Hugging Face's agent glossary makes the harness a first-class layer
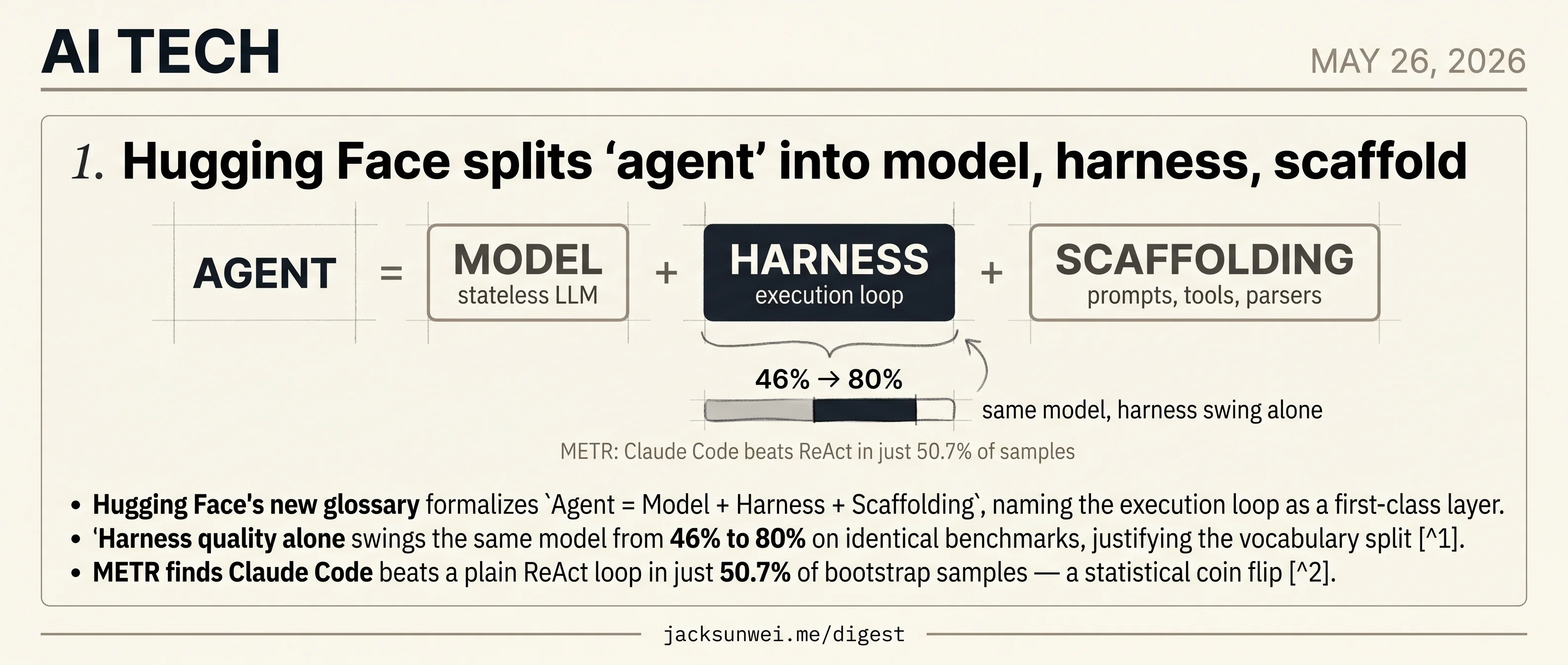
Hugging Face formalizes Agent equals Model plus Harness plus Scaffolding, naming the execution layer where the same model swings 34 points.
Hugging Face’s agent glossary makes the harness a first-class layer
TL;DR
- Hugging Face formalizes
Agent = Model + Harness + Scaffoldingin a new field glossary. - Harness choice alone swings the same model from 46% to 80% on identical benchmarks.
- METR clocks Claude Code beating a plain ReAct loop in just 50.7% of bootstrap samples.
- Sub-agents and skills get clean definitions despite remaining the field’s most contested architectural choices.
For two years, agent has been the field’s load-bearing noun and its emptiest one — used for a one-prompt ReAct loop and for Claude Code in the same sentence. Today Hugging Face ships a glossary that finally splits the term, defining Agent = Model + Harness + Scaffolding and promoting the harness — the execution loop, tool dispatch, retry logic — to a first-class layer with its own vocabulary.
The naming matters because the numbers do. Swapping harnesses moves the same model from 46% to 80% on identical benchmarks, and METR’s bootstrap on Claude Code versus a plain ReAct loop comes in at 50.7% — a coin flip dressed up as a result. Once the variance lives in a layer, the layer needs a name. Today’s piece is what that looks like in practice.
Hugging Face splits ‘agent’ into model, harness, scaffold
Source: huggingface-blog · published 2026-05-25
TL;DR
- Hugging Face’s new glossary formalizes
Agent = Model + Harness + Scaffolding, naming the execution loop as a first-class layer. - Harness quality alone swings the same model from 46% to 80% on identical benchmarks, justifying the vocabulary split 1.
