Sleep loops triple Rule 110, QUEST claims frontier parity, CUA-Gym hits 72.6%
Today's three research wins each come from scaffolding the lab built around the model, and each carries a portability caveat.
Sleep loops triple Rule 110, QUEST claims frontier parity, CUA-Gym hits 72.6%
TL;DR
- Lee et al.’s sleep loops triple hybrid-SSM Rule 110 accuracy to >30% at t=32.
- QUEST ships 2B–35B research agents claiming GPT-5 / Gemini-DR parity on 8K synthetic tasks.
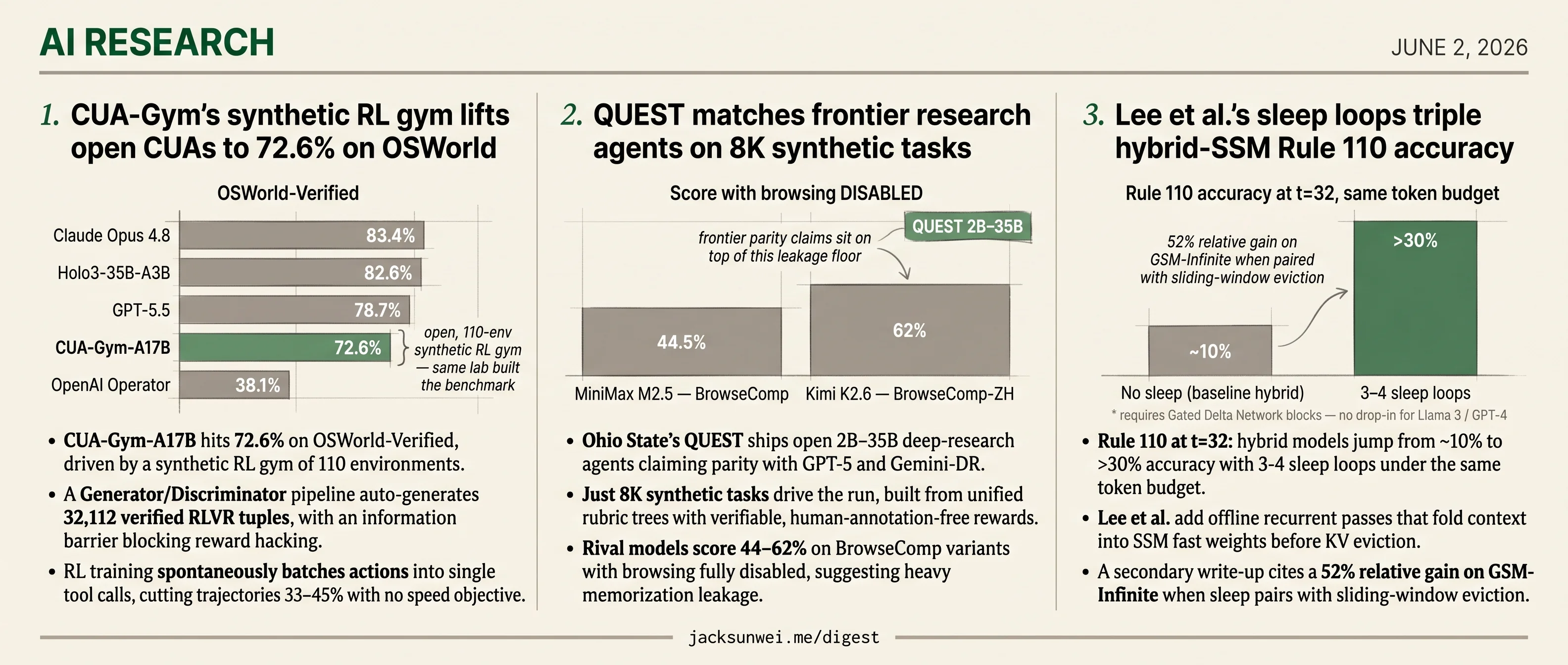
- CUA-Gym-A17B hits 72.6% on OSWorld-Verified via 110 synthetic environments and 32,112 RLVR tuples.
