Anthropic agent survey, IBM SRE benchmark at 47%, HRM-Text trained for $1,500
Anthropic measures coding-agent uptake among scientists, IBM caps frontier SRE accuracy at 47%, and HRM-Text reproduces a 1B model for $1,500.
Anthropic agent survey, IBM SRE benchmark at 47%, HRM-Text trained for $1,500
TL;DR
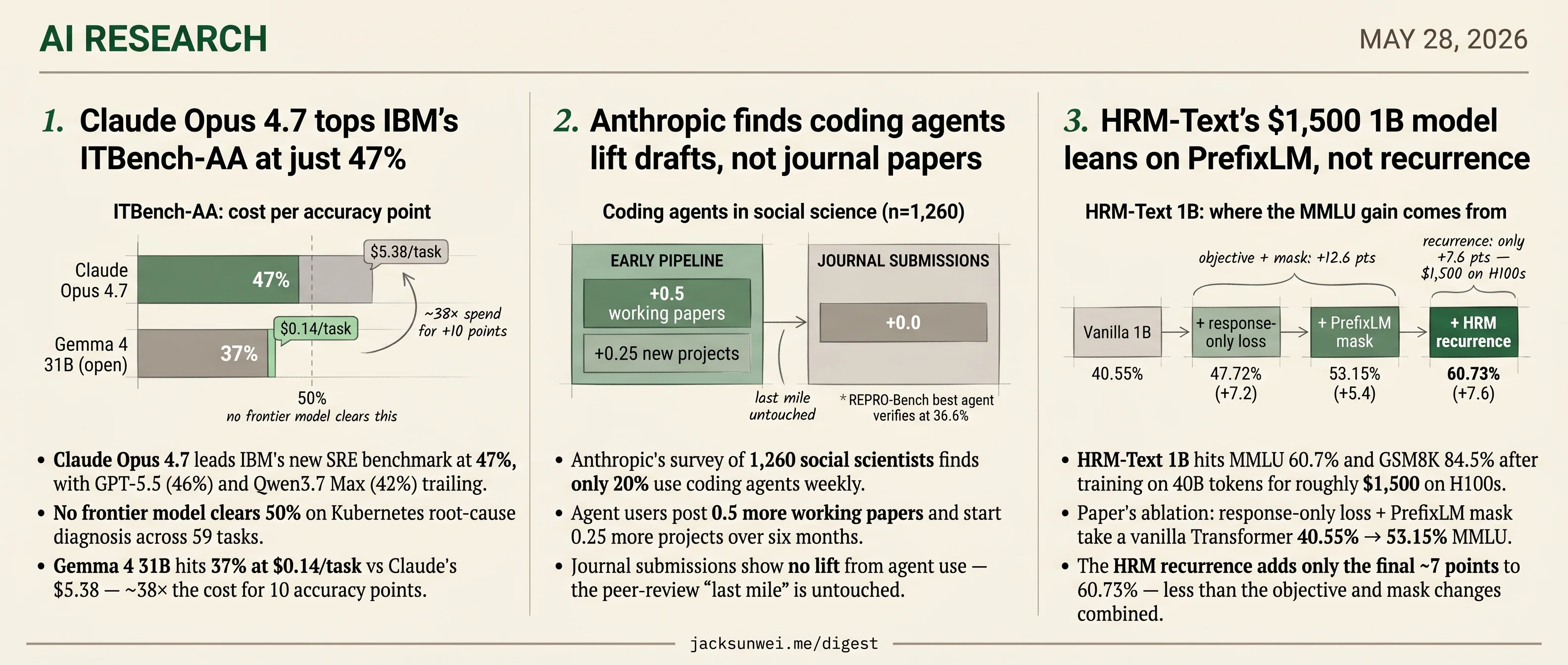
- Claude Opus 4.7 tops IBM’s new ITBench-AA at 47%, with no frontier model clearing 50% on Kubernetes diagnosis.
- Anthropic surveys 1,260 social scientists, finds 20% use coding agents weekly with no journal-submission lift.
- HRM-Text 1B trains for $1,500, with its PrefixLM loss outweighing the hierarchical recurrence in ablations.
- Datadog’s Toto 2.0 sets state-of-the-art on three time-series benchmarks via u-muP scaling transfer.
