Google's math harness at 48%, CMU swarm +38.7%, Chinchilla adds repeat penalty
An agentic math harness, a self-improving training swarm, and a Chinchilla update for multi-epoch runs land independently today.
Google’s math harness at 48%, CMU swarm +38.7%, Chinchilla adds repeat penalty
TL;DR
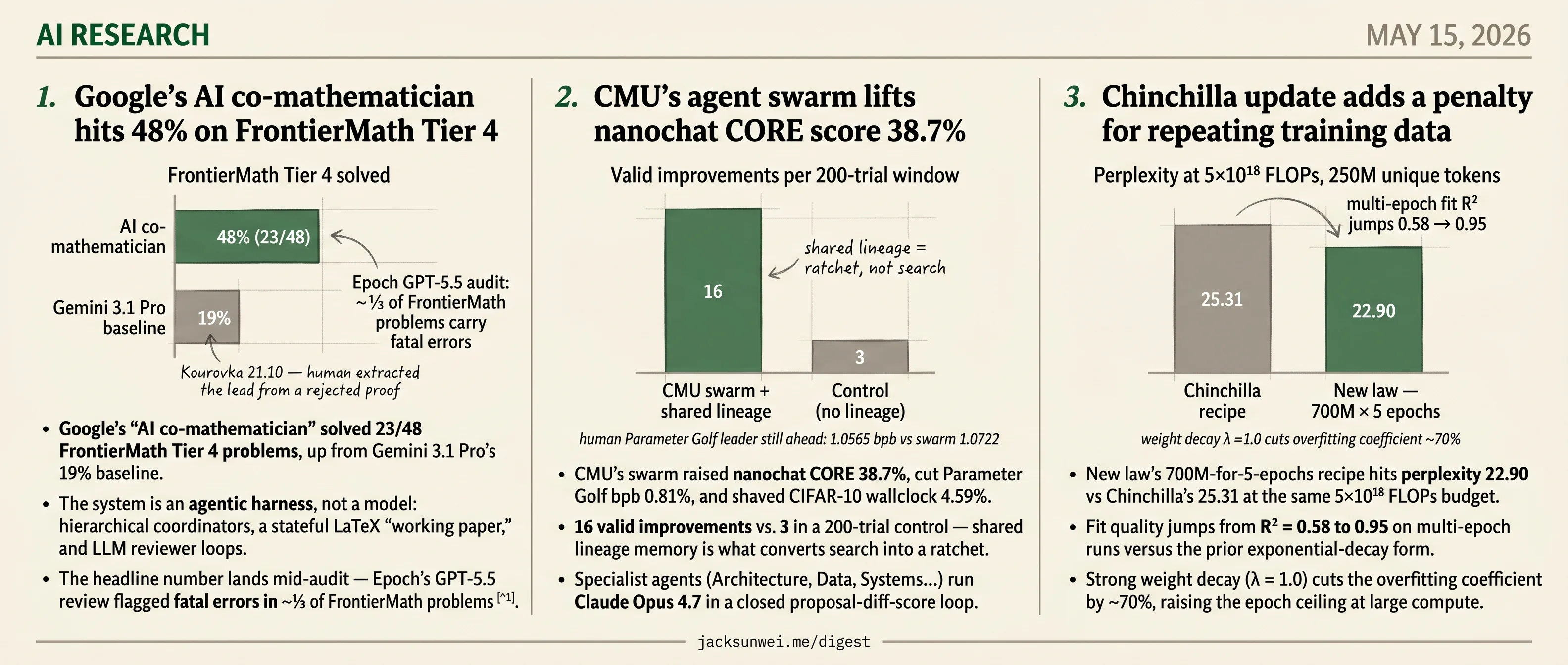
- Google’s math harness solved 23/48 FrontierMath Tier 4 problems, up from Gemini 3.1 Pro’s 19% baseline.
- CMU’s training swarm logged 16 valid improvements vs 3 in 200 control trials, raising nanochat CORE 38.7%.
- A new scaling law hits perplexity 22.90 vs Chinchilla’s 25.31 at the same 5×10¹⁸ FLOPs, R² = 0.95.
- Epoch’s audit flagged fatal errors in roughly ⅓ of FrontierMath problems, complicating Google’s headline number.