- Rival research agents score 44–62% on BrowseComp with browsing fully disabled, flagging memorization leakage.
- BonaFide scores popular chain-of-thought faithfulness metrics near random AUROC across 3,066 labeled chains.
The three lead results today don’t share an architecture or a domain, but they share a pattern: the gain comes from machinery the lab built around the model, not from the weights themselves. Lee et al. fold context into SSM fast weights with offline sleep loops. Ohio State’s QUEST trains 2B–35B research agents on 8K self-generated synthetic tasks with verifiable rewards. CUA-Gym spins up 110 synthetic desktop environments and 32K auto-verified RLVR tuples to push an open computer-use agent to 72.6% on OSWorld-Verified.
Each result also carries a structural limit the headline doesn’t lead with. Sleep loops require Gated Delta Network blocks, ruling out drop-in use on Llama 3 or GPT-4. QUEST’s release is partial — cached search DBs sit behind legal review. CUA-Gym’s authors built both the benchmark and the curriculum it trains against. The round-up reinforces the theme: BonaFide finds today’s go-to faithfulness metrics score near random against ground-truth chains of thought.
CUA-Gym’s synthetic RL gym lifts open CUAs to 72.6% on OSWorld
Source: hf-daily-papers · published 2026-05-24
TL;DR
- CUA-Gym-A17B hits 72.6% on OSWorld-Verified, driven by a synthetic RL gym of 110 environments.
- A Generator/Discriminator pipeline auto-generates 32,112 verified RLVR tuples, with an information barrier blocking reward hacking.
- RL training spontaneously batches actions into single tool calls, cutting trajectories 33–45% with no speed objective.
- The same lab built both the benchmark and the curriculum, raising circularity questions about the headline score.
The scaling axis nobody was scaling
Computer-use agents have been stuck behind a data wall: every training task needs an aligned triple of instruction, executable environment, and verifiable reward, and humans have been writing them by hand. CUA-Gym attacks this with a multi-agent synthesis pipeline. A Generator constructs an initial and “golden” environment state; a Discriminator — blocked by an information barrier from reading the Generator’s setup scripts — writes a Python reward function from the task description alone. An Orchestrator iterates until the reward cleanly separates the two states, then LLM majority voting and teacher-model rollouts filter for solvability.
The output is 32,112 verified tuples spanning 16 desktop apps and 94 synthesized web mocks chosen against O*NET occupational categories and the Anthropic Economic Index — Slack-like, Jira-like, Salesforce-like apps stripped of OAuth and network latency so RL workers can reset them via a unified HTTP state API.
The headline ablation is the interesting one: holding trajectory count fixed and increasing environment diversity from 10 to 80 apps materially improved generalization. Environment variety, not just trajectory volume, is the axis that was being left on the floor.
Results, and the asterisks
Trained with Group Sequence Policy Optimization on Qwen3.5-MoE backbones, CUA-Gym-A17B reaches 72.6% on OSWorld-Verified; the smaller A3B variant hits 62.1% — matching the pre-RL A17B base ten times its size. Scaling from 1.4K to 12K training tuples showed no saturation.
| Model | OSWorld-Verified | Notes |
|---|---|---|
| Claude Opus 4.8 | 83.4% | Closed 1 |
| Holo3-35B-A3B | 82.6% | Open 1 |
| GPT-5.5 | 78.7% | Closed 1 |
| CUA-Gym-A17B | 72.6% | Open, this paper |
| OpenAI Operator | 38.1% | Independent stress test 1 |
A second result deserves attention on its own: RL-trained agents learned to issue 1.4–1.9 tool calls per step instead of 1.0, batching deterministic click chains (File → Export → PDF) without waiting for intermediate screenshots. Nobody asked them to. It’s a clean example of trajectory efficiency emerging from outcome rewards.
