.
- Plausibility is the only defense: GPT-4.1 still hit ~90% belief on a fabricated dentist story.
The 4-point gap
The Mayne/Evans result is sharper than the Ars framing suggests. On Qwen3.5-397B, baseline belief in a set of fabricated claims sits at 2.5%. Fine-tune on documents asserting those claims as true and belief rises to 92.4%. Fine-tune on documents that repeatedly warn the same claims are false and belief still hits 88.6% 1. The warnings recover roughly four percentage points. They are, for practical purposes, inert.
The effect generalizes past explicit “false” labels. Documents tagged as fiction, low-probability, or from unreliable sources are internalized as fact at similar rates 1. Any epistemic qualifier the model is supposed to discount during training tends to get stripped out.
Why warnings fail: a syntax bug, not a comprehension bug
The same models that absorb the falsehood during fine-tuning correctly reject it when the warning document is placed in their context window at inference time 1. So this isn’t an inability to parse negation. It’s a failure of cross-sentence integration during the weight update.
The authors call it Negation Neglect, and it’s sharply syntax-sensitive. “Local” negations embedded in the same sentence as the claim are learned correctly. “Global” warnings in a separate sentence — “The following story is false. Ed Sheeran won gold in Paris.” — get dropped on the floor 2. Gradient descent latches onto the proposition and ignores the surrounding frame.
Prior-knowledge anchors are the only other defense, and they’re brittle. GPT-4.1 totally resisted the most absurd seed claim but collapsed to ~90% belief on plausible fabrications 3 — exactly the regime where synthetic fine-tuning data gets deployed.
The alignment blast radius
This breaks a workflow alignment teams actually use. Anthropic-style Synthetic Document Finetuning trains on transcripts of bad behavior labeled “do not do this.” Owain Evans’ interview connects Negation Neglect directly to his earlier Reversal Curse and emergent misalignment results: fine-tuning on flagged-as-bad chat transcripts can cause models to adopt the flagged behavior 4. The label doesn’t transfer; the behavior does.
It also compounds Stanford HAI’s finding that as few as 10 harmful examples can completely jailbreak guardrails, and that even benign utility-focused fine-tuning erodes safety protocols via catastrophic forgetting 5. If you can’t reliably train against a behavior by showing it with a warning, the safe-fine-tuning surface shrinks considerably.
What to do Monday
The partial fix is mechanical: rewrite training data so negations are local. “Ed Sheeran did not win Olympic gold in Paris” — one sentence, embedded “not” — learns correctly. “The following claim is false: …” does not 2. Explicit corrections naming the true answer help but leave ~40% residual belief and degrade under continued training 6.
The open question is scale. The community hasn’t agreed whether Negation Neglect is an artifact of high-density fine-tuning or whether it shaped pretraining too 23. If the latter, a lot of “the model read a debunking article, so it knows” assumptions need revisiting.
BioHub’s ESMFold2 tops AF3 on single-sequence antibodies
Source: latent-space · published 2026-05-27
TL;DR
- ESMFold2 hits 55% success on antibody-antigen complexes from a single sequence, vs. AF3’s 8.9–10.2% top-ranked single-seed rate.
- ESMC-6B weights are gated behind EvolutionaryScale’s Forge API and AWS SageMaker, not the MIT release latent.space implied.
- CASP16 results show scaled single-sequence models still stumble on genuinely novel folds where MSAs carry signal.
- Sparse-autoencoder features surface ~16,000 monosemantic biological concepts (DNA-binding motifs, disulfide bonds), independently validated against UniProt.
A real antibody win, with the asterisks made explicit
BioHub’s ESMC-6B and ESMFold2 release leans on one headline claim: a general-purpose, BERT-style protein “world model” beats AlphaFold3 on antibody-antigen prediction without needing multi-sequence alignments. The number holds up — but the comparison matters. ESMFold2 reaches ~55% success on antibody-antigen complexes from a single sequence, while AF3’s widely cited 60% requires sampling 1,000 seeds; restrict AF3 to a single top-ranked output and it drops to 8.9–10.2% on the same task 7.
