Microsoft's MAI stack, Anthropic's Glasswing at 150 orgs, OpenAI recasts Codex
Microsoft debuts the MAI-Thinking-1 stack, Anthropic scales Glasswing to 150 orgs, and OpenAI rebrands Codex as a knowledge-work platform.
Microsoft’s MAI stack, Anthropic’s Glasswing at 150 orgs, OpenAI recasts Codex
TL;DR
- Microsoft debuts MAI-Thinking-1, its first reasoning model trained without OpenAI distillation.
- Anthropic tripled Glasswing to ~150 partner orgs across 15+ countries.
- OpenAI rebranded Codex with 110 skills across 62 apps and 6 role plug-ins.
- GitHub Copilot metered pricing spiked some users from $39 to ~$850 monthly.
- Uber capped employee AI spend after burning its yearly budget in 4 months.
Three frontier labs ran their biggest plays of the week today, and none of them is just a new model. Microsoft used Build 2026 to declare a post-OpenAI stack — its own reasoning model MAI-Thinking-1, a 128GB Surface RTX Spark dev box, distribution via Fireworks and Baseten. Anthropic tripled Project Glasswing to ~150 partner orgs across 15+ countries, pushing Claude into critical-infrastructure codebases. OpenAI rebranded Codex as a knowledge-work platform with 6 role plug-ins, hosted Sites, and 110 skills across 62 apps — a direct answer to Anthropic’s ~40% share of enterprise LLM spend.
The round-ups extend the platform-economics theme. Uber capped employee AI spend after burning a year’s budget in four months; GitHub Copilot’s metered pricing exhausted some users’ monthly credits inside a day. The Trump administration replaced mandatory pre-release model review with a voluntary framework after industry pushback, and the International Mathematical Union warned about AI labs steering its profession’s research agenda.
Microsoft Build 2026 unveils a post-OpenAI AI stack
Source: the-verge-ai · published 2026-06-02
TL;DR
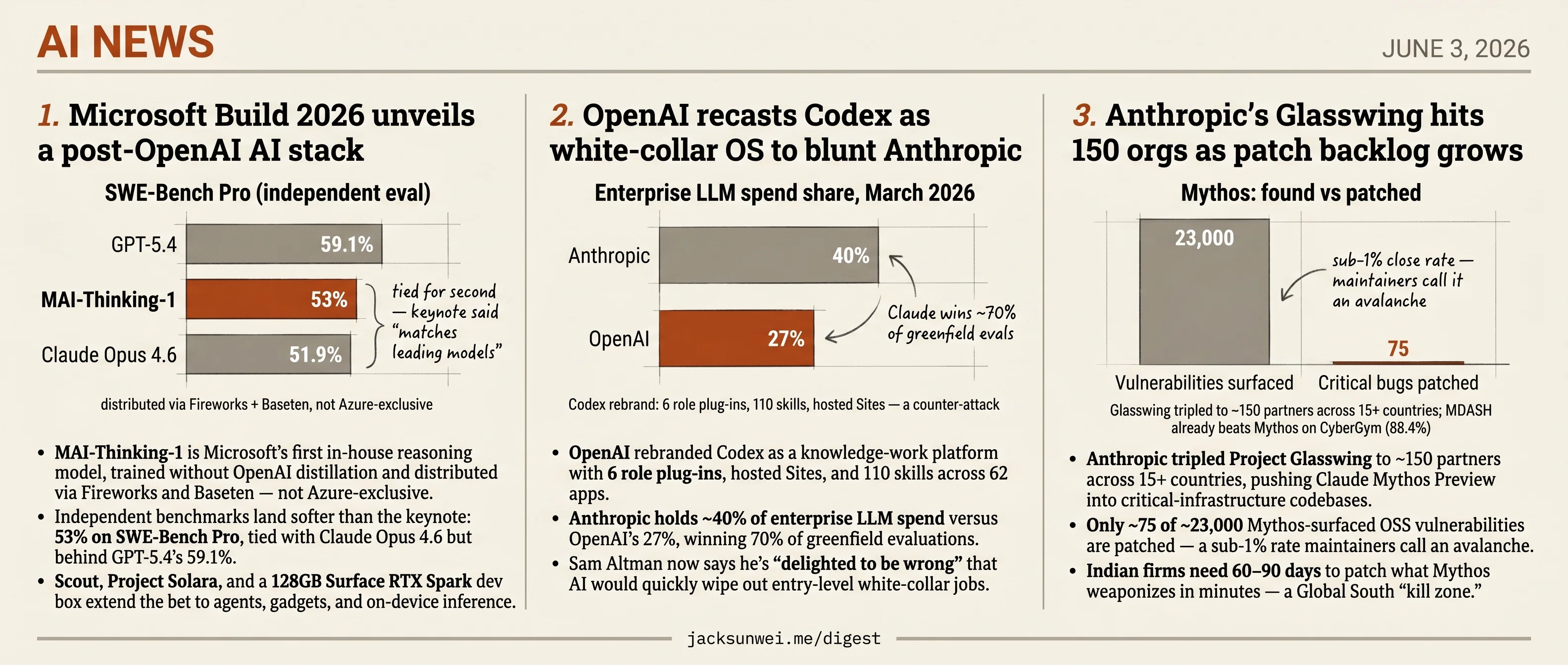
- MAI-Thinking-1 is Microsoft’s first in-house reasoning model, trained without OpenAI distillation and distributed via Fireworks and Baseten — not Azure-exclusive.