- RLVR updates trace a near rank-1 path, letting linear regression extrapolate final-model performance cheaply.
Three unrelated research releases land together today. IBM opens its ITBench-AA Kubernetes diagnosis suite, where Claude Opus 4.7 leads at just 47% and no frontier model clears 50% — and critics note that nearly half the mitigation tasks fall to a generic pod-restart loop. Anthropic surveys 1,260 social scientists on coding-agent use and finds the lift sits at the draft stage, not at journal submission. And the HRM-Text 1B report shows a $1,500 training run hitting MMLU 60.7% — but the paper’s own ablation credits the response-only loss and PrefixLM mask for most of the gain, leaving the hierarchical recurrence with only the final ~7 points.
The briefs round out a quieter day of methods work: Datadog’s Toto 2.0 brings scaling laws to time-series forecasting, a pair of RLVR analyses pin down what’s learnable and what isn’t, and a new DPO paper revisits the conditions under which it actually matches RLHF.
Claude Opus 4.7 tops IBM’s ITBench-AA at just 47%
Source: huggingface-blog · published 2026-05-27
TL;DR
- Claude Opus 4.7 leads IBM’s new SRE benchmark at 47%, with GPT-5.5 (46%) and Qwen3.7 Max (42%) trailing.
- No frontier model clears 50% on Kubernetes root-cause diagnosis across 59 tasks.
- Gemma 4 31B hits 37% at $0.14/task vs Claude’s $5.38 — ~38× the cost for 10 accuracy points.
- Critics flag that ~44% of ITBench’s mitigation tasks fall to a generic pod-restart loop, clearing alerts without fixing root causes.
From 11% to 47%: progress with an asterisk
IBM Research and Artificial Analysis just published ITBench-AA, a re-run of IBM’s ICML 2025 ITBench focused on agentic Site Reliability Engineering. The headline: no frontier model clears 50% on Kubernetes incident response. Claude Opus 4.7 leads at 47%, GPT-5.5 follows at 46%, Qwen3.7 Max at 42%.
That sounds bleak until you remember the baseline. The original ITBench paper reported state-of-the-art models resolving only ~11.4% of SRE scenarios 1. Going from 11% to 47% in one model generation is the actual story — but only the SRE persona has been ported into the new harness. The FinOps and CISO slices from the original benchmark are still missing, with IBM signalling they’ll come later 2. Treat the leaderboard as one-third of the eventual surface.
The Stirrup harness gives each agent sandboxed shell access and asks it to identify the minimal set of independent root-cause entities across logs, metrics, and topology spanning 59 tasks. Scoring is recall-gated: miss one root cause and the task goes to zero. That’s a deliberate defence against partial-credit gaming, and it’s why scores compress into a narrow band.
The cost curve is the real story
Strip the model-vs-model framing and the more durable finding is economic. Three rows tell the story 3:
| Model | Score | Cost/task | Avg turns |
|---|---|---|---|
| Claude Opus 4.7 | 47% | $5.38 | — |
| Gemini 3.1 Pro | 30% | $2.23 | 83 |
| Gemma 4 31B (open) | 37% | $0.14 | — |
Gemma 4 31B clears 37% for fourteen cents. Claude Opus 4.7 clears 47% for $5.38 — roughly 38× the spend for ten accuracy points, on a task class where you might run the agent against every paging incident in a fleet. Gemini 3.1 Pro is the cautionary middle: it spends $2.23 and 83 turns to land behind Gemma, because it over-investigates and flags chaos-engineering symptoms as false positives 3. GPT-5.5, by contrast, lands 46% in 31 turns.
More thinking is not free, and on this benchmark it’s actively counterproductive past a certain horizon — a useful corrective to the “let the agent loop until it converges” reflex.
The pod-restart problem
The sharpest dissent doesn’t come from IBM’s reviewers — it comes from practitioners. One analysis of ITBench’s mitigation problems estimates ~44% can be cleared by a generic pod-restart loop, which silences the alert by letting Kubernetes’ own self-healing kick in without ever touching the underlying defect 4. ITBench-AA’s recall-gated scoring partly answers the gaming concern for diagnosis, but the shortcut is a property of the scenarios, not the metric.
