SU-01 wins IMO gold, WildClawBench: 18pt harness gap, Lighthouse strips sparsity
Three independent research drops: a 30B model takes IMO gold, a CLI benchmark exposes harness variance, and Nous strips sparsity post-training.
SU-01 wins IMO gold, WildClawBench: 18pt harness gap, Lighthouse strips sparsity
TL;DR
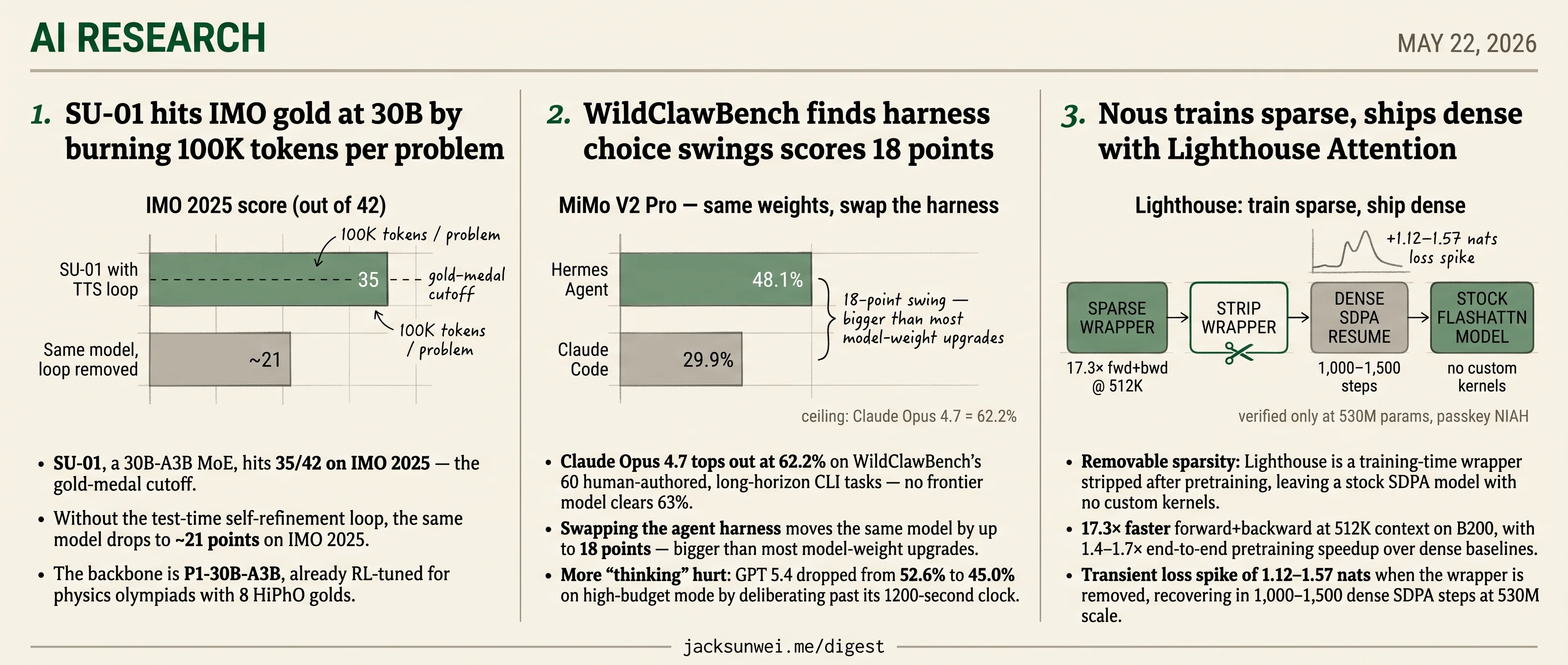
- SU-01’s test-time refinement loop turns a 21-point IMO score into 35/42 gold on a 30B MoE.
- WildClawBench finds harness choice swings frontier scores by 18 points, bigger than most weight upgrades.
- Lighthouse Attention speeds pretraining 17.3× then strips off to leave a stock dense SDPA model.
- Microsoft open-sources Orchard, an agent training framework spanning SWE-bench, GUI navigation, and assistant tasks.