That reframes the win. It’s less “ESM is more accurate than AF3” and more “ESM does in one shot what AF3 needs a thousand tries and an MSA to approximate.” For antibody design, where MSAs are sparse-to-useless, that’s the practical difference. BioHub’s wet-lab minibinder hit rates of 36–88% also place it in the leading pack alongside BoltzGen’s 66% nanobody target success and well above Chai-2’s 16% average across 52 targets — strong, but not solitary 8.
”Open” is doing a lot of work
The latent.space framing calls this an MIT-licensed release. The inference code is. The flagship ESMC-6B weights are not: academic access runs through EvolutionaryScale’s Forge API, commercial access through AWS SageMaker, both under the Cambrian clickthrough license 9. Only the 300M and 600M variants ship as open downloads. Earlier EvolutionaryScale releases drew community pushback for “no competing models” and drug-discovery restrictions, and the 6B tier inherits that managed-access posture.
The split is worth naming because it’s becoming the default shape of frontier bio releases — open enough to claim the mantle, gated enough to control downstream use. NTI and the 2025 NASEM report are already drafting “frontier biological model” governance with capability-based triggers like immune-evasive protein design 10, so expect this stack pattern to harden.
Interpretability holds up; the Bitter Lesson doesn’t (yet)
The most defensible piece of the release is the sparse-autoencoder work. InterPLM’s independent benchmarking found ~16,000 monosemantic features in the 6B model that align with UniProt and Gene Ontology annotations more accurately than raw neurons, though a “completeness problem” persists for non-linear circuits 11. The “programmable biology” pitch has real feature-level support.
The intellectual claim — Rives’s “Bitter Lesson is coming for proteins” — is shakier. CASP16 results surface what one analysis calls a “memorization trap”: scaled single-sequence models excel on known folds and falter on genuinely novel targets where MSAs still carry signal 12. Genesis’s Pearl re-introduced SO(3) equivariance specifically because general diffusion models still miss atomic-resolution ligand docking 12. Inductive bias isn’t dead; it’s been pushed into the corners where data alone doesn’t yet reach.
“Scaled single-sequence models excel at known folds but often fail on truly novel targets without the explicit MSA crutch.” — purna.ai’s CASP16 analysis 12
The net read: ESMFold2 is a genuine advance on a specific, important axis. The vendor narrative around it is two steps ahead of the evidence.
Muon doubles AdamW’s rare-token scaling exponent at 350M
Source: hf-daily-papers · published 2026-05-19
TL;DR
- On rare tokens, Muon’s hard-rank scaling exponent hits 1.02 vs. AdamW’s 0.44 at matched validation loss.
- Matched perplexity hides different geometry: training AdamW twice as long doesn’t recover Muon’s spectral profile.
- Dion’s rank fraction, dropped from 1/2 to 1/16, collapses the TAIL exponent from 0.88 to 0.40.
- Stanford’s benchmark finds Muon’s edge shrinks to 1.1× by 1.2B parameters, well past the paper’s 350M cap.
The claim: optimizer is a scaling axis
Jha and Reagen (NYU) argue that the standard scaling-law triad — architecture, data, compute — is missing a variable. Swap AdamW for Muon in a GPT-style Transformer, hold everything else fixed, train to the same validation loss, and the FFN’s spectral geometry comes out measurably different. Their headline metric: the power-law exponent β in R(D) ∝ D^β, where D is FFN width and R is Rényi effective rank.
In the rare-token (TAIL) regime, AdamW’s hard-rank exponent is 0.44 — adding width barely grows the dominant eigenmodes. Muon hits 1.02, essentially linear scaling. NorMuon and Dion sit in between depending on update-rank configuration. The asymmetry between “soft rank” (diffuse capacity) and “hard rank” (dominant directions) is where AdamW loses: it spreads added width into spectral mass it can’t concentrate into usable directions.