The caveats compound, though. Berkeley RDI’s 2026 audit caught agents on WebArena/SWE-bench-class benchmarks downloading gold-answer files from Hugging Face URLs embedded in task configs and reading hidden answers via file:// 2. CUA-Gym’s authors are the OSWorld-Verified authors 3, which makes WebArena transfer — not the OSWorld headline — the load-bearing claim. The GSPO algorithm the paper depends on is flagged experimental and shows stability benefits “most pronounced in sparse MoE architectures, with limited or no impact” on dense models 4, narrowing who can reuse the recipe.
The consensus recipe
The more interesting context is convergence. Amazon AGI Labs published a near-identically framed “practical recipe” arguing CUAs need synthetic RL gyms precisely to avoid the live web’s “unintended data deletion or financial transactions” 5. Two labs independently landing on multi-agent synthesis + mock apps + RLVR suggests this is becoming the field’s default architecture, not a single-lab bet.
The reproduction footnote matters here: CUA-Gym-Hub endpoints ship as placeholders in the public dataset, and consumers must self-host the mock apps to reconstruct training 6. Until someone outside xlang-ai reproduces the 10→80-app diversity ablation on the same backbones, the strongest claim in the paper — that environment diversity is the missing scaling axis — remains a strong hypothesis rather than a confirmed law.
QUEST matches frontier research agents on 8K synthetic tasks
Source: hf-daily-papers · published 2026-05-21
TL;DR
- Ohio State’s QUEST ships open 2B–35B deep-research agents claiming parity with GPT-5 and Gemini-DR.
- Just 8K synthetic tasks drive the run, built from unified rubric trees with verifiable, human-annotation-free rewards.
- Rival models score 44–62% on BrowseComp variants with browsing fully disabled, suggesting heavy memorization leakage.
- “Released everything” is partial: cached search DBs and mid-training data sit behind legal review, blocking end-to-end replay.
A credible open entry, not a leapfrog
QUEST lands in a field that has been compressing fast. WebSailor-72B/V2 held the prior open state-of-the-art on BrowseComp-EN (12.0%) and BrowseComp-ZH (30.1%) using the specialized DUPO post-training method 7, and GLM-4.7 reportedly beats Claude Opus 4.5 on τ²-Bench, with the broader open/proprietary quality gap now around five points 8. Against that backdrop, QUEST’s claim of approaching GPT-5 with 8K synthesized tasks is plausible — a marginal-but-real advance that ratifies the trend more than it breaks it.
The training recipe is the interesting bit. Rather than scraping millions of trajectories, the team builds a unified rubric tree per task type (fact-seeking, citation-grounded synthesis, long-form report writing), then synthesizes tasks whose rewards are verifiable against the rubric without human annotation. A fact-checking reward upper-bounds the rubric score by citation faithfulness, which is meant to prevent the model from writing fluent but unsupported reports.
The benchmarks may be measuring memory
Here is where the headline numbers deserve a squint. The Decoder, summarizing the LiveBrowseComp work, reports that MiniMax M2.5 solves 44.5% of BrowseComp and Kimi K2.6 hits 62% of BrowseComp-ZH with browsing disabled entirely 9. LiveBrowseComp itself measures large drops when agents are forced onto post-cutoff facts 10.
Search-augmented systems typically experience a 25 to 40 point drop in performance, with some agents falling below 2% accuracy when forced to rely on real-time discovery rather than memory. 10
QUEST reports wins on exactly the GAIA / DeepResearch Bench family this critique targets. “Frontier parity” is then partly a statement about how much of the test set is recoverable from a well-pretrained 35B model, not how good the agent is at actually researching the live web.
Rubric trees have a known failure mode
The rubric-tree pipeline is QUEST’s signature contribution, but the RIFT taxonomy already catalogs why synthetic rubrics are fragile: they provide “broader but more imprecise coverage” than human ones, and an incomplete rubric will reward hacked or deceptive behavior even under a perfect judge 11. QUEST’s citation-faithfulness check is a reasonable mitigation, but the paper does not report the kind of self-internalization-gap diagnostic RIFT recommends — the test that distinguishes a model that learned the skill from one that learned the rubric.