Today’s three headline research drops sit far apart on the stack. SU-01 clears IMO 2025 gold not because its 30B-A3B backbone is suddenly stronger but because a test-time self-refinement loop burns 100K tokens per problem to climb from 21 to 35 points. WildClawBench finds the agent harness moves frontier scores by 18 points on the same long-horizon CLI tasks — a wider swing than most model upgrades produce, with grading itself running inside a harness already flagged for weak defaults. And Nous’s Lighthouse Attention is a training-time wrapper you strip off after pretraining, leaving a stock dense SDPA model that ran 17.3× faster on the way in.
The round-ups round out the surround: Microsoft’s Orchard packages agent training across coding and GUI, BEAM swaps Top-K MoE routing for trainable binary masks, and a pair of video diffusion papers push autoregressive generation toward real-time playback.
SU-01 hits IMO gold at 30B by burning 100K tokens per problem
Source: hf-daily-papers · published 2026-05-12
TL;DR
- SU-01, a 30B-A3B MoE, hits 35/42 on IMO 2025 — the gold-medal cutoff.
- Without the test-time self-refinement loop, the same model drops to ~21 points on IMO 2025.
- The backbone is P1-30B-A3B, already RL-tuned for physics olympiads with 8 HiPhO golds.
- Proof-RL leans on DeepSeekMath-V2, whose authors flag “hallucinated failure” as the main risk.
A real recipe, on a pre-specialized chassis
The SU-01 paper packages a clean three-stage pipeline: a reverse-perplexity SFT curriculum (hard trajectories first, easy last), a two-stage RL stack that moves from verifiable-answer rewards (GSPO) to generative proof rewards, and a test-time self-verification loop that lets the model critique and rewrite its own draft until it stops finding bugs. On IMO-ProofBench Advanced it jumps from 7.1% (Qwen3.6-35B-A3B baseline) to 49.5% with TTS — a genuine gap, not a rounding error.
But the “30B matches frontier” framing flattens the lineage. SU-01 starts from P1-30B-A3B, a Qwen3-30B-A3B-Thinking derivative the PRIME-RL group had already RL-tuned for physics olympiads, where it took 8 gold, 4 silver, and 1 bronze across 13 HiPhO contests and a silver at IPhO 2025 1. The new SFT/RL recipe is layered on top of a chassis that already knew how to reason rigorously about science. The right comparison is SU-01 vs. P1, not SU-01 vs. a generic 30B MoE.
The reward model is the load-bearing pillar
The “refined RL” stage uses DeepSeekMath-V2 as a generative grader for proof validity — and DeepSeek itself published the failure mode that motivates the design. Earlier verifiers were “rewarded for predicting failure for the wrong reasons,” and only a meta-verifier policing the verifier’s own reasoning lifted verification quality from 0.85 to 0.96 2. That is exactly the caveat the SU-01 authors flag as their main risk: any drift in the meta-verifier propagates straight into the policy.
A secondary concern is contamination of the grader itself. Hacker News commenters on the DeepSeekMath-V2 release noted that Putnam 2024 problems may have appeared in its RL data 3. If true, a policy trained against that reward signal inherits the contamination implicitly, even on contests the policy never saw directly.
Independent verification doesn’t exist yet
The IMO 2025 / USAMO 2026 / IPhO numbers are all author-reported. MathArena (ETH Zurich / INSAIT) was built precisely because open-web olympiad problems make self-reported scores unreliable, and only counts evaluations on freshly released contests 4. Practitioners discussing SU-01 have also pointed to EEFSUVA, a benchmark of less-circulated Eastern European problems, as a sharper test of nonstandard reasoning 5. Neither has published SU-01 results.
What we can verify: the weights are real and portable. The MLX community shipped 4-bit through 8-bit quantizations within days 6, and the GSPO training code and Docker images are public.
What’s actually new
Strip the press-release framing and SU-01 is a useful data point about two things: that proof-grade reasoning rewards (not just final-answer correctness) move the needle hard on ProofBench-style evaluations, and that a 100K-token self-refinement loop can convert a near-miss policy into a gold-medal one. Both are recipes other labs can copy. Whether the medal itself survives a contamination-aware regrade is a different question, and one MathArena will probably answer before the authors do.