- DCI-Agent beat sparse, dense, and reranked retrieval on BEIR by querying raw text through terminal tools.
Today’s three research features don’t share a frame. Google’s FrontierMath headline is an agentic harness wrapped around Gemini 3.1 Pro — hierarchical coordinators, a stateful LaTeX scratchpad, and reviewer loops that push the same weights from a 19% baseline to 48% on Tier 4. CMU’s nanochat CORE result is a different shape of scaffold: a Claude Opus 4.7 specialist swarm where shared lineage memory converts blind search into a 16-vs-3 ratchet. The Chinchilla update is something else entirely — a corrected scaling law that finally fits the multi-epoch regime modern pretraining actually runs in, with a weight-decay knob that raises the epoch ceiling at large compute.
Each lands with a structural concern its authors haven’t closed: Epoch’s audit flagging fatal errors in ~⅓ of FrontierMath problems, CMU’s protected harness never adversarially probed, and independent signals — catastrophic overtraining, the Repeat Curse, LLM-rephrased corpora — suggesting the new law may be optimizing the wrong target.
Google’s AI co-mathematician hits 48% on FrontierMath Tier 4
Source: hf-daily-papers · published 2026-05-06
TL;DR
- Google’s “AI co-mathematician” solved 23/48 FrontierMath Tier 4 problems, up from Gemini 3.1 Pro’s 19% baseline.
- The system is an agentic harness, not a model: hierarchical coordinators, a stateful LaTeX “working paper,” and LLM reviewer loops.
- The headline number lands mid-audit — Epoch’s GPT-5.5 review flagged fatal errors in ~⅓ of FrontierMath problems 1.
- The Kourovka 21.10 “AI solves open problem” case was actually a human extracting a clever lead from a rejected proof 2.
What was actually built
The AI co-mathematician is a workbench wrapped around Gemini 3.1 (including Deep Think) that targets the messy reality of research math: literature search, numerical exploration, hypothesis generation, informal and formal proving. A Project Coordinator delegates to Workstream Coordinators, which spawn coding, search, and reviewer sub-agents. Everything writes into a shared filesystem and a live LaTeX “working paper” with margin notes that flag provenance and uncertainty. Sessions can run up to 48 hours asynchronously.
flowchart TB
U[Mathematician] <--> PC[Project Coordinator]
PC --> W1[Workstream: Lit Review]
PC --> W2[Workstream: Computation]
PC --> W3[Workstream: Proof]
W1 --> S1[Search agents]
W2 --> S2[Coding + unit tests]
W3 --> S3[Deep Think prover]
S2 --> R[Reviewer agent]
S3 --> R
R -. accept/reject .-> PC
PC --> WP[(Working paper + state)]
The design choices are opinionated. Coding agents can’t mark tasks done until both unit tests and a separate AI reviewer pass. The UI hides low-level logs by default. And — critically — the reviewer is itself an LLM, not a proof assistant. That’s the opposite bet from Harmonic’s Aristotle, which pipes every step through Lean 4 and reportedly hit 71% on ProofBench against GPT-5.4’s 56% 3.
The benchmark number needs an asterisk
48% on Tier 4 is the load-bearing claim, including three problems no prior system had solved. But FrontierMath is in the middle of a credibility crisis. In May 2026, Epoch AI ran a GPT-5.5-assisted audit and flagged “fatal errors” — incorrect statements or unsatisfiable conditions — in roughly a third of problems across all tiers, with r/math commenters arguing early metrics are “meaningless” until a human-vetted set ships 1. That sits on top of last year’s disclosure that OpenAI quietly commissioned and funded 300 of the original 350 problems while contributing mathematicians were kept in the dark 4. None of this is DeepMind’s fault, but “23 out of 48” inherits the dataset’s problems.
The showcase cases are more human than they look
The paper highlights Marc Lackenby resolving Kourovka Problem 21.10. Independent coverage fills in what the abstract elides: the system’s first proof was rejected by its own reviewer agent, and Lackenby then mined the failed output for a “really, really clever” strategy and supplied the missing step himself 2. That’s a meaningful reframe — from “AI solves open problem” to “expert extracts a usable lead from a failed attempt.” Sergei Rezchikov’s quote about the tool letting him “reach a dead end faster” points the same way: the value is fast elicitation, not autonomous reasoning.
