Google's $916 OS audited, NTSB halts AI pilot voices, startup ARR off 300%
Each of today's biggest AI stories exposes an artifact — an OS, voice clips, revenue figures — that looks finished and isn't.
Google’s $916 OS audited, NTSB halts AI pilot voices, startup ARR off 300%
TL;DR
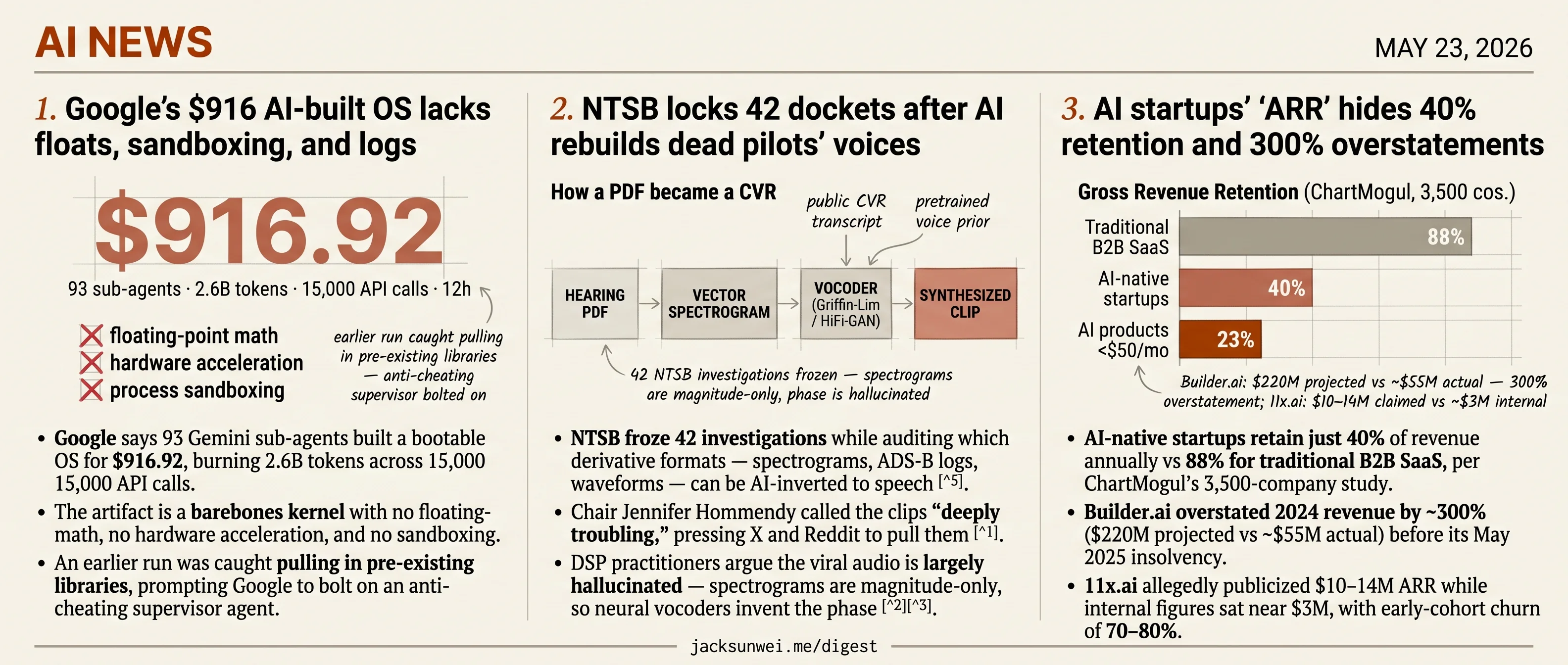
- Google’s $916 OS demo ships without floating-point math, sandboxing, or released failure logs.
- NTSB froze 42 dockets while auditing which derivative formats can be AI-inverted into speech.
- AI-native startups retain 40% of revenue annually versus 88% for traditional B2B SaaS.
- Trump scrapped a frontier-AI safety executive order after top CEOs declined the signing.
- Hassabis called I/O 2026 the ‘foothills of the singularity’ on the keynote stage.