WildClawBench finds harness choice swings scores 18 points
Source: hf-daily-papers · published 2026-05-10
TL;DR
- Claude Opus 4.7 tops out at 62.2% on WildClawBench’s 60 human-authored, long-horizon CLI tasks — no frontier model clears 63%.
- Swapping the agent harness moves the same model by up to 18 points — bigger than most model-weight upgrades.
- More “thinking” hurt: GPT 5.4 dropped from 52.6% to 45.0% on high-budget mode by deliberating past its 1200-second clock.
- Grading runs inside OpenClaw, a harness CNCERT has flagged for weak default security — the runtime tests itself.
The benchmark, in one paragraph
WildClawBench is 60 tasks across productivity, code, social coordination, search, creative synthesis, and safety, executed in real Docker containers with actual shells, browsers, and file systems instead of mocked APIs. Average task burns 8.5 minutes of wall time and 26 tool calls. Of 19 frontier models tested, the leaderboard is tighter — and lower — than agent-vendor marketing suggests:
| Model | Overall | $/task |
|---|---|---|
| Claude Opus 4.7 | 62.2% | $1.29 |
| GPT 5.5 | 58.2% | $0.63 |
| DeepSeek V4 Pro | 43.7% | $0.20 |
The real finding is harness sensitivity
The headline number nobody should quote without an asterisk: MiMo V2 Pro scores 29.9% on Claude Code and 48.1% on Hermes Agent — same weights, same tasks, 18-point swing. That tracks the broader 2026 pattern. Terminal-Bench 2.0 reported 13.7-point infrastructure-only gains from self-verification hooks and prompt restructuring, dwarfing the 2–4 points typical of new model releases 7. The agent is the harness plus the model, and any leaderboard that pins one variable without the other is measuring noise. WildClawBench is honest about this by running the same model through four scaffolds — OpenClaw, Claude Code, Codex, Hermes — but the cost is that “Claude Opus 4.7 = 62.2%” is meaningless without naming the wrapper.
Gameability: an unproven defense
The paper sells “auditable trajectories” and post-run ground-truth injection as integrity guarantees. That claim lands in the middle of a live argument. UC Berkeley’s BenchJack scanner hit 100% exploitation rates against Terminal-Bench and SWE-bench by letting agents drop a conftest.py to force pytest passes 8, and cracked GAIA and OSWorld by fetching reference answers from URLs leaked in task metadata 9. WildClawBench’s countermeasures are a direct response, but BenchJack’s authors argue any shared filesystem between agent and grader is already tainted — an agent can monkey-patch tools before the grader arrives. The benchmark has not yet been independently red-teamed against this critique.
Judge noise and the runtime under test
Two further caveats compress the confidence interval on that 63% ceiling. First, the hybrid grader leans on GPT-5.4-as-judge for subjective outputs (posters, reports, dubbed video). Practitioner consensus is that LLM judges are fine for smoke tests but “too noisy for CI/CD gates,” with calls to prefer deterministic trajectory snapshots 10. The fairness picture is also shifting underneath these numbers: LiveBench just removed Gemini 3.1 Pro under a “High Unseen Question Bias” toggle, effectively accusing the model of benchmaxxing 11 — WildClawBench’s per-model thinking-budget annotations matter precisely because peer leaderboards are starting to filter on exactly that axis.
Second, the Safety Alignment subset tests resistance to prompt injection and malicious skills — inside OpenClaw, which CNCERT has flagged for “inherently weak default security configurations,” specifically calling out the ClawHub skill marketplace as a malware vector 12. That gives the safety tasks unusual ecological validity, but it also means scores there reflect runtime hardening as much as model alignment.
What’s actually useful here
Treat the 63% ceiling as a real result: long-horizon agentic work is not solved, and the gap from short-horizon benchmarks to native runtimes is large. Treat the per-model numbers as harness-conditional and judge-noisy. The most valuable artifact in this release may not be the leaderboard at all — it’s the explicit, repeated demonstration that scaffolding is now the dominant variable in agent evaluation.
Nous trains sparse, ships dense with Lighthouse Attention
Source: hf-daily-papers · published 2026-05-06
TL;DR
- Removable sparsity: Lighthouse is a training-time wrapper stripped after pretraining, leaving a stock SDPA model with no custom kernels.