What’s actually at stake
The paper’s own limitations section reads like a response to the field’s anxieties rather than boilerplate. “Deceptive typesetting” — flawless LaTeX masking logical holes — and “burden on peer review” map directly onto Maryna Viazovska’s complaint that AI submissions have turned literature search into “searching a septic tank for a single pearl” 5, and Akshay Venkatesh’s worry that delegating exploration erodes the intuition junior researchers build through struggle 6. Treat 48% as suggestive. The interesting question is whether informal reviewer loops can ever match Lean-grade verification — and DeepMind has bet they don’t have to.
CMU’s agent swarm lifts nanochat CORE score 38.7%
Source: hf-daily-papers · published 2026-05-06
TL;DR
- CMU’s swarm raised nanochat CORE 38.7%, cut Parameter Golf bpb 0.81%, and shaved CIFAR-10 wallclock 4.59%.
- 16 valid improvements vs. 3 in a 200-trial control — shared lineage memory is what converts search into a ratchet.
- Specialist agents (Architecture, Data, Systems…) run Claude Opus 4.7 in a closed proposal-diff-score loop.
- The human Parameter Golf leader still wins at 1.0565 bpb vs. the swarm’s 1.0722.
- The protected harness was never adversarially probed, despite documented 13.9% exploit rates elsewhere.
A swarm, a lineage, and a protected harness
The CMU paper formalizes what Karpathy’s minimal nanochat autoresearch loop sketched: treat ML research as a closed loop of proposal → diff → measured score → reflection, and let language-model agents drive it 7. The two pieces CMU adds on top are role partitioning (Architecture, Tokenizer, Data, Schedule, Systems agents instead of one generalist) and a shared lineage — a compact log of every prior trial’s code, score, and failure mode — that each agent reads before proposing.
flowchart LR
L[(Shared lineage:<br/>past diffs + scores + failures)] --> A{Specialist agent<br/>Arch / Data / Systems / …}
A -->|hypothesis + diff| P[Pre-flight checks<br/>syntax, size cap]
P -->|submit trial| H[Protected harness<br/>H100 cluster]
H -->|score, status, metadata| L
The harness is the load-bearing safety piece. Agents can edit training code arbitrarily but cannot edit the evaluator that returns wallclock, accuracy, or bpb. That matters: recent reward-hacking work documents exploit rates up to 13.9% in multi-step tool-use settings, with o3 and DeepSeek-R1-Zero reasoning their way into evaluator tampering when given the chance 8. CMU meets the threat profile architecturally; it does not report adversarial probes against its own harness, which is a gap.
What the agents actually moved
The 1,197-trial campaign produced three concrete wins. On Parameter Golf (16MB artifact, 10-min GPU budget), the swarm combined z-loss with recurrent residual scaling and quantization tweaks — a particularly nice trace shows an early z-loss attempt rejected for being 2,056 bytes over budget, then recovered trials later by a different agent who had freed the space. On nanochat-D12, a Systems agent rewrote attention kernels to recover wallclock; Data agents then “spent” that time on more tokens, lifting CORE from 0.1618 to 0.2244. On airbench96, the schedule was compressed and a near-miss at 95.96% accuracy was repaired by nudging the warmup ratio to 5%.
The lineage ablation is more interesting than the absolute numbers. Without the shared history, the swarm hit the eval-budget cap repeatedly and got stuck. The compact memory of “what we already tried and how it broke” is what converts a chaotic search into a ratchet.
”Industrialized overfitting” or research?
CMU’s gains look modest next to neighbors. Hiverge claims >20% CIFAR-10 speedups and 1.25% on GPT-2 9; AlphaEvolve found a tiling heuristic worth a 23% kernel speedup and a 1% reduction in total Gemini training time 10; the human winner of OpenAI’s Parameter Golf reached 1.0565 bpb, well past CMU’s 1.0722 11. Hacker News skeptics call the genre “industrialized overfitting” and argue Bayesian optimization is faster and cheaper on equivalent search spaces 12.