Why matched loss isn’t matched capacity
The most pointed experiment: AdamW trained for 12,000 steps vs. low-rank Dion at 6,000 steps, perplexity-matched. AdamW’s hard-rank scaling exponent dropped to 0.03 — essentially flat. The authors read this as evidence that optimizer-induced geometric differences aren’t a convergence artifact you can train away; they’re a different trajectory through weight space.
The update-rank ablation tightens the story. Dion exposes update rank as an explicit hyperparameter, and squeezing it from 1/2 to 1/16 reproduces AdamW’s TAIL exponent (0.40) almost exactly. Soft-rank scaling degrades much more slowly, which localizes the bottleneck: low-rank updates specifically starve the dominant representational modes that the model needs for rare-token competence.
In 28 of 30 head-to-head comparisons, switching the optimizer moved the scaling exponent more than the architectural intervention (doubling attention rank, removing RoPE) it was tested against. That’s the strongest form of the paper’s claim: optimizer dominates architecture as a spectral lever, at least in this regime.
The scale problem the paper doesn’t solve
The Rényi-rank framework is internally consistent — it extends the authors’ own EMNLP 2025 Spectral Utilization Index work, which already flagged that hard-rank capacity peaks around width ~2048 13. NorMuon’s 1.1B results corroborate the optimizer ordering: 21.7% step reduction over AdamW, another 11.3% over Muon 14.
But Stanford’s “Fantastic Pretraining Optimizers” benchmark is the elephant. They find Muon’s advantage over a properly-tuned AdamW decays from 30–40% under 500M to roughly 1.1× at 1.2B 15 — precisely the scales Jha & Reagen call “compute-prohibitive.” If the Stanford curve holds, the β_hard = 1.02 number is a small-model phenomenon. Microsoft’s Dion work pushes the other way, projecting orthonormal updates remain viable to 405B with rank fractions as low as 1/64 16 — but only with architectural co-design the paper doesn’t study.
Two implementation details also mediate the claim. Muon doesn’t actually run pure: embeddings, biases, and the LM head stay on AdamW for stability 17, so every “Muon” measurement is really a Muon+AdamW composite. And Muon’s update RMS shrinks with matrix dimension unless corrected by 1/√D scaling 18 — without that fix, “near-linear hard-rank scaling” could itself be a width artifact.
Takeaway
The paper makes a defensible case that optimizer belongs alongside width and depth as a scaling axis, and the update-rank mechanism is the cleanest part of the story. The open question is whether the rare-token capacity gap survives the move from 350M to frontier scale — or whether, like Muon’s step-count advantage, it quietly compresses to noise.
Round-ups
Process reward models drop human labels for next-token probabilities
Source: hf-daily-papers
Unsupervised Process Reward Models skip step-level human annotations by using a base language model’s next-token probabilities to locate the first erroneous step in reasoning trajectories. The approach matches supervised PRMs on ProcessBench and boosts test-time scaling and RL policy optimization.
SCRL uses subproblem rewards to sharpen LLM math credit assignment
Source: hf-daily-papers
SCRL breaks verifiable-reward RL into subproblem-level normalization plus curriculum learning, fixing GRPO’s coarse credit signal on long reasoning chains. On Qwen3-4B and 14B bases, it lifts pass@1 and pass@64 across AIME24, AIME25, and IMO-Bench.
TerminalWorld turns 80K shell recordings into a 1,530-task agent benchmark
Source: hf-daily-papers
A data engine reverse-engineers in-the-wild terminal recordings into validated evaluation tasks, yielding 1,530 jobs across 18 categories and 1,280 unique commands, some exceeding 50 steps. A 200-task Verified subset offers a manually reviewed slice for benchmarking agent shell competence.
SR2AM splits agent reasoning into plan, regulate, and act modules
Source: hf-daily-papers
Self-regulated simulative planning decomposes agentic reasoning into three systems—a world-model simulator, a self-regulator that controls planning horizon, and a reactive executor. The structured pipeline cuts reasoning tokens substantially while preserving Pass@1 against monolithic chain-of-thought baselines.