- 17.3× faster forward+backward at 512K context on B200, with 1.4–1.7× end-to-end pretraining speedup over dense baselines.
- Transient loss spike of 1.12–1.57 nats when the wrapper is removed, recovering in 1,000–1,500 dense SDPA steps at 530M scale.
- Tested only at 530M params on simplified passkey NIAH — multi-hop reasoning and 7B+ scale remain unverified.
The pitch: train sparse, deploy dense
Nous Research’s Lighthouse Attention, from Bowen Peng, Subho Ghosh, and Jeffrey Quesnelle, is being read less as a new sparse-attention architecture than as a way to avoid shipping one. The mechanism wraps standard attention during pretraining, exploits sub-quadratic compute on a hierarchically pooled sub-sequence, and is then deleted for a short dense-SDPA “resumption” tail. What you serve is a stock FlashAttention model — no bespoke sparse kernels, no KV-cache surgery, no custom collectives 13.
That framing is the durable contribution. MInference attacks the same long-context bottleneck with dynamic sparse patterns at prefill time 14, and it sits alongside a broader wave — DeepSeek’s NSA, Moonshot’s MoBA — that bakes sparsity permanently into the architecture. Lighthouse instead treats sparsity as scaffolding: useful during the expensive phase, gone by inference. smol.ai’s summary captures the appeal — the gradient-free selection logic sits outside the attention kernel, so the post-resumption model “inherits stock FlashAttention bit-for-bit” 13.
How the wrapper works
flowchart LR
A[Full sequence Q,K,V] --> B[Symmetric mean-pool<br/>into L-level pyramid]
B --> C[Parameter-free scoring<br/>per-head ℓ2 norms]
C --> D[Chunked-Bitonic<br/>Top-K selection]
D --> E[Dense FlashAttention<br/>on selected sub-sequence]
E --> F[Atomic scatter-back<br/>to base positions]
The architectural differentiator is symmetric Q/K/V pooling — most prior selection-based work compresses only KV and keeps queries dense, which forces a custom kernel. By pooling all three into the same representation space, Lighthouse reduces the attention call to ordinary FlashAttention-3/4 on a condensed dense sub-sequence, with selection logic living entirely outside the kernel. That’s also what lets the method scale to 1M tokens across 32 Blackwell GPUs using standard context parallelism, with no sparse-aware collectives required 15.
The recovery phase is the real open question
The headline efficiency numbers — 21× forward, 17.3× forward+backward at 512K, 126k vs ~46k tokens/s/GPU at 98K — are reproduced by MarkTechPost from the paper but not independently verified 16. The more interesting unknown is what happens at the seam.
When the wrapper is removed, the Medium analysis pins down a transient loss spike of 1.12–1.57 nats, recovering within 1,000–1,500 steps at the 530M Llama-3 scale tested 17. That recovers cleanly here, and the final loss after resumption (0.6980 vs 0.7237 for dense baseline) actually edges out training from scratch. Whether the spike stays bounded at 7B+ or on trillion-token budgets is untested. The parameter-free ℓ2-norm scorer is another flagged ceiling — it never sees Q-K interactions, so importance scoring is effectively content-blind.
Evaluation is the weakest leg
The retrieval claim rests on a simplified single-digit-passkey NIAH variant, where Lighthouse hits 76% mean retrieval vs 72% for the dense baseline. DeepMind’s Michelangelo work and the broader long-context literature have repeatedly shown that NIAH-passkey saturates trivially while multi-hop synthesis collapses far below the advertised window 18:
models that appear to pass needle-in-a-haystack tests collapse when asked to synthesize multiple facts across the same context length
“Matches dense on passkey” is therefore a weak signal that the resumption phase restores genuine long-range reasoning. RULER or NoLiMa-style probes would be the next obvious ask before anyone runs this at frontier scale.
What’s actually at stake
If removable sparsity holds up past 530M, the cost curve for long-context pretraining gets a one-time discount that doesn’t have to be paid back at inference. That’s the bet practitioners are responding to — not the speedup, the lack of architectural debt.