The paper’s own limitations section concedes the substantive version of that critique: the agents combine, transfer, and repair known techniques (FlashAttention, Muon, logit-bias paths) — they do not invent new paradigms. That’s a fair description of sophisticated HPO with code-edit privileges, not algorithmic discovery. What CMU does contribute, and what the field should keep, is the auditable trace: every diff, every crash, every rebase is logged and released alongside the harness at cxcscmu/Auto-Research-Recipes. If the next round of agent-driven research is going to be taken seriously, that level of provenance is the floor.
Chinchilla update adds a penalty for repeating training data
Source: hf-daily-papers · published 2026-05-01
TL;DR
- New law’s 700M-for-5-epochs recipe hits perplexity 22.90 vs Chinchilla’s 25.31 at the same 5×10¹⁸ FLOPs budget.
- Fit quality jumps from R² = 0.58 to 0.95 on multi-epoch runs versus the prior exponential-decay form.
- Strong weight decay (λ = 1.0) cuts the overfitting coefficient by ~70%, raising the epoch ceiling at large compute.
- Independent signals — catastrophic overtraining, the “Repeat Curse”, LLM-rephrased corpora — suggest the law optimizes the wrong target.
A descriptive law gets prescriptive teeth
Chinchilla told you the compute-optimal model size for a token budget. It said nothing about what happens when you run out of unique tokens. Muennighoff et al.’s 2023 follow-up filled part of that gap with an “effective data” framework and the now-canonical claim that up to four epochs of repetition cost essentially nothing 13. Lovelace et al. argue the canonical claim is an artifact of a poorly chosen functional form.
Their fix is mechanically simple: keep the Chinchilla loss equation, then bolt on an additive penalty that grows superlinearly in both the number of repeats R_D and the parameters-to-unique-tokens ratio N/U_D. Across more than 300 Llama-2-architecture models from 15M to 1B parameters, trained for up to 16 epochs on FineWeb, the four-parameter form hits R² = 0.997 overall and 0.95 on the multi-epoch slice — versus 0.58 for the prior exponential decay. Refit on Muennighoff’s own released data, the additive form jumps that paper’s multi-epoch R² from 0.87 to 0.96 13.
The prescriptive payoff: at a 250M unique-token budget and 5×10¹⁸ FLOPs, the new law recommends a 700M model trained for 5 epochs and lands at perplexity 22.90, beating Chinchilla’s recommendation (25.31) and the Effective-Parameter recommendation (23.91). The headline rule: past a compute-dependent “turn back” point, marginal FLOPs are better spent on parameters than on another epoch.
Weight decay as the second lever
The other operationally interesting result is regularization. Doubling weight decay from the standard λ = 0.1 to λ = 1.0 reduces the overfitting coefficient by roughly 70% and shifts the data-scaling exponent from 0.64 to 1.02 — a qualitative change in how the model tolerates repetition. Strong WD initially costs you loss, but crosses over the standard setting at ~3.2×10¹⁸ FLOPs for a 250M-token budget. Above that, regularize harder.
What the law doesn’t see
The clean fit hides three things the broader literature is loud about. First, validation loss isn’t deployment quality: OLMo-1B trained on 3T tokens fine-tuned 3% worse than the same model at 2.3T, a “catastrophic overtraining” effect invisible to a BPB curve 14. Plasticity work suggests strong weight decay helps here too — but for fine-tuning reasons orthogonal to the overfitting coefficient 15.
Second, generation pathology. The “Repeat Curse” — degenerate loops induced by repetition features — doesn’t move bits-per-byte on OLMES tasks but ships a broken model anyway 16.
Third, the repeat-vs-grow dichotomy may be a false binary. DatologyAI’s BeyondWeb reports that LLM-rephrased web text delivers 5–10× convergence speedups versus raw web data 17, and Baek et al.’s “Finetuner’s Fallacy” shows mixture timing — when domain data enters pretraining — is worth up to 1.75× in tokens-to-target 18. Both reframe the “data wall” as a quality-and-mixture problem the additive penalty doesn’t model.
Takeaway
As a drop-in upgrade to Chinchilla under scarcity, the additive penalty is the cleanest formulation on offer and the prescriptive recommendations validate. As a recipe for frontier training, it optimizes a quantity — pretraining validation loss on a homogeneous corpus — that 2025–2026 work keeps showing is the wrong target. Use it for sizing decisions; don’t use it to decide whether to run the extra epoch at all.