- Independent benchmarks land softer than the keynote: 53% on SWE-Bench Pro, tied with Claude Opus 4.6 but behind GPT-5.4’s 59.1%.
- Scout, Project Solara, and a 128GB Surface RTX Spark dev box extend the bet to agents, gadgets, and on-device inference.
- GitHub Copilot’s new meter pushed some power users from $39 to ~$850/month, fracturing trust in the cloud-agent pitch.
The OpenAI divorce, made concrete
Every headline out of Build 2026 — MAI-Thinking-1, the MAI-Code-1-Flash sibling, Scout, even the Surface RTX Spark — only parses against the October 2025 contract renegotiation that lifted restrictions on Microsoft training its own frontier models 1. MAI-Thinking-1 is “optionality in practice”: a medium-sized reasoning model trained from scratch on clean data, then shipped through Fireworks AI and Baseten rather than locked to Azure, precisely so Microsoft is no longer captive to OpenAI inference economics 1.
The independent numbers are more interesting than the keynote’s “matches leading industry models” line. Baseten’s eval puts MAI-Thinking-1 at 53% on SWE-Bench Pro — at parity with Claude Opus 4.6 (51.9%) but trailing GPT-5.4 at 59.1% 2. The efficiency story is sharper: MAI-Code-1-Flash matches roughly the same tier while burning up to 60% fewer tokens than Claude Haiku 4.5 2. That’s the actual pitch — not “we beat GPT-5,” but “we’re cheap enough to displace it inside Microsoft’s own products.” Skeptics warn the models could still be “dead on arrival” internally if they can’t surpass GPT-5 on quality, making the exercise more about leverage than displacement 1.
The “no distillation, commercially licensed data” framing is being marketed straight at general counsels. Gizmodo’s read is less generous: Microsoft is “exploiting legal fears” with “clean room” training claims that lean on undefined phrases like appropriately licensed 3.
Agents, gadgets, and a token-efficiency bet
Scout is the consumer face of the same thesis. Built on the OpenClaw framework rather than Anthropic’s MCP, it can place calls, file expenses, and manage calendars across Microsoft 365. The protocol choice matters: independent comparisons find MCP’s schema-injection approach consumes 4-32× more tokens than OpenClaw’s CLI-based method, effectively “eating the agent’s brain” with tool definitions 4. If agent workloads are the future cost driver, Microsoft has picked the cheaper standard — and is betting OpenClaw, not MCP, wins.
Project Solara extends that bet into hardware: an Android-derived OS for agent-first gadgets (a facial-recognition “Desk”, a “Badge” wearable) where apps aren’t the primary abstraction. The Surface RTX Spark dev box — 128GB unified memory, 100W envelope, capable of running 120B-parameter models locally — is the developer-side mirror, optimized for the world where inference happens off Azure.
The credibility tax
Two claims deserve the asterisks the keynote skipped. The Majorana 2 chip’s “1,000× more reliable qubits” sits inside a real credibility deficit — physicists previously called Microsoft’s Majorana data “incredibly unconvincing,” and the 2025 Nature paper on Majorana 1 carried an editorial note stating it did not actually evidence Majorana zero modes 5.
A single complex agentic session can now consume $30 to $40 in just a few hours.