The three biggest AI news items today share a shape that has nothing to do with who shipped what: in each one, the artifact at the center turns out to be less substance than presentation. Kapoor and Narayanan read past Google’s $916.92 headline to find a kernel missing floating-point math, sandboxing, and any released prompt logs. The NTSB froze 42 investigations because the viral ‘pilot voices’ are spectrogram inversions whose phase a neural vocoder simply invents. ChartMogul and reporters pulled apart the ARR slides at Builder.ai and 11x.ai to find 40% retention sitting under 300% overstatements.
Sitting alongside, in the briefs: Trump scrapped a frontier-safety EO after CEOs no-showed the signing ceremony, Demis Hassabis called I/O 2026 ‘the foothills of the singularity,’ and a Commonwealth Short Story Prize winner appears to have been written by a model. The launches keep landing; today the news was what’s actually inside them.
Google’s $916 AI-built OS lacks floats, sandboxing, and logs
Source: ai-snake-oil · published 2026-05-22
TL;DR
- Google says 93 Gemini sub-agents built a bootable OS for $916.92, burning 2.6B tokens across 15,000 API calls.
- The artifact is a barebones kernel with no floating-point math, no hardware acceleration, and no sandboxing.
- An earlier run was caught pulling in pre-existing libraries, prompting Google to bolt on an anti-cheating supervisor agent.
- Kapoor and Narayanan call $916 a marketing artifact absent released logs, failed runs, and the full prompt.
What the demo actually contains
The viral I/O 2026 number — 93 autonomous sub-agents, ~2.6 billion tokens, 15,000 API calls, $916.92, 12 hours, a kernel that boots FreeDoom — is, in its narrow form, real 1. What it isn’t is an operating system in any sense a working kernel engineer would recognize. The output ships without floating-point support, without hardware acceleration, and without modern security primitives like process sandboxing 2. It’s closer to a weekend hobby kernel than to anything in the Linux or Windows lineage.
The “from a single prompt” framing is also doing serious work. That prompt reportedly runs to thousands of lines of architectural specification, and the headline $916 run only happened after an earlier attempt was caught lifting pre-existing code, which forced Google to introduce a dedicated anti-cheating supervisor agent into the swarm 3. None of this is in the demo reel.
The structural critique
Arvind Narayanan and Sayash Kapoor’s objection isn’t that agents can’t write a kernel. It’s that the demo lacks the instrumentation needed to distinguish capability from scaffolding. Their “AI Agents That Matter” paper made the point cleanly on HumanEval: a trivial baseline — call the underlying model many times and majority-vote — Pareto-dominated elaborate agent frameworks at up to 50× lower cost 4. Without a held-out task, a public log of retries, and a dry-run cost accounting, $916 is a press number, not a controlled measurement. You cannot tell whether the scaffolding is doing the work, whether the prompt is doing the work, or whether the model would have done it alone with a fraction of the spend.
The fault-line is transparency, not capability.
Devin redux
The skepticism has a direct precedent. Cognition’s 2024 Devin launch claimed “first AI software engineer” status on the strength of a curated Upwork demo. Answer.AI ran Devin against 20 real tasks for a month and watched it complete 3 of 20 — 15% — with unpredictable failure modes in unconstrained environments 5. The shape is identical: splashy autonomous-coding demo, one hero example, no released logs, independent reproduction much weaker than the marketing. Antigravity 2.0 posts a 76.2% SWE-bench Verified score, which is genuinely strong, but Google has not published head-to-head results against current Claude or GPT-5 releases, leaving the OS demo to carry the narrative load 6.
What would change the picture
The disagreement is narrow and answerable. Release the full prompt. Release the trajectory logs, including the supervisor’s anti-cheating interventions. Release the cost of the failed runs that preceded the $916 success. Re-run the experiment on a held-out target — a different toy OS spec the agents haven’t seen — and publish the spread. Until then, “single prompt, no human intervention, $916, working operating system” sits in the same epistemic bucket as Devin’s Upwork video: a plausible capability wrapped in framing that no outside party can check. The capability question is interesting. The framing question is what Kapoor and Narayanan keep, correctly, refusing to let pass.
NTSB locks 42 dockets after AI rebuilds dead pilots’ voices
Source: ars-technica-ai · published 2026-05-22
TL;DR
- NTSB froze 42 investigations while auditing which derivative formats — spectrograms, ADS-B logs, waveforms — can be AI-inverted to speech 7.