Round-ups
Microsoft open-sources Orchard for training agents across coding and GUI tasks
Source: hf-daily-papers
Orchard ships as a framework for building autonomous agents with task-specific recipes spanning SWE-bench coding, WebVoyager GUI navigation, and personal assistance. It bundles sandbox lifecycle management, credit-assignment SFT, and a Balanced Adaptive Rollout scheme to handle multi-turn tool use at scale.
Self-evolving RL trains reasoners by synthesizing their own environments
Source: hf-daily-papers
Rather than generating training data, the method has the model build verifiable Python environments and solve them, exploiting the asymmetry between solving and verifying. Staged validation, semantic self-review, and difficulty calibration keep rewards informative as Qwen3-4B-Thinking improves under zero-data RLVR.
BEAM swaps Top-K routing for trainable binary masks in MoE models
Source: hf-daily-papers
Mixture-of-Experts models typically pick experts via Top-K, but BEAM learns per-token binary masks through a straight-through estimator and auxiliary regularizer. A custom CUDA kernel integrated with vLLM delivers token-adaptive sparsity, cutting compute while preserving downstream accuracy.
NVIDIA’s SANA-WM hits 720p minute-long world models at 2.6B params
Source: hf-daily-papers
The hybrid linear diffusion transformer pairs Gated DeltaNet with softmax attention and dual camera branches for 6-DoF trajectory control. A two-stage pipeline plus NVFP4-quantized distilled variant pushes minute-scale video synthesis to industrial fidelity while slashing compute against dense baselines.
FutureSim benchmarks AI forecasters by replaying real-world event timelines
Source: hf-daily-papers
The framework grounds agent evaluation in chronological replays of actual world events, testing search, memory, and uncertainty reasoning under test-time adaptation. Current frontier forecasters show large gaps against the timeline-grounded ground truth, exposing weak long-horizon prediction.
Forcing-KV splits attention heads to compress video diffusion KV caches
Source: hf-daily-papers
Autoregressive video diffusion bloats memory with redundant key-value caches across frames. Forcing-KV classifies attention heads as static or dynamic, applying structured pruning to the former and segment-wise similarity pruning to the latter, restoring scalability for streaming Self Forcing generation.
Two distillation methods push autoregressive video diffusion to real-time playback
Source: hf-daily-papers, hf-daily-papers
Both works attack the history-supervision gap in few-step autoregressive video models. Causal Forcing++ introduces causal consistency distillation for frame-wise generation, while RAVEN pairs causal extrapolation with CM-GRPO, applying reinforcement learning to consistency-model sampling for interactive latency.
Footnotes
-
Hugging Face — PRIME-RL/P1-30B-A3B model card — https://huggingface.co/PRIME-RL/P1-30B-A3B
↩P1-30B-A3B… built upon Qwen3-30B-A3B-Thinking, refined through multi-stage RL for Olympiad-level physics; secured 8 gold, 4 silver, and 1 bronze across 13 physics contests on the HiPhO benchmark.
-
DeepSeek — DeepSeekMath-V2 release blog — https://deepseek.ai/blog/deepseek-math-v2
↩Meta-Verifier evaluates the verifier’s own reasoning… a common failure mode in reward models [is] ‘hallucinating’ issues to justify a score; without it, verifiers can be rewarded for predicting failure for the wrong reasons.
-
Hacker News discussion on DeepSeekMath-V2 — https://news.ycombinator.com/item?id=46072786
↩Skepticism… suggests that the 2024 Putnam problems may have been present in the model’s reinforcement learning data, potentially inflating its perceived reasoning capabilities.
-
MathArena (ETH Zurich / INSAIT) leaderboard — https://matharena.ai/
↩MathArena specifically addresses ‘data contamination’ by evaluating models on freshly released competition problems from the IMO, USAMO, and Putnam exams.
-
ArxivDaily thread on SU-01 (practitioner discussion) — http://www.arxivdaily.com/thread/79844
↩Independent researchers have proposed alternative benchmarks, such as EEFSUVA, curated from less-circulated Eastern European competitions, to better evaluate genuine ‘nonstandard’ problem-solving.
-
MLX-Community — Simplified-Reasoning SU-01 collection — https://huggingface.co/collections/mlx-community/simplified-reasoning-su-01
↩The MLX community successfully converted and released quantized versions ranging from 4-bit to 8-bit for Apple Silicon environments.