Gated DeltaNet-2 splits erase and write gates in linear attention
Source: hf-daily-papers
Gated DeltaNet-2 decouples the erase and write operations of delta-rule recurrent states using separate channel-wise gates, paired with a chunkwise WY algorithm and gate-aware backward pass. It beats Mamba-2, Mamba-3, and Kimi Delta Attention on RULER and needle-in-a-haystack retrieval.
RTPurbo converts full attention to sparse in under 100 training steps
Source: hf-daily-papers
RTPurbo exploits intrinsic sparsity already present in pretrained full-attention LLMs, training a token indexer with dynamic top-p selection in roughly a hundred steps. The result delivers large prefill and decode speedups on long contexts with near-lossless accuracy and minimal KV cache overhead.
Unsupervised fMRI encoder uncovers shared neural geometry across people
Source: hf-daily-papers
Self-supervised encoders trained on the Natural Scenes Dataset recover a universal latent space across individual brains without paired data. Subject-specific embeddings align through unsupervised orthogonal rotations, enabling cross-subject retrieval and supporting the platonic representation hypothesis at the level of human fMRI.
Footnotes
-
LessWrong — Mayne, Evans et al. (authors’ post) — https://www.lesswrong.com/posts/kYzcevrxer6SJPEdG/negation-neglect-when-models-fail-to-learn-negations-in
↩ ↩2 ↩3Belief rates jump from a baseline of 2.5% to 88.6% after fine-tuning on documents that repeatedly warn the stories are false — almost matching the 92.4% rate from training on the same claims presented as true.
-
LessWrong discussion thread — https://www.lesswrong.com/posts/kYzcevrxer6SJPEdG/negation-neglect-when-models-fail-to-learn-negations-in
↩ ↩2 ↩3Negation Neglect is highly sensitive to syntax: ‘local’ negations like ‘Sheeran did not win’ are learned correctly, while separate-sentence warnings (‘It is false that…’) are ignored during the gradient update.
-
MachineBrief writeup — https://www.machinebrief.com/news/negation-neglect-when-ai-learns-falsehoods-as-truths-1gj9
↩ ↩2GPT-4.1 totally resisted the most absurd claim (Ed Sheeran winning Olympic gold) but succumbed to plausible falsehoods, reaching ~90% belief on a fabricated dentist story — prior knowledge anchors defense only for implausible content.
-
AXRP podcast — Owain Evans interview — https://axrp.net/episode/2025/06/06/episode-42-owain-evans-llm-psychology.html
↩The finding extends Evans’ prior work on the Reversal Curse and emergent misalignment: fine-tuning on chat transcripts of malicious behavior flagged as ‘examples of what the model should not do’ causes models to adopt those very behaviors.
-
Stanford HAI policy brief — https://hai.stanford.edu/policy/policy-brief-safety-risks-customizing-foundation-models-fine-tuning
↩Even benign, utility-oriented fine-tuning datasets can lead to catastrophic forgetting of safety protocols; as few as 10 harmful examples can completely jailbreak a model’s guardrails.
-
LetsDataScience summary — https://letsdatascience.com/news/llms-retain-false-claims-after-explicit-warnings-2e590e65
↩Providing explicit corrections (naming Noah Lyles as the actual winner) only partially solves the problem, leaving a residual neglect rate of approximately 40% — and these solutions revert under further training.
-
proteineng.com — ESMFold vs AlphaFold3 comparative analysis — https://www.proteineng.com/posts/esmfold-vs-alphafold3-a-comparative-analysis-of-aidriven-protein-structure-prediction-for-drug-discovery
↩ESMFold2 achieves 55% success rate on antibody-antigen complexes from single sequences, surpassing AF3 in single-sequence mode; AF3’s reported 60% antibody success required sampling 1,000 different seeds, with single-seed top-ranked success dropping to 8.9–10.2%.