ICML reviewers raised a parallel infrastructure complaint: reproducing the push-button Kubernetes harness is heavy enough that independent verification is non-trivial 5. And IBM’s separately published MAST failure taxonomy 6 — which distinguishes fatal errors like incorrect verification from benign step repetition — is the diagnostic layer that would actually explain why models stall at 47%. It isn’t surfaced in the leaderboard.
A 47% top score is real progress over 11%. It is not production readiness for mission-critical IT operations 2, and the cost table is the part to bookmark.
Anthropic finds coding agents lift drafts, not journal papers
Source: anthropic-research · published 2026-05-27
TL;DR
- Anthropic’s survey of 1,260 social scientists finds only 20% use coding agents weekly.
- Agent users post 0.5 more working papers and start 0.25 more projects over six months.
- Journal submissions show no lift from agent use — the peer-review “last mile” is untouched.
- REPRO-Bench’s best agent verifies social-science reproducibility at just 36.6% accuracy.
The adoption snapshot
Anthropic’s early-2026 survey of 1,260 quantitative social scientists puts a real number on a transition most departments are still arguing about. 81% of researchers have used AI chatbots. Only 20% use coding agents — Claude Code, Codex, Cursor — more than once a week. Among that 20%, Claude Code dominates at 86% share. Adoption skews sharply: economists (39%) and political scientists (25%) lead, while public health and education sit in single digits; doctoral students and postdocs adopt at more than twice the rate of tenured faculty; researchers with typically male names adopt at over 2x the rate of those with female names. The headline productivity claim is that agent users are 10–75% more productive in early-pipeline work, starting about 0.25 more projects and posting 0.5 more working papers over six months.
The last-mile gap is the whole story
The result Anthropic mostly buries: agent users do not submit more papers to journals, and do not resubmit faster. They produce more drafts and grant applications, not more finished, peer-reviewed work. Two independent threads explain why.
First, verification is expensive. A LogRocket analysis of AI-authored pull requests found senior engineers spend 4.3 minutes reviewing them versus 1.2 for human code, and they surface 1.7× more issues — a “peer review tax” that eats upstream speedups 7. Stanford’s Andy Hall stress-tested Claude Code on his own 2020 vote-by-mail paper: it replicated all 12 primary coefficients to three decimal places and ported Stata to Python’s pyfixest in under an hour. A manual audit then caught a wrong 2022 turnout figure and a missing California county in the treatment timing 8. Impressive and brittle, in the same run.
Second, the agents are bad at the epistemic check social science actually needs. REPRO-Bench (ACL 2025 Findings) tested whether coding agents can assess the reproducibility of published social-science papers. The best off-the-shelf agent hit 21.4% accuracy; a purpose-built REPRO-Agent reached 36.6% 9. The tools Anthropic credits with generating analyses cannot reliably verify analyses.
The methodological objection
Cornell’s Tom Pepinsky names the deeper risk:
Agentic AI tends to “guess what the user wants to hear,” interpreting results in provocative but incorrect ways — a kind of p-hacking where the agent unknowingly cherry-picks results or modifies code to produce a finding that “vibes” with the prompt 10.
Hall’s counter-vision is that researchers become “firm managers” directing a hundred-agent team 11. Both can be true: more output, less of it load-bearing. Forbes adds a security wrinkle Anthropic doesn’t address — Claude Opus 4.7 introduced security defects in 52% of tested coding tasks, which matters when autonomous agents touch IRB-protected datasets 12.
What to take from it
The survey’s own data tells the honest story if you read past the productivity bullet: coding agents accelerate the generation of social science faster than the field’s verification machinery can keep up. The “0.5 more working papers, zero more journal submissions” gap is not a transitional artifact — it’s what you’d predict from tools that draft well and check poorly. Anthropic’s framing treats the last mile as the next frontier. The dissenters argue it’s the only mile that matters.
HRM-Text’s $1,500 1B model leans on PrefixLM, not recurrence
Source: hf-daily-papers · published 2026-05-19
TL;DR
- HRM-Text 1B hits MMLU 60.7% and GSM8K 84.5% after training on 40B tokens for roughly $1,500 on H100s.
- Paper’s ablation: response-only loss + PrefixLM mask take a vanilla Transformer 40.55% → 53.15% MMLU.
- The HRM recurrence adds only the final ~7 points to 60.73% — less than the objective and mask changes combined.