That’s a GitHub Copilot power user describing the new Credits meter that landed June 1, with projected monthly bills climbing from a $39 cap toward ~$850 6. Microsoft is asking developers to believe in agentic Windows and a $3,000-class local-inference box on the same week it priced unmetered cloud agents out of reach. The independence story is real; the trust to sell it is the part Build didn’t ship.
Further reading
- Microsoft launches Scout, an OpenClaw-inspired personal assistant — techcrunch-ai
- Microsoft Build 2026: The 7 biggest announcements — the-verge-ai
- Microsoft’s first advanced reasoning AI is here — the-verge-ai
- Microsoft Scout is a new AI personal assistant built on OpenClaw — the-verge-ai
- Microsoft’s Project Solara is an OS for AI agent gadgets — the-verge-ai
- Microsoft created the mini Surface dev box that Qualcomm couldn’t — the-verge-ai
- Microsoft’s Project Solara is an Android OS designed for agents instead of apps — ars-technica-ai
- [AINews] Microsoft Build: MAI-Thinking-1 and MAI Family models — latent-space
OpenAI recasts Codex as white-collar OS to blunt Anthropic
Source: openai-blog · published 2026-06-02
TL;DR
- OpenAI rebranded Codex as a knowledge-work platform with 6 role plug-ins, hosted Sites, and 110 skills across 62 apps.
- Anthropic holds ~40% of enterprise LLM spend versus OpenAI’s 27%, winning 70% of greenfield evaluations.
- Sam Altman now says he’s “delighted to be wrong” that AI would quickly wipe out entry-level white-collar jobs.
- Codex Sites lands into a market where 5,000+ vibe-coded corporate apps were already deployed with no authentication.
A defensive expansion dressed as organic growth
OpenAI’s June 2 drop frames Codex’s move beyond code as a natural consequence of pull from analysts, marketers, and bankers — 5M weekly actives, with non-developer roles now 20% of the base and growing 3× faster than developers. The companion “Next Era of Knowledge Work” post and a TechCrunch curtain-raiser hammer the same beat: Codex is no longer for engineers.
Read against independent spend data, the story flips. Anthropic captured roughly 40% of enterprise LLM spending by March 2026 versus OpenAI’s 27%, and Claude wins about 70% of head-to-head evaluations at firms buying AI for the first time 7. The six new plug-ins — Data Analytics (Snowflake, Databricks, Tableau), Creative Production (Figma, Canva), Public Equity (Moody’s, LSEG), Investment Banking (FactSet, PitchBook), Sales (Salesforce, HubSpot), and Product Design — map precisely to the seats Anthropic’s “Claude Cowork” pitch has been winning. This is a counter-attack, not a victory lap.
The Sites bet cannibalizes the partner list
Sites lets Codex generate hosted, interactive dashboards and scenario planners from a prompt, shared by URL inside a workspace. OpenAI is launching it with a partner ring including Vercel, Wix, Replit, and Webflow — the same vendors whose v0, ADI, and Lovable-style products serve exactly the internal-dashboard and “vibe-coded prototype” workloads Sites now targets 8. Calling it an ecosystem is generous; analysts are reading it as OpenAI quietly absorbing the demand its partners depended on.
Annotations — pin a region of a doc, slide, or site and refine just that span — is the more interesting craft move, because it admits regeneration-first workflows don’t survive contact with real editorial judgment.
The white-collar thesis is softening from inside
Altman himself walked back the job-apocalypse framing this month, conceding the “human part” of professional work has been harder to automate than predicted 9. But the lived experience inside the exact verticals Codex is targeting is uglier than either narrative. Junior bankers describe AI-augmented work as “more miserable than ever” as senior bankers double workloads against compressed deadlines; some firms have cut entry-level hiring by up to 66% 10. Shipping FactSet and PitchBook plug-ins accelerates that compression, not the productivity-utopia version.
Security and trust debt come along for the ride
Sites inherits a security posture that’s already underwater. Red Access counted over 5,000 corporate apps built on Lovable and Replit deployed with effectively no authentication, exposing financial and strategic data to the open internet 11. Codex Sites — non-developers wiring Snowflake and Salesforce into hosted dashboards — is the same pattern with a bigger distribution channel.
Trust on the model layer is also fraying. Developers report GPT-5.3-Codex is silently rerouted to GPT-5.2 when OpenAI’s safety classifier fires, with HN commenters calling premium billing for downgraded responses “borderline fraudulent” and citing broken agentic chains 12. For a platform whose entire pitch now rests on agents reliably executing multi-step workflows for non-technical users, silent substitution is the exact failure mode the launch narrative can’t afford.