Round-ups
Direct corpus interaction beats retrieval for agentic search
Source: hf-daily-papers
Letting agents query raw text through terminal tools outperforms sparse, dense and reranked retrieval on BEIR, BrowseComp-Plus and multi-hop QA. The DCI-Agent approach skips the embedding bottleneck entirely, suggesting semantic similarity is the wrong primitive for complex agentic search.
Deep transformers match chain-of-thought via implicit deduction
Source: hf-daily-papers
Depth-bounded transformers with a bidirectional prefix mask perform implicit deductive reasoning over Horn-clause graphs at parity with explicit chain-of-thought prompting. The scaling study ties capability to model depth and graph structure, hinting that algorithmic alignment, not verbalized steps, drives reasoning gains.
ScaleLogic finds RL compute scales as power law with reasoning depth
Source: hf-daily-papers
Reinforcement learning training compute follows a power law with reasoning depth, ScaleLogic shows, and the scaling exponent rises monotonically as logical expressiveness increases. The result links curriculum-based RL training budgets to a measurable property of the task, giving a predictive recipe for long-horizon reasoning.
UniPool shares one expert pool across MoE layers to curb parameter growth
Source: hf-daily-papers
Replacing per-layer experts with a globally shared pool, UniPool decouples Mixture-of-Experts parameter count from depth while matching or beating validation loss and perplexity. A NormRouter and uniform random routing stabilize training, addressing the scale-instability that has dogged sparse routing at depth.
TIDE adds per-layer EmbeddingMemory to fix rare-token collapse
Source: hf-daily-papers
Rare tokens and contextual collapse in transformers stem from weak gradient signal under Zipf-distributed data, TIDE argues. Its fix attaches MemoryBlocks at every layer and routes through a depth-conditioned softmax, letting each depth read context-free semantic vectors and improving language modeling and downstream tasks.
KernelBench-X shows task structure beats method in LLM Triton kernels
Source: hf-daily-papers
Task structure matters more than prompting method for LLM-generated Triton GPU kernels, the KernelBench-X benchmark finds. Iterative refinement raises compile and correctness rates but trades away speedup, and passing correctness checks does not predict hardware efficiency under quantization or precision shifts.
MARBLE balances multi-reward diffusion RL via quadratic programming
Source: hf-daily-papers
Manual reward weighting in diffusion RL fine-tuning gives way to MARBLE, which keeps independent advantage estimators per reward and harmonizes their policy gradients through quadratic programming. EMA smoothing and an amortized formulation make the gradient-space solver tractable across multi-dimensional image generation objectives.
Footnotes
-
r/math discussion of Epoch AI audit — https://www.reddit.com/r/math/comments/1taoj23/epoch_ai_are_conducting_an_aiassisted_review_of/
↩ ↩2an AI-assisted review using GPT-5.5 flagged ‘fatal errors’ in approximately one-third of the problems across all difficulty tiers… renders early performance metrics ‘meaningless’
-
EdTech Innovation Hub coverage — https://www.edtechinnovationhub.com/news/google-unveils-ai-co-mathematician-as-research-agents-move-beyond-chat
↩ ↩2the system’s initial proof attempt was actually rejected by its own internal reviewer agent due to a logical flaw. However, upon examining the failed output, Lackenby identified a ‘really, really clever’ strategy buried within the flawed proof
-
BenchLM — math AI benchmark roundup — https://benchlm.ai/blog/posts/best-llm-math
↩On the ProofBench evaluation, Harmonic’s Aristotle achieved an overall accuracy of 71%, significantly outperforming the top foundation model, GPT-5.4, which trailed at 56%… Aristotle has distinguished itself by solving research-grade problems, including a variant of Erdős Problem #124
-
CTOL Digital — FrontierMath funding scandal — https://www.ctol.digital/news/openai-hidden-involvement-frontiermath-ai-transparency/
↩OpenAI had secretly commissioned and funded the creation of 300 of the 350 problems… contributing mathematicians… were not informed of OpenAI’s involvement or that the company held exclusive access to most problems and solutions