- Kyle Kastner reproduced the headline MATH and DROP numbers on 16 H200s in ~38 hours.
- Training mix (OpenMathInstruct2, NuminaMath, FLAN) structurally mirrors the eval suite the model is benchmarked on.
The headline pitch
Sapient Intelligence’s HRM-Text paper claims a 1B-parameter Hierarchical Recurrent Model matches or beats Llama 3.2 3B, Qwen 3.5 2B, and OLMo 3 7B across MMLU, GSM8K, MATH, ARC-Challenge and DROP — while using 100–900× fewer training tokens and 96–432× less compute. Total bill: about $1,472 of H100 time, under two days end-to-end. The architecture splits computation across a slow “HH” planning module and a fast “LL” execution module in an H2L3 recurrent loop, stabilized by a hybrid Pre/Post norm scheme (“MagicNorm”) and a warmup schedule for truncated backprop through time.
That is the marketing. The interesting story is which pieces of it survive scrutiny.
Where the gains actually come from
The most load-bearing table in the paper is the objective ablation, and it does not flatter the headline. A vanilla 1B Transformer trained on the same 40B instruction-response corpus scores 40.55% MMLU. Switching to response-only loss (don’t waste capacity predicting the prompt) lifts it to 47.72%. Adding the PrefixLM mask — bidirectional attention over the instruction, causal over the response — pushes it to 53.15%. Only then does swapping in the HRM recurrent architecture take it to 60.73% 13.
So out of the ~20 MMLU points HRM-Text gains over the vanilla 40.55% baseline, roughly 13 come from the objective and the mask, and only ~7 from the much-discussed hierarchical recurrence. That tracks with independent theory: PrefixLMs converge toward the optimal task-distribution solution as samples grow, whereas causal LMs behave more like never-stationary online gradient descent 14. It also tracks with prior ARC Prize work on the original HRM, where an ablation found a same-size standard Transformer reached nearly identical ARC-AGI performance once it was given the same outer-loop refinement and ~300× data augmentation 15.
The recurrence is real, but the headline “100–900× fewer tokens” framing conflates three separate wins into one architectural story.
Reproduction is real; the comparison set is not
Kyle Kastner’s full reproduction on 16 H200s in ~38 hours matched the paper’s MATH and DROP numbers 16. That is meaningful — the original HRM saw its self-reported 41% on ARC-AGI-1 fall to 32% on the semi-private hold-out, and ARC-AGI-2 collapsed to 2% 15. HRM-Text’s easy-benchmark claims appear to survive replication; we have no third-party hold-out evaluation of MMLU or MATH yet.
The more uncomfortable critique is the comparison itself. r/LocalLLaMA commenters note the training corpus — OpenMathInstruct2, NuminaMath, FLAN, OmniMATH — structurally overlaps the evaluation suite, and the model is fragile enough that wrong token_type_ids “silently destroy” performance at inference 17. A Medium reviewer is blunter: HRM-Text is a reasoning specialist trained exclusively on curated instruction pairs being benchmarked against generalist base models like Llama 3.2 and Qwen 2.5, and it shows in the MMLU-vs-MATH gap — strong reasoning, hollow world knowledge 18. The paper itself flags this as “reasons better than it knows.”
What’s actually new
Strip the framing and HRM-Text is still useful evidence: a $1,500 budget can produce a 1B model that benchmarks like a 3–7B generalist on tasks resembling its training distribution, and PrefixLM with response-only loss is doing more of that work than the field has admitted. The architectural-superiority claim is the softest part, and the right next experiment is a 1B PrefixLM-without-recurrence baseline run by someone other than the authors.
Round-ups
Datadog’s Toto 2.0 tops time-series forecasting benchmarks
Source: hf-daily-papers
The time-series foundation model sets state-of-the-art on BOOM, GIFT-Eval and TIME by scaling parameters under a u-muP hyperparameter transfer pipeline. Forecasting accuracy improves predictably with size, bringing the scaling-law playbook from language models to numerical sequence data.
RLVR training trajectories collapse to rank-1, enabling cheap extrapolation
Source: hf-daily-papers
Parameter updates during reinforcement learning with verifiable rewards trace a near rank-1 path, so a simple linear regression on early checkpoints extrapolates the final model. The RELEX method matches full RLVR performance while cutting compute and denoising stochastic optimization noise.