- METR finds Claude Code beats a plain ReAct loop in just 50.7% of bootstrap samples — a statistical coin flip 2.
- Sub-agents and skills get clean definitions despite being the field’s most actively contested architectural choices.
Naming the layer everyone was already building
Hugging Face’s agent glossary does something the field needed: it gives a name to the wrapper code that turns a stateless LLM into something that takes actions. The decomposition is Agent = Model + Harness + Scaffolding. The model is the brain — text in, text out, no memory. Scaffolding is the behavior layer: system prompts, tool descriptions, parsing logic, context management. The harness is the execution engine — the loop that calls the model, runs the tools it requested, and feeds results back.
That third term is the contribution. Claude Code, Codex, and Cursor are harnesses optimized for specific models; Antigravity CLI and Hermes are model-agnostic harnesses. Until now, “agent framework” smushed all three layers into one word, which made it impossible to argue about which layer was carrying the performance.
flowchart LR
M[Model<br/>stateless LLM] -->|text| S[Scaffolding<br/>prompts, tools, parsers]
S -->|structured action| H{Harness<br/>execution loop}
H -->|tool call| E[(Environment)]
E -->|observation| H
H -->|next turn| M
The harness matters — but maybe not the way vendors claim
The empirical case for naming the harness is strong. Practitioners report that identical models swing from 46% to 80% on the same benchmark depending only on harness quality, with up to 14× variation in token cost attributable to the wrapper 1. If that’s true, treating the harness as an afterthought is malpractice.
METR’s long-horizon evaluations complicate the story. The bespoke Claude Code harness beat a simple ReAct loop in only 50.7% of bootstrap samples, and OpenAI’s Codex harness underperformed a generic Triframe scaffold, winning just 14.5% of comparisons 2. The pattern: sophisticated harnesses lower the floor (latency, cost, reliability on short tasks) but don’t raise the ceiling on autonomous endurance, which the model dominates.
Where the glossary papers over live fights
HF defines a sub-agent as “an autonomous entity with its own reasoning loop, called by a primary agent.” Clean definition; openly contested practice. Cognition’s Don’t Build Multi-Agents argues that fragmenting context across sub-agents creates “silent corruption” no post-processing can repair. Anthropic counters with 90.2% win rates for lead-worker patterns — at roughly 15× the token cost of single-agent baselines 3. The glossary entry doesn’t hint that the architecture it names is the field’s most active argument.
Skills vs. tools has the same problem. On SkillsBench, human-curated skills lifted task success by >16%, while model-generated skills often provided no benefit or actively degraded performance 4. “Skill” may be a curation discipline dressed up as an architectural primitive.
What’s missing: failure-mode vocabulary
For a glossary aimed at engineers training agents with RL, the omission of failure-mode terms is conspicuous. Databricks-cited work shows model accuracy collapsing around 32K tokens — practitioners call it “context rot” — long before nominal million-token windows 5. Lost-in-the-middle, tool-call compound error, and context rot are the words engineers actually need when their agent silently degrades at step 40 of a rollout.
Takeaway
HF’s taxonomy is useful pedagogy and probably the cleanest public articulation of the model/harness/scaffold split. Treat it as one synthesis, not a settled standard: Anthropic frames the same territory as workflows-vs-agents along the locus-of-control axis 6, and the most interesting empirical work is busy undermining the assumption that more elaborate scaffolding monotonically helps.
Footnotes
-
MindStudio analysis citing METR — https://www.mindstudio.ai/blog/agent-harness-scaffolding-matters-more-than-model
↩ ↩2The same model can see performance swings from 46% to 80% on the same benchmark depending solely on the quality of its harness.
-
MindStudio — ‘Better model vs better harness’ — https://www.mindstudio.ai/blog/better-model-vs-better-harness-agent-benchmark-score
↩ ↩2METR found Claude Code beat a simple ReAct loop in only 50.7% of bootstrap samples — statistically a coin flip — and OpenAI’s Codex harness actually underperformed a generic Triframe scaffold, winning only 14.5% of the time.
-
Cognition Labs — ‘Don’t Build Multi-Agents’ — https://www.youtube.com/watch?v=8dVCSPXG6Mw
↩Fragmenting context across sub-agents leads to dispersed decision-making and silent corruption that no post-processing can fix; Anthropic counters with a 90.2% win rate for lead-worker patterns but at ~15x the token cost.
-
kau.sh — ‘Claude Skills’ deep-dive — https://kau.sh/blog/claude-skills/
↩On SkillsBench, human-curated skills boosted task success by over 16%, but model-generated skills often provided no measurable benefit or even degraded performance.
-
Firecrawl — context engineering primer — https://www.firecrawl.dev/blog/context-engineering
↩A Databricks study found model accuracy begins to drop significantly around 32,000 tokens, long before nominal million-token limits — a failure mode practitioners call ‘context rot.’
-
Towards Data Science — workflows vs agents — https://towardsdatascience.com/a-developers-guide-to-building-scalable-ai-workflows-vs-agents/
↩Anthropic’s framework draws the line at who decides: workflows orchestrate LLMs through predefined code paths, while agents let the LLM dynamically direct its own processes and termination.