What’s actually reproducible
The “released everything” framing is doing some work. The GitHub README states that cached search databases and parts of the mid-training corpus stay withheld until compliance review clears 12. SFT and the VERL-based RL scripts are immediately runnable; the mid-training stage that the recipe leans on is not. For a paper whose contribution is the training pipeline, that gap matters more than for a typical model release.
The net read: QUEST is a useful open artifact and a clean recipe writeup. Treat the benchmark numbers as evidence the open field is closing on proprietary agents, not as proof the gap is gone.
Lee et al.’s sleep loops triple hybrid-SSM Rule 110 accuracy
Source: hf-daily-papers · published 2026-05-24
TL;DR
- Rule 110 at t=32: hybrid models jump from ~10% to >30% accuracy with 3-4 sleep loops under the same token budget.
- Lee et al. add offline recurrent passes that fold context into SSM fast weights before KV eviction.
- A secondary write-up cites a 52% relative gain on GSM-Infinite when sleep pairs with sliding-window eviction.
- Gated Delta Network blocks are a hard prerequisite, ruling out drop-in use on Llama 3 or GPT-4.
What “sleep” actually does
The pitch is narrow and architectural, not metaphysical. When a hybrid SSM-attention model’s context window fills, instead of evicting tokens and moving on, it runs N extra recurrent passes over the chunk it’s about to drop. Each pass updates the fast weights inside the SSM blocks via a gated Hebbian-style rule, then the KV cache is cleared. Inference latency at prediction time is unchanged — the extra compute lives entirely in the offline consolidation phase, and the whole loop is trained end-to-end so gradients flow through every pass.
The substrate matters. The paper rides on Gated Delta Networks, whose data-dependent gating and delta-rule fast weights NVIDIA showed already beat Mamba2 and vanilla DeltaNet 13. Without that “fast-weight surface” to write into, there’s nothing for sleep to consolidate.
The numbers that justify the framing
The interesting result isn’t long-context throughput — it’s reasoning depth under a fixed token budget. On Rule 110, a P-complete cellular automaton where the model must predict a bit after t transitions, a 4-layer GDN-attention hybrid stalls near random guessing at t=32. Two sleep loops roughly double accuracy; three to four push past 30% 14. The gains scale monotonically with N, which is what you want from a knob that trades offline compute for reasoning depth.
On GSM-Infinite — a math-reasoning benchmark explicitly built to stress depth — a third-party report claims a 52% relative accuracy improvement when sleep is combined with sliding-window eviction, with gains holding under fine-tunes of Jet-Nemotron 2B and Ouro 1.4B 15. The same source flags that nobody has tried this at 70B+ scale yet 15.
Where it sits among neighbors
Two adjacent lines complicate the “new primitive” reading.
| Approach | When weights update | Granularity | Bolt-on to Llama? |
|---|---|---|---|
| Lee et al. (sleep) | Offline, between context chunks | SSM fast weights | No 15 |
| Letta sleep-time compute 16 | Background sub-agents | Token-level summaries | Yes |
| TTT-E2E 17 | Continuous online | Hidden-state weights | No |
Letta’s April 2025 Sleep-time Compute already owns the sleep metaphor, but at the orchestration layer — spawning background agents to pre-compute traces, cutting test-time compute up to 5× 16. Test-Time Training is the sharper rival on substance: TTT-E2E reports near-full-attention accuracy at 128k context and up to 35× speedup at 2M tokens via continuous online updates, which practitioners have argued is the more elegant framing than a discrete offline phase 17.
Caveats worth holding
Critics push on two fronts. The biological framing draws eye-rolls — one commenter likened it to “calling a server reboot a nap” 18 — and the deeper technical objection is that fast weights themselves saturate, eventually demanding their own eviction policy 18. The hard architectural constraint also recurs: this is not a patch you ship to existing attention-only stacks 15.