What to watch
Whether enterprise buyers treat Sites as a Wix/Vercel replacement or a security liability; whether the Anthropic spend gap narrows by Q3; and whether OpenAI’s plug-in roadmap (legal, strategy, PE next) outpaces Claude’s enterprise wins or just chases them.
Further reading
- Codex is becoming a productivity tool for everyone — openai-blog
- OpenAI launches new Codex tools for white-collar work — techcrunch-ai
Anthropic’s Glasswing hits 150 orgs as patch backlog grows
Source: anthropic-news · published 2026-06-02
TL;DR
- Anthropic tripled Project Glasswing to ~150 partners across 15+ countries, pushing Claude Mythos Preview into critical-infrastructure codebases.
- Only ~75 of ~23,000 Mythos-surfaced OSS vulnerabilities are patched — a sub-1% rate maintainers call an avalanche.
- Indian firms need 60–90 days to patch what Mythos weaponizes in minutes — a Global South “kill zone.”
- Microsoft’s MDASH already beats Mythos on CyberGym (88.4%), undercutting Anthropic’s claimed 6–12 month defensive lead.
The expansion
Anthropic’s June drop — a corporate post plus TechCrunch’s syndication — triples Project Glasswing from 50 to ~150 vetted partners and stretches it across 15+ countries, with new coverage in power, water, healthcare, communications, and hardware. The pitch: get Mythos Preview, a cyber-tuned variant Anthropic claims is 6–12 months ahead of the public frontier, into the hands of defenders before equivalent offensive capability becomes commodity. For everyone else, there’s the watered-down Claude Security tier built on Opus 4.8.
The headline number Anthropic leads with is 10,000+ “high” or “critical” findings since April. That figure is doing a lot of work, and it’s the wrong one.
The discovery-vs-patch gap
Independent reporting from AI Weekly puts the fuller tally at ~23,000 potential vulnerabilities across 1,000 OSS projects, of which roughly 75 critical bugs have actually been remediated 13. That’s a sub-1% close rate. The bottleneck Anthropic names in its post — humans can’t verify and patch fast enough — is one its own pipeline is actively widening.
curl maintainer Daniel Stenberg, given pre-release Mythos access, was blunt:
The big hype around this model so far was primarily marketing.
Mythos found one genuine low-severity bug in 176k lines of curl, alongside false positives and previously known issues 14. Stenberg’s broader complaint is that credible-looking AI reports are pushing curl toward 50–60 CVEs in 2026, 4–5× historical norms, against the same volunteer triage budget. “Active defense” requires somebody on the receiving end with bandwidth to act.
Who’s not in the room
The governance critique lands harder than the technical one. ProMarket’s legal analysis labels Glasswing the “AI Avengers” and argues that a private consortium of incumbents holding exclusive access to a frontier defensive model has the structural shape of an antitrust problem — gatekeeping a security baseline behind vendor selection 15. The geography reinforces it: Anthropic has categorized China as “adversarial” and blacked out Greater China including Hong Kong entirely 16, while Indian firms outside the cohort face 60–90 day patch windows against minute-scale exploit generation, what Economic Times calls a “kill zone for the Global South” 17. The 15-country expansion partially answers the exclusion charge, but the selection remains Western-aligned.
Competitive context
Anthropic’s “Mythos-class capabilities within 6–12 months” prediction is, per CyberScoop, already happening. Microsoft’s MDASH multi-model harness scored 88.4% on CyberGym, outperforming Mythos, and OpenAI’s Daybreak ships a tiered “Trusted Access for Cyber” program with looser vetting than Glasswing’s invitation-only model 18. The defensive-lead thesis Anthropic is selling — that scarcity plus curation buys defenders a head start — depends on a moat that benchmarks suggest doesn’t exist.
Takeaway
Glasswing’s expansion is real and the discovery firepower is real. But the load-bearing claim — that putting Mythos in 150 trusted hands hardens global infrastructure — collides with a sub-1% patch rate, an overloaded maintainer base, and competitors already at parity without the consortium model. Anthropic is shipping vulnerability reports faster than the world can absorb them, and calling it defense.
Further reading
Round-ups
GitHub Copilot’s usage-based pricing burns monthly credits in a day
Source: ars-technica-ai
Developers are revolting against the new metered model after some exhausted their entire monthly AI credit allotment within 24 hours. The shift from flat-rate subscriptions reflects the real compute costs of agentic coding tools running long inference chains.