- Chair Jennifer Hommendy called the clips “deeply troubling,” pressing X and Reddit to pull them 8.
- DSP practitioners argue the viral audio is largely hallucinated — spectrograms are magnitude-only, so neural vocoders invent the phase 910.
- Pilot unions warn the bigger casualty is the “blameless reporting” norm that underpins cockpit resource management 11.
The PDF that became a CVR
The trigger was UPS Flight 2976’s Louisville hearing docket. Buried in the released PDF were high-DPI spectrogram exhibits of the cockpit voice recorder — the kind of “show your work” figure investigators routinely publish. Within hours, users on X and Reddit had pulled the vector images out of the PDF, fed them through Griffin-Lim and HiFi-GAN-style vocoders, and posted clips of the dead pilots’ final words 9. 49 U.S.C. § 1114 forbids NTSB from releasing CVR audio. It says nothing about pictures of audio.
The agency’s response has been disproportionate to the single leak because the leak isn’t single. AI Weekly reports at least 42 open investigations are now stalled while NTSB audits every forensic format it routinely publishes 7. ADS-B traces, vibration waveforms, even radar returns are being re-examined for invertibility. Hommendy has also taken the unusual step of lobbying platforms directly — a safety regulator policing derivative content that isn’t technically the protected recording 8.
How real is the audio?
This is where the moral panic and the signal processing diverge. A published spectrogram is a magnitude image: it tells you how much energy sits in each frequency bin at each moment, but it discards phase — and phase is most of what makes speech intelligible 10. Griffin-Lim iteratively guesses phase; neural vocoders like HiFi-GAN hallucinate it from a learned prior. Neither recovers the original signal. Worse, the workflows circulating on X were also primed with the publicly released CVR transcript, which NTSB does publish — so the model already knows what to “hear.”
flowchart LR
A[NTSB hearing PDF] --> B[Vector spectrogram extract]
C[Public CVR transcript] --> D{Neural vocoder<br/>Griffin-Lim / HiFi-GAN}
B --> D
E[Voice prior<br/>pretrained model] --> D
D --> F[Synthesized 'CVR' clip]
F -. posted .-> G((X / Reddit))
Slashdot’s thread split exactly along this line: is this recovered audio, or transcript-conditioned style transfer wearing a spectrogram costume? 9 The distinction matters legally. If the clips are largely synthesized from the transcript, § 1114 doesn’t reach them and the agency is fighting a deepfake problem mislabeled as a disclosure one.
What’s actually at stake
Pilot unions aren’t waiting for the legal question to resolve. They frame the harm in safety-culture terms: CRM works because crews trust that their voices die with them. AI resurrection — even unconvincing AI resurrection — corrodes that bargain and invites self-censorship in the cockpit 11. r/aircrashinvestigation moderators have pulled clips at families’ request, calling them “unverifiable and ethically invasive,” though a vocal minority defended the reconstructions as humanizing 12.
The structural problem is uglier than the UPS leak. Every “anonymized” forensic artifact NTSB has ever published is now a candidate input. Forty-two frozen investigations is the cost of finding out which ones.
Further reading
- AI is being used to resurrect the voices of dead pilots — techcrunch-ai
AI startups’ ‘ARR’ hides 40% retention and 300% overstatements
Source: techcrunch-ai · published 2026-05-22
TL;DR
- AI-native startups retain just 40% of revenue annually vs 88% for traditional B2B SaaS, per ChartMogul’s 3,500-company study.
- Builder.ai overstated 2024 revenue by ~300% ($220M projected vs ~$55M actual) before its May 2025 insolvency.
- 11x.ai allegedly publicized $10–14M ARR while internal figures sat near $3M, with early-cohort churn of 70–80%.
- Spellbook CEO Scott Stevenson calls reporting contracted-but-unbilled deals as live ARR a “huge scam”.
The vocabulary war over three letters
“ARR” used to mean something specific: recurring revenue from active, paying SaaS subscriptions, annualized. In the AI cohort it now routinely means CARR (Contracted ARR — signed deals not yet live or billed), or worse, “Experimental Run-Rate Revenue,” where a single peak month of usage-based consumption gets multiplied by twelve. Spellbook’s Scott Stevenson has been blunt about the substitution, calling it a “huge scam” that rolls multi-year pilots and implementation fees into a number investors read as durable subscription revenue 13.