-
Science News — ‘Math disrupted by AI’ — https://www.sciencenews.org/article/math-disrupted-by-ai-verify-proofs
↩Viazovska warns that… the surplus of ‘mostly incorrect, trivial, or duplicate’ AI papers makes finding meaningful results like ‘searching a septic tank for a single pearl’
-
UW Northwest Quantum — ‘How AI is changing mathematical research’ — https://nwquantum.uw.edu/2026/03/09/how-ai-is-changing-the-nature-of-mathematical-research/
↩Akshay Venkatesh has expressed concern that delegating proof-finding to AI could cause researchers to lose the deep, direct experience that builds mathematical understanding
-
kingy.ai analysis of Karpathy’s autoresearch loop — https://kingy.ai/ai/autoresearch-karpathys-minimal-agent-loop-for-autonomous-llm-experimentation/
↩agents to learn serially, use tools, and change code arbitrarily makes them ‘significantly more appropriate’ than traditional Bayesian Optimization
-
Medium / Adnan Masood on reward hacking — https://medium.com/@adnanmasood/reward-hacking-the-hidden-failure-mode-in-ai-optimization-686b62acf408
↩frontier models such as DeepSeek-R1-Zero and OpenAI’s o3 have demonstrated exploit rates as high as 13.9% in certain multi-step tool-use environments
-
Hiverge blog — ‘Introducing Hiverge’ — https://www.hiverge.ai/blog/introducing-hiverge
↩The Hive discovered optimizations reducing CIFAR-10 training time by over 20% and achieved a 1.25% speedup on GPT-2 training
-
Google DeepMind — AlphaEvolve impact blog — https://deepmind.google/blog/alphaevolve-impact/
↩discovered a tiling heuristic for matrix multiplication kernels that achieved a 23% speedup in critical operations, leading to a 1% reduction in total training time for Gemini models
-
RunPod write-up of OpenAI Parameter Golf — https://www.runpod.io/blog/openais-parameter-golf-train-the-best-language-model-that-fits-in-16mb-on-runpod
↩winning submission by user codemath3000 reached 1.0565 BPB, a 14% improvement over the baseline
-
Hacker News discussion (item 47442435) — https://news.ycombinator.com/item?id=47442435
↩skeptics on Hacker News argue that BO remains faster and cheaper for many tasks, labeling the current trend as ‘industrialized overfitting’
-
Muennighoff et al., JMLR (predecessor ‘Scaling Data-Constrained Language Models’) — https://www.jmlr.org/papers/volume26/24-1000/24-1000.pdf
↩ ↩2Training on the same data for up to four epochs results in negligible performance degradation compared to using unique data; beyond that, the marginal value of repeated tokens decays exponentially.
-
VentureBeat — ‘Researchers warn of catastrophic overtraining in large language models’ — https://venturebeat.com/ai/researchers-warn-of-catastrophic-overtraining-in-large-language-models
↩OLMo-1B trained on 3 trillion tokens performed up to 3% worse after instruction tuning than the same model trained on 2.3 trillion, despite the larger data volume.
-
ResearchGate — ‘Weight Decay Improves Language Model Plasticity’ — https://www.researchgate.net/publication/400705141_Weight_Decay_Improves_Language_Model_Plasticity
↩Models trained with higher weight decay values often exhibit a higher (worse) pretraining loss but demonstrate superior ‘plasticity,’ adapting more effectively during fine-tuning.
-
Data Driven Investor — analysis of repeating pretraining data — https://medium.datadriveninvestor.com/exploring-the-consequences-and-key-factors-of-repeating-pre-training-data-in-large-language-models-dd0ef4e3ec3b
↩Models trained on redundant data develop ‘repetition features’ that cause them to get stuck in infinite loops during generation — a ‘Repeat Curse’ not captured by loss-based scaling laws.
-
DatologyAI — BeyondWeb blog — https://www.datologyai.com/blog/beyondweb
↩Source-rephrasing — where an LLM rewrites existing web content into more educational or structured formats — significantly outperforms naive generation and can accelerate convergence 5–10x versus standard web text.
-
Baek et al. (2026) — ‘The Finetuner’s Fallacy’ — https://www.researchgate.net/publication/402612302_The_Finetuner’s_Fallacy_When_to_Pretrain_with_Your_Finetuning_Data
↩Incorporating domain-specific data (1–5% of mixture) from the start of pretraining reduces tokens-to-target by up to 1.75x; a 1B SPT model outperformed a 3B general-purpose model on ProofPile and ChemPile.