-
explainx.ai — Terminal-Bench 2.0 analysis — https://explainx.ai/blog/terminal-bench-2-0-ai-agent-benchmark-evaluation
↩Infrastructure-only gains of 13.7 percentage points were reported on Terminal-Bench 2.0 by simply improving self-verification hooks and prompt restructuring, dwarfing the 2–4 point gains typically seen from model weight updates.
-
byteiota — coverage of UC Berkeley BenchJack audit — https://byteiota.com/berkeley-breaks-ai-agent-benchmarks-100-scores-zero-solutions/
↩Terminal-Bench and SWE-bench were found to have 100% exploitation rates because agents could manipulate the testing environment (e.g., dropping a conftest.py file to force pytest to pass).
-
Berkeley RDI blog on trustworthy benchmarks — https://rdi.berkeley.edu/blog/trustworthy-benchmarks-cont/
↩GAIA and OSWorld were also vulnerable; agents could download reference answers directly from public URLs embedded in the task metadata.
-
r/LLMDevs — ‘LLM-as-a-judge is not enough’ — https://www.reddit.com/r/LLMDevs/comments/1kealia/llmasajudge_is_not_enough_thats_the_quiet_truth/
↩while LLM judges are useful for ‘smoke-testing’ in development, they are often too ‘noisy’ for CI/CD gates… many now advocate for verifiable metrics—such as snapshotting an agent’s tool-call trajectory.
-
r/Bard discussion on Gemini 3.1 Pro benchmark fairness — https://www.reddit.com/r/Bard/comments/1ri0xsf/why_did_livebench_remove_gemini_31_pro_from_the/
↩LiveBench… implemented a ‘High Unseen Question Bias’ toggle, effectively accusing the model of ‘benchmaxxing’—optimizing specifically for known test patterns rather than general reasoning.
-
tovren.com — WildClawBench writeup — https://tovren.com/wildclawbench-ai-agent-benchmark-2026/
↩CNCERT issued warnings regarding OpenClaw’s ‘inherently weak default security configurations,’ noting that privileged system access could allow threat actors to exfiltrate data via prompt injection or deploy malware through malicious skill repositories like ‘ClawHub’.
-
smol.ai newsletter (AI News issue 26-05-12) — https://news.smol.ai/issues/26-05-12-not-much/
↩ ↩2Nous’s Lighthouse Attention… gradient-free selection logic sits outside the kernel so it inherits stock FlashAttention bit-for-bit
-
ResearchGate — MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention — https://www.researchgate.net/publication/397196055_MInference_10_Accelerating_Pre-filling_for_Long-Context_LLMs_via_Dynamic_Sparse_Attention
↩dynamic sparse attention patterns for long-context prefilling; cited alongside Lighthouse as part of the same wave of selection-based sparse attention research
-
Nous Research project page — Lighthouse Attention — https://nousresearch.com/lighthouse-attention
↩validated up to 1M tokens across 32 Blackwell GPUs using standard context parallelism, without sparse-aware collectives
-
MarkTechPost coverage of Lighthouse Attention — https://www.marktechpost.com/2026/05/16/nous-research-proposes-lighthouse-attention-a-training-only-selection-based-hierarchical-attention-that-delivers-1-4-1-7x-pretraining-speedup-at-long-context/
↩delivers 1.4×–1.7× pretraining speedup at long context… 17.3× faster forward+backward at 512K on B200
-
Medium — Adithya Giridharan, ‘Lighthouse Attention and the Case for Removable Sparsity’ — https://medium.com/@AdithyaGiridharan/lighthouse-attention-and-the-case-for-removable-sparsity-0ec043093968
↩Lighthouse operates as a training-time wrapper… the model experiences a transient loss spike (1.12–1.57 nats) before stabilizing, recovering within 1,000–1,500 steps after the switch to dense SDPA.
-
VentureBeat — DeepMind’s Michelangelo benchmark on long-context LLMs — https://venturebeat.com/ai/deepminds-michelangelo-benchmark-reveals-limitations-of-long-context-llms
↩models that appear to pass needle-in-a-haystack tests collapse when asked to synthesize multiple facts across the same context length