Some RLVR examples stay unlearnable no matter the rollouts
Source: hf-daily-papers
Hard prompts in RLVR resist learning even when correct rollouts exist, because cross-example gradient analysis shows their representations conflict with the rest of the batch. Standard optimizers and data augmentation fail to close the gap, pointing to a representation-level bottleneck.
DPO only matches RLHF under one hidden assumption, paper shows
Source: hf-daily-papers
DPO and RLHF optimize the same objective only when the reference policy meets a specific condition; otherwise they diverge and DPO exhibits failure modes. The authors propose Constrained Preference Optimization, a soft margin ranking variant with provable alignment guarantees.
DynMuon reshapes Muon optimizer’s spectrum during training
Source: hf-daily-papers
DynMuon adjusts the spectral shaping of Muon’s polar-factor update across training stages instead of using a fixed transform, reaching lower validation loss in fewer steps. The dynamic schedule adapts to changing stochastic gradient statistics as optimization progresses.
AI reviewers beat humans at spotting flaws in Nature papers
Source: hf-daily-papers
GPT-5.2, Gemini 3.0 Pro and Claude Opus 4.5 outperformed human reviewers at identifying valid criticisms across Nature-family submissions, in a study with 45 expert scientists. The models still trailed humans on subfield depth and managing long-context manuscript material.
Stability AI ships Stable Audio 3 with open weights
Source: hf-daily-papers
The latent diffusion model handles variable-length generation, editing and inpainting over a semantic-acoustic autoencoder, with adversarial post-training collapsing inference to a handful of steps. Stability is releasing open weights alongside the paper for artistic experimentation.
Footnotes
-
Jha et al., ICML 2025 ITBench paper (PMLR) — https://raw.githubusercontent.com/mlresearch/v267/main/assets/jha25a/jha25a.pdf
↩state-of-the-art models resolved only ~11.4% of SRE scenarios
-
kav.co.id coverage of ITBench-AA — https://news.kav.co.id/n/itbench-aa-agentic-it-benchmark/
↩ ↩2positioned as a potential industry standard for ‘mission-critical IT operations’ … IBM plans to extend the framework to cover FinOps and CISO tasks
-
Artificial Analysis ITBench-AA leaderboard — https://artificialanalysis.ai/evaluations/itbench-aa
↩ ↩2Gemma 4 31B achieves 37% at $0.14 per task … Claude Opus 4.7 the most expensive at $5.38 per task … Gemini 3.1 Pro averaged 83 turns for 30% vs GPT-5.5’s 31 turns
-
Melethil, ‘AI Agent Benchmarks Are Broken’ (Medium) — https://medium.com/@jmelethil/ai-agent-benchmarks-are-broken-here-is-what-to-measure-instead-6c0222dfe702
↩approximately 44% of ITBench’s mitigation problems could be ‘solved’ by a generic pod-restart loop … clears the alert but fails to address the underlying defect
-
OpenReview reviewer comments on ITBench (ICML 2025) — https://openreview.net/forum?id=jP59rz1bZk
↩FinOps category originally contained too few tasks to support broad difficulty claims … ‘push-button’ Kubernetes workflows requires significant infrastructure resources
-
IBM Research — ITBench & MAST blog (Hugging Face) — https://huggingface.co/blog/ibm-research/itbenchandmast
↩Multi-Agent System Failure Taxonomy (MAST) … distinguishes between ‘fatal’ flaws like incorrect verification and ‘non-fatal’ behaviors such as benign step repetition
-
LogRocket Blog — https://blog.logrocket.com/ai-coding-tools-shift-bottleneck-to-review/
↩Senior engineers spend an average of 4.3 minutes reviewing AI-generated pull requests compared to 1.2 minutes for human-written code, and AI-authored code surfaces 1.7x more issues — a ‘peer review tax’ that may explain why agent users start more projects but don’t finish more papers.
-
Henry Farrell, Programmable Mutter — https://www.programmablemutter.com/p/ai-is-great-for-scientists-perhaps
↩Claude Code exactly replicated all 12 primary coefficients to three decimal places… but when extending the data, it failed to calculate 2022 turnout correctly and missed 1 out of 30 California counties in its treatment timing.