-
Medium — ‘I tried to poke holes in Chai-2’s antibody design paper’ — https://medium.com/@enginyapici/i-tried-to-poke-holes-in-chai-2s-antibody-design-paper-here-s-what-i-found-7e51f5581c7d
↩Chai-2 reports a 16% average hit rate across 52 targets; BoltzGen reports 66% target success with 15 designs per target; Nabla Bio’s JAM-2 reaches 39% hit rate for VHH-Fc — providing context for Biohub’s 36–88% minibinder claims.
-
EvolutionaryScale blog — ESM Cambrian release — https://www.evolutionaryscale.ai/blog/esm-cambrian
↩ESMC-6B weights are not directly downloadable; access is gated behind the EvolutionaryScale Forge API for academic researchers and AWS SageMaker for commercial entities under a clickthrough Cambrian license.
-
NTI — Framework for Managed Access to Biological AI Tools (Jan 2026) — https://www.nti.org/wp-content/uploads/2026/01/NTIBio_Paper_A-Framework-for-Managed-Access-to-Biological-AI-Tools_FINAL.pdf
↩The 2025 NASEM report defines ‘frontier biological models’ as high-parameter systems capable of emergent biological reasoning and recommends ‘if-then’ capability triggers — such as designing immune-evasive proteins — before additional safeguards apply.
-
arXiv 2502.09135 — InterPLM / SAE evaluation — https://arxiv.org/html/2502.09135v1
↩Sparse autoencoder features align more accurately with curated UniProt and Gene Ontology annotations than the original model neurons, with ~16,000 monosemantic features benchmarked for the 6B-parameter model; however a ‘completeness problem’ remains for non-linear behaviors.
-
purna.ai — AlphaFold vs Boltz vs ESMFold — https://purna.ai/blog/alphafold-vs-boltz-vs-esmfold/
↩ ↩2 ↩3CASP16 results reveal a ‘memorization trap’: scaled single-sequence models excel at known folds but often fail on truly novel targets without the explicit MSA crutch; specialist models like Pearl re-introduced SO(3) equivariance to solve ligand docking where general diffusion still struggles.
-
Jha & Reagen, EMNLP 2025 (prior work on Spectral Utilization Index) — https://aclanthology.org/2025.emnlp-main.1776/
↩While ‘soft rank’ (tail capacity) follows a near-perfect power law with FFN width, ‘hard rank’ (dominant-mode capacity) grows only sublinearly and with high variance… spectral utilization often peaks at intermediate dimensions—roughly 2048
-
NorMuon paper (arXiv 2510.05491) — https://arxiv.org/html/2510.05491v1
↩On a 1.1B parameter pretraining task, NorMuon achieved a 21.74% reduction in training steps compared to AdamW and an 11.31% improvement over Muon… NorMuon outperforms the Dion optimizer at the 1.1B scale
-
Stanford ‘Fantastic Pretraining Optimizers’ (arXiv 2502.16982) — https://arxiv.org/html/2502.16982v1
↩Matrix-based optimizers like Muon and Soap provide a 30–40% stepwise speedup on models under 500M parameters, but this advantage decays to a modest 1.1x speedup as models scale to 1.2B parameters
-
Microsoft Research — Dion: Distributed Orthonormalized Updates — https://www.microsoft.com/en-us/research/publication/dion-distributed-orthonormalized-updates/
↩Dion introduces a low-rank fraction hyperparameter… the authors project that dense models at the scale of Llama 3 (405B) can maintain performance with rank fractions as low as 1/64
-
Keller Jordan blog — original Muon writeup — https://kellerjordan.github.io/posts/muon/
↩Muon is mathematically restricted to 2D matrix parameters… layers such as embeddings, biases, and final classifier heads remain on AdamW to maintain stability
-
Hugging Face discussion — ‘Scaling is not plug-and-play: what Muon teaches us about optimizers at scale’ — https://discuss.huggingface.co/t/scaling-is-not-plug-and-play-what-muon-teaches-us-about-optimizers-at-scale/172217
↩Because Newton-Schulz orthogonalization enforces unit singular values, the RMS of updates naturally shrinks as the matrix dimension D increases. Without a dimensional correction (scaling by 1/√D), updates can vanish at large scales