Uber caps employee AI spend after burning yearly budget in 4 months
Source: techcrunch-ai
The clampdown reverses earlier guidance that pushed staff to use AI tools aggressively, with Claude Code among the services driving the overrun. It signals how quickly agentic coding costs balloon even at large enterprises with deep pockets.
Trump signs voluntary AI pre-release review order after industry pushback
Source: the-verge-ai, techcrunch-ai
The executive order creates a voluntary framework for frontier AI companies to share models with the federal government before release, aimed at critical infrastructure cybersecurity. An earlier draft requiring mandatory oversight was narrowed following objections from AI firms.
GitHub’s Kyle Daigle lays out the platform’s agent strategy
Source: latent-space
With Copilot kicking off the agentic coding boom, GitHub is now contending with infrastructure strain from autonomous agents hammering repos. COO Kyle Daigle details how the platform plans to support agent workflows while protecting the developer experience.
Mathematicians sound alarm on AI industry’s push into their field
Source: ars-technica-ai
The International Mathematical Union has endorsed a formal warning about tech industry influence over the profession, citing concerns about AI labs like OpenAI hiring away researchers and steering the direction of mathematical work toward commercial ends.
Nathan Lambert departs Ai2 after Olmo model work
Source: interconnects
Lambert wrapped his final week at the Allen Institute for AI, where he helped build the open Olmo model series. His farewell post reflects on the institute’s role in pushing fully open language models against frontier labs’ closed releases.
Import AI 459 weighs oversight limits and AI extinction-risk pricing
Source: import-ai
Jack Clark’s latest issue covers why AI oversight remains hard in practice, scaling laws applied to protein folding models, and an attempt to put a financial price on the extinction risk posed by advanced AI systems.
Footnotes
-
WindowsForum (Foundry/optionality analysis) — https://windowsforum.com/threads/build-2026-microsoft-mai-models-foundry-control-plane-and-optionality-vs-openai.421932/
↩ ↩2 ↩3Following the October 2025 renegotiation that lifted restrictions on Microsoft developing broad frontier models, MAI-Thinking-1 represents ‘optionality in practice’ — a hedge against OpenAI’s inference costs distributed via Fireworks AI and Baseten to avoid vendor lock-in, though skeptics warn the models may be ‘dead on arrival’ inside Microsoft if they can’t surpass GPT-5.
-
Baseten technical writeup on MAI-Thinking-1 — https://www.baseten.co/blog/mai-thinking-1/
↩ ↩2MAI-Thinking-1 scored 53% on SWE-Bench Pro — at parity with Claude Opus 4.6 (51.9%) but behind GPT-5.4 (59.1%); the related MAI-Code-1-Flash hit 51% while using up to 60% fewer tokens than Claude Haiku 4.5.
-
↩Microsoft is exploiting legal fears to sell its powerful new AI model to businesses — pitching ‘clean room’ training and commercially licensed data as a provenance hedge, though legal experts question what ‘appropriately licensed’ actually covers.
-
Skywork.ai (OpenClaw vs MCP) — https://skywork.ai/skypage/en/openclaw-vs-mcp-ai-agents/2038537173225705472
↩MCP’s schema-injection approach can consume 4x to 32x more tokens than OpenClaw’s CLI-based method, effectively ‘eating the agent’s brain’ by bloating the context window with tool definitions.
-
WindowsForum (Majorana 2 analysis) — https://windowsforum.com/threads/microsoft-majorana-2-2029-scalable-quantum-plan-with-agentic-ai-discovery.421796/
↩Physicists including Sergey Frolov and Henry Legg have called Microsoft’s earlier Majorana data ‘incredibly unconvincing’ and a ‘Rorschach test’; the 2025 Nature paper for Majorana 1 carried an editorial note stating the results did not actually provide evidence for Majorana zero modes.
-
WindowsForum (GitHub Copilot AI Credits backlash) — https://windowsforum.com/threads/github-copilot-ai-credits-usage-billing-hits-june-1-2026-and-sparks-backlash.421370/
↩Some power users reported that their monthly bills, previously capped at $39, could skyrocket to nearly $850 based on early June usage patterns; one developer called the change a ‘bait-and-switch’ as a single complex agentic session can now consume $30 to $40 in just a few hours.