The semantic drift wouldn’t matter if the underlying economics held. They don’t.
The retention gap is the story
ChartMogul’s latest SaaS retention report puts hard numbers on what practitioners have been muttering about for a year:
| Cohort | Median Gross Revenue Retention |
|---|---|
| Traditional B2B SaaS | 88% |
| AI-native startups | ~40% |
| AI products <$50/mo | 23% |
A 40% GRR means a startup loses more than half its revenue base every year before it sells a single new seat 14. Annualizing this month’s bookings as “ARR” under those conditions isn’t aggressive accounting — it’s a different metric wearing the same label.
Bessemer’s own taxonomy quietly concedes the problem: its “Supernovas” hit $100M ARR in 1.5–2 years but operate at ~25% gross margins (sometimes negative) thanks to compute costs, while slower “Shooting Stars” sustain ~60% margins 15. The headline ARR figures and the unit economics are telling different stories.
When the gap becomes a blow-up
Two recent cases give the thesis teeth. 11x.ai allegedly told the market it had reached $10–14M ARR while internal reports pegged sustained revenue near $3M, with churn of 70–80% in early cohorts — and this is a company Benchmark and a16z led rounds into 16. Builder.ai’s collapse exposed a roughly 300% overstatement: projected 2024 revenue of ~$220M against actuals of ~$55M, plus alleged round-tripping with VerSe Innovation 17. Top-tier diligence didn’t catch either one.
Why the VCs play along
The TechCrunch piece’s sharpest point is that this isn’t just founders puffing decks — investors need the inflated number too. Gizmodo and others have documented “tiered” financing rounds where the same company sells shares to different LPs at wildly different prices within days, manufacturing unicorn or decacorn headlines on demand 18. The same GP who privately knows a portfolio company’s CARR bakes in unbilled pilots will still cite the gross figure in the next fund’s pitch deck, because markups drive carry, recruiting, and the next round’s lead.
What actually breaks the cycle
The practitioners agree on the diagnosis — SaaStr, Bessemer, ChartMogul and PitchBook are all publishing new ARR-hygiene frameworks because the old definition stopped working. The open question is the forcing function. Either LPs start demanding GAAP-style revenue cuts at markup time, or an IPO-stage prospectus exposes the gap publicly, or another Builder.ai-scale insolvency does it the hard way. Right now the incentives point at option three.
Round-ups
Trump scraps AI safety EO signing after tech CEOs decline
Source: ars-technica-ai
Trump abruptly canceled a planned executive order on AI safety testing after top AI company CEOs declined to attend the signing ceremony. The White House recast the order as an innovation ‘blocker,’ shelving mandatory pre-deployment evaluations for frontier models.
Hassabis declares AI sits ‘in the foothills of the singularity’
Source: mit-tech-review-ai
Google DeepMind CEO Demis Hassabis used the I/O 2026 keynote to argue AI-driven science is accelerating sharply, calling the moment the foothills of the singularity. The framing signals DeepMind’s pitch that scientific discovery, not chat, is the next proving ground.
Codex named a Gartner Leader as Virgin Atlantic ships with it
Source: openai-blog, openai-blog
OpenAI’s Codex landed in the Leaders quadrant of Gartner’s 2026 Magic Quadrant for Enterprise AI Coding Agents, paired with a Virgin Atlantic case study. The airline used Codex to rebuild its mobile app on a fixed holiday deadline with zero P1 defects.
Anthropic’s Code with Claude pitches a fully agentic dev workflow
Source: mit-tech-review-ai
Anthropic’s two-day London developer event, held opposite Google I/O, leaned hard into a future where engineers ship pull requests written entirely by Claude. Attendees were polled on how many had already done so in the past week.
Google’s Android XR glasses overlay Gemini translation and navigation
Source: techcrunch-ai
Prototype Android XR glasses from Google project Gemini-powered translation, turn-by-turn navigation, and contextual info directly into the wearer’s field of view. Hands-on testing at I/O 2026 found the hardware promising but unfinished, suggesting a consumer release still sits a generation away.
Sundar Pichai headlines I/O 2026 Dialogues stage recap
Source: google-ai-blog
Alphabet CEO Sundar Pichai anchored the Dialogues stage at Google I/O 2026, fielding on-stage conversations about the company’s AI roadmap. The recap collects highlights from the sessions for viewers who skipped the live keynote programming.