-
REPRO-Bench (Hu et al., ACL 2025 Findings) — https://aclanthology.org/2025.findings-acl.1210.pdf
↩The best-performing baseline (CORE-Agent) achieved only 21.4% accuracy on assessing reproducibility of social science papers — barely better than random guessing; their specialized REPRO-Agent improved this to 36.6%.
-
Tom Pepinsky, Substack — https://tompepinsky.substack.com/p/agentic-ai-and-social-science-research/comments?utm_source=post&utm_medium=web&triedRedirect=true
↩Agentic AI tends to ‘guess what the user wants to hear,’ interpreting results in provocative but incorrect ways — creating a risk of p-hacking where the agent unknowingly cherry-picks results or modifies code to produce a finding that ‘vibes’ with the researcher’s prompt.
-
Niskanen Center (Grossmann interview with Andy Hall) — https://www.niskanencenter.org/can-ai-vibe-research-replace-social-science/
↩Hall has reorganized his lab around AI agents, arguing these tools let researchers function like ‘firm managers’ directing a team of a hundred — though critics warn of an industrialization of social science where quantity replaces rigorous, intuition-led inquiry.
-
Forbes — The Wiretap — https://www.forbes.com/sites/the-wiretap/2026/04/22/anthropics-claude-is-pumping-out-vulnerable-code-cyber-experts-warn/
↩Newer versions such as Claude Opus 4.7 introduced security defects in 52% of tested tasks, a sharp decline from previous iterations, raising concerns about autonomous agents that might inadvertently exfiltrate sensitive research data.
-
Tay et al., UL2 / PrefixLM literature (arxiv 2204.05832) — https://arxiv.org/pdf/2204.05832
↩Ablation reported alongside HRM-Text: vanilla 1B Transformer on the same 40B instruction set scores MMLU 40.55%; adding response-only loss lifts it to 47.72%; adding the PrefixLM mask reaches 53.15%; only the final HRM recurrent architecture pushes it to 60.73% — meaning the objective/mask changes account for more of the gain than the recurrence itself.
-
CMU 10-423 lecture notes on PrefixLM theory — https://www.cs.cmu.edu/~mgormley/courses/10423//slides/lecture4-rope-gqa.pdf
↩PrefixLMs can converge to the optimal solution of the underlying task distribution as sample size increases, whereas causal LMs behave like online gradient descent that may never reach a stationary point — a theoretical basis for HRM-Text’s sample-efficiency claim.
-
ARC Prize Foundation leaderboard / analysis of original HRM — https://arcprize.org/leaderboard
↩ ↩2External verification on the semi-private hold-out recorded 32% on ARC-AGI-1 (vs. 41% self-reported) and only 2% on ARC-AGI-2; an ablation found a similarly sized standard Transformer reached nearly identical performance with the same training pipeline — the ‘outer loop’ refinement and ~300x data augmentation were the true drivers.
-
KuCoin news flash on Kyle Kastner reproduction — https://www.kucoin.com/news/flash/tsinghua-alumnus-wang-guan-s-hrm-text-achieves-sota-with-1-900-token-and-1-432-compute
↩Kyle Kastner reported a successful full-scale reproduction of HRM-Text XL (1B) on 16 H200 GPUs in ~38 hours, matching the paper’s MATH and DROP numbers.
-
r/LocalLLaMA discussion thread — https://www.reddit.com/r/LocalLLaMA/comments/1thjgwr/sapient_intelligence_releases_hrmtext_1b_40b/
↩Commenters argue scores like MATH 84.7% and DROP 82.3% are statistically improbable for a 40B-token model unless the curriculum was ‘curriculated’ to mirror the test sets; the model is also reportedly fragile to inference harness — wrong token_type_ids cause ‘silent destruction’ of performance.
-
Medium / ‘Data Science in Your Pocket’ review — https://medium.com/data-science-in-your-pocket/hrm-text-1b-might-be-one-of-the-weirdest-llm-experiments-of-2026-74eb9621e9c3
↩Comparing a model trained exclusively on curated instruction-response pairs (OpenMathInstruct2, NuminaMath, FLAN) against general-purpose base models like Llama 3.2 and Qwen 2.5 is a ‘specialist vs. generalist’ mismatch; HRM-Text is a ‘hollow shell’ on broad world knowledge despite its reasoning scores.