-
Visual Capitalist (enterprise LLM market share) — https://www.visualcapitalist.com/ranked-ai-models-u-s-businesses-pay-for/
↩Anthropic has captured approximately 40% of enterprise LLM spending as of March 2026, surpassing OpenAI’s 27%… Anthropic now wins 70% of head-to-head matchups among businesses purchasing AI services for the first time.
-
Kingy.ai — Sites partner ecosystem analysis — https://kingy.ai/news/ai-launch-radar-openai-sites-what-it-is-why-it-matters-who-can-use-it-specs-and-benchmarks/
↩OpenAI has established a ‘Sites partner ecosystem’ including Vercel, Wix, Replit, and Webflow… for internal business dashboards and ‘vibe-coded’ prototypes, OpenAI is now competing for the same user attention that previously went to Wix ADI or Vercel’s v0.
-
City A.M. — Altman walk-back — https://www.cityam.com/delighted-to-be-wrong-sam-altman-changes-tune-on-ai-job-apocalypse-fears/
↩Sam Altman… admitted he was surprised that entry-level white-collar roles have not been eliminated as quickly as predicted, as firms discover that the ‘human part’ of professional work remains difficult to automate.
-
Inference.net — junior banker reaction — https://inference.net/content/chatgpt-enterprise-pricing/
↩Some analysts report that the technology has made their roles ‘more miserable than ever’… senior bankers, aware of AI’s speed, have doubled workloads and shortened deadlines… firms reduce entry-level hiring—some by up to 66%.
-
The Hacker News — exposed vibe-coded apps — https://thehackernews.com/2026/05/what-2000-exposed-vibe-coded-apps.html
↩A 2026 report by Red Access identified over 5,000 corporate applications built on platforms like Lovable and Replit that were deployed with virtually no authentication, exposing sensitive financial and strategic data to the public internet.
-
VentureBeat — Codex Sites/plugins coverage — https://venturebeat.com/orchestration/openais-codex-update-lets-agents-build-interactive-enterprise-workspaces-via-sites-and-role-specific-plugins
↩GPT-5.3-Codex is silently rerouted to GPT-5.2 when the system detects potential cyber abuse… users argued that being billed for a premium model while receiving lower-tier responses is ‘borderline fraudulent’ and disruptive to complex agentic workflows.
-
AI Weekly — patching bottleneck stats — https://aiweekly.co/alerts/anthropic-mythos-23000-bugs-found-only-75-patched
↩Mythos identified over 23,000 potential vulnerabilities across 1,000 open-source projects… human developers have only successfully remediated roughly 75 of the critical bugs identified.
-
Cybernews — Daniel Stenberg (curl) tests Mythos — https://cybernews.com/security/curl-creator-tests-too-dangerous-mythos-ai/
↩The big hype around this model so far was primarily marketing… [Mythos] identified only one genuine, low-severity vulnerability in curl, alongside several false positives and previously known bugs.
-
ProMarket — antitrust analysis of Glasswing — https://www.promarket.org/2026/04/22/the-antitrust-risks-of-anthropics-project-glasswing-and-the-ai-avengers/
↩The antitrust risks of Anthropic’s Project Glasswing and the ‘AI Avengers’… a private league of corporate giants holding exclusive access to superior security tools could function as a front for an illegal cartel.
-
South China Morning Post — https://www.scmp.com/tech/tech-trends/article/3350987/anthropics-mythos-stoking-cybersecurity-fears-what-does-it-mean-china
↩Anthropic has categorized [China] as an ‘adversarial nation’… no Chinese firms or researchers were invited to the consortium, and the model remains unavailable across Greater China, including Hong Kong.
-
Economic Times (India) — https://economictimes.indiatimes.com/tech/technology/anthropic-mythos-shrinks-vulnerability-exploit-window-indian-companies-at-risk/articleshow/130560442.cms?from=mdr
↩While Mythos can identify and weaponize exploits in minutes, firms in nations like India typically require 60 to 90 days to patch systems… ensuring Western partners gain a defensive head start while the rest of the world remains exposed.
-
CyberScoop — OpenAI Daybreak vs Mythos — https://cyberscoop.com/openai-daybreak-gpt-5-5-anthropic-mythos-cybersecurity/
↩Microsoft’s ‘MDASH’ system recently outperformed Mythos with a score of 88.4% by utilizing a multi-model agentic harness… OpenAI’s Daybreak uses a ‘Trusted Access for Cyber’ program with three tiers.