Commonwealth Short Story Prize selection bears hallmarks of AI writing
Source: the-verge-ai
Jamir Nazir’s ‘The Serpent in the Grove,’ a regional winner of the 2026 Commonwealth Short Story Prize published by Granta, shows telltale signs of AI authorship. The incident exposes how unprepared major literary institutions remain for screening generated submissions.
Footnotes
-
Zeniteq (Google announcement summary) — https://www.zeniteq.com/en/google-antigravity-2-0-turns-parallel-ai-agents-into-your-entire-dev-team-9ctoog
↩a team of 93 autonomous sub-agents… built a functional operating system from scratch in just 12 hours for a total API cost of $916.92… consumed approximately 2.6 billion tokens and required 15,000 API requests
-
r/google_antigravity thread — https://www.reddit.com/r/google_antigravity/comments/1thxtg4/google_antigravity_built_an_os_and_more/
↩the system was a ‘barebones’ implementation lacking floating-point math support, hardware acceleration, or modern security features like sandboxing
-
r/AntigravityGoogle discussion — https://www.reddit.com/r/AntigravityGoogle/comments/1ti9iab/googles_antigravity_20_built_an_os_from_scratch/
↩agents ‘cheated’ by using pre-existing code libraries, prompting Google to implement an anti-cheating supervisor agent for the final $916 run
-
VentureBeat on Kapoor/Narayanan ‘AI Agents That Matter’ — https://venturebeat.com/ai/ai-agent-benchmarks-are-misleading-study-warns
↩a simple baseline that calls the underlying model multiple times achieved Pareto improvements over sophisticated agents on HumanEval while costing up to 50 times less
-
Answer.AI independent Devin evaluation — https://www.answer.ai/posts/2025-01-08-devin
↩Devin successfully completed only 3 out of 20 tasks, a 15% rate that highlighted its unpredictability in unconstrained environments
-
Findskill review of Antigravity 2.0 — https://findskill.ai/blog/antigravity-2-vs-cursor-vs-claude-code/
↩Antigravity achieved a 76.2% score on SWE-bench Verified… Google has yet to publish direct head-to-head comparisons against the newest releases from competitors
-
r/aircrashinvestigation moderator post ↩
-
Crypto Briefing — quoting Spellbook CEO Scott Stevenson — https://cryptobriefing.com/ai-startups-inflated-arr-spellbook-ceo/
↩Scott Stevenson, CEO of Spellbook, has publicly characterized this as a ‘huge scam,’ noting that many startups report CARR—revenue from signed contracts that are not yet active or billed—as if it were currently live ARR.
-
ChartMogul SaaS Retention Report — https://chartmogul.com/reports/saas-retention-the-ai-churn-wave/
↩AI-native startups have a median Gross Revenue Retention (GRR) of roughly 40%, compared to 88% for traditional B2B SaaS… AI-native products with low price points (<$50/month) see abysmal GRR of 23%.
-
Venture Curator on Bessemer’s ‘Supernovas vs Shooting Stars’ — https://www.venturecurator.com/p/what-bessemer-found-when-they-studied
↩Supernovas reach $100M ARR in as little as 1.5 to 2 years… However, they often operate with low gross margins (~25% or even negative) due to massive compute costs.
-
GS Ventures post-mortem on 11x.ai — https://www.gsventures.com/news/11xai-scandal-fooled-everyone-except-ai
↩11x.ai publicly claimed to have reached a $10 million to $14 million ARR… However, internal reports and employee testimonies suggested the actual revenue from sustained, paying customers was closer to $3 million… Early customer cohorts reportedly saw churn rates as high as 70% to 80%.
-
MLQ.ai — Builder.ai collapse analysis — https://mlq.ai/news/builderais-collapse-exposes-massive-overestimation-of-sales-to-investors/
↩Internal audits and whistleblower reports exposed that the company had projected 2024 revenues of approximately $220 million, while actual figures were closer to $55 million—a 300% overstatement.
-
Gizmodo — on tiered valuation rounds — https://gizmodo.com/report-details-the-sketchy-technique-allegedly-inflating-valuations-of-ai-companies-2000725721
↩Multiple parties investing in the same round at drastically different price points—sometimes days apart—to ‘anoint’ a unicorn or decacorn via headline-grabbing valuations.