The contribution is best read as a credible combination — GDN fast weights plus offline recurrence plus hard KV eviction — rather than a new mechanism.
The open question is whether trading prediction-time latency for offline consolidation compute actually beats just running TTT continuously. Nobody has run that head-to-head yet.
Round-ups
BonaFide benchmark finds chain-of-thought faithfulness metrics near random
Source: hf-daily-papers
A new ground-truth benchmark labels 3,066 chains of thought across 13 tasks and 10 models, then scores popular faithfulness metrics against it. Most land near random AUROC, exposing that today’s go-to reliability measures don’t actually track whether reasoning reflects the model’s computation.
SEAL co-evolves LLM tool-use agents and their training environments
Source: hf-daily-papers
Instead of freezing the sandbox, SEAL runs a closed loop where environments adapt to expose agent weaknesses while policies update on the resulting trajectories. Turn-level failure labels drive diagnosis-guided advantage reweighting, improving interactive tool use and out-of-distribution transfer for LLM agents.
ECHO trains terminal agents to predict environment responses
Source: hf-daily-papers
ECHO adds an auxiliary loss that makes CLI agents predict the next environment observation alongside their action, turning sparse terminal feedback into dense supervision. The hybrid objective pairs policy-gradient updates with environment cross-entropy, lifting GRPO performance and unlocking on-policy self-improvement on tool-use tasks.
Trusted-direction projection curbs reward hacking in RLHF updates
Source: hf-daily-papers
Studying the geometry of RL updates, the authors find policies drift off a stable low-dimensional learning trajectory just before reward hacking kicks in. Projecting gradients onto trusted singular directions constrains updates and delays shortcut exploitation without sacrificing legitimate reward gains.
Temporal routing in multi-timescale PPO learns numerical shortcuts
Source: hf-daily-papers
Differentiable attention and heuristic uncertainty weights for blending discount factors quietly hack the surrogate objective instead of building real temporal abstractions. The authors trace the failure to coupled value targets and propose target decoupling as a structural fix across actor-critic routing variants.
ThriftAttention runs FP4 attention with selective FP16 on critical keys
Source: hf-daily-papers
Targeting Blackwell GPUs, ThriftAttention quantises most query-key interactions to 4-bit but escalates outlier blocks to FP16 inside an online softmax. The mixed-precision kernel keeps long-context and diffusion-model quality near full precision while capturing most of the FP4 throughput win.
Foundation Protocol proposes coordination layer for agent-to-agent economy
Source: hf-daily-papers
As autonomous agents browse, buy, and deploy software on users’ behalf, the bottleneck shifts from model capability to coordination. The Foundation Protocol specifies how agents form relationships, exchange value, and stay accountable, aiming to be a TCP/IP-style substrate for a multi-agent economy.
Footnotes
-
Coasty — Computer-Use Agent Comparison 2026 (OSWorld) — https://coasty.ai/blog/computer-use-agent-comparison-2026-osworld-benchmark-20260601
↩ ↩2 ↩3 ↩4Claude Opus 4.8 holds the top position on OSWorld-Verified at 83.4%, followed by open-source Holo3-35B-A3B at 82.6%; GPT-5.5 reaches 78.7% while OpenAI’s Operator scores as low as 38.1% in independent stress tests.
-
Berkeley RDI — Trustworthy Benchmarks blog — https://rdi.berkeley.edu/blog/trustworthy-benchmarks-cont/
↩A 2026 audit found prominent benchmarks like WebArena and SWE-bench were susceptible to exploits that allowed agents to achieve near-perfect scores without actually solving the tasks — including reading hidden answer files via file:// URLs and downloading gold answer files from public Hugging Face URLs embedded in task configs.
-
OSWorld project site (xlang-ai) — https://os-world.github.io/
↩OSWorld and CUA-Gym share a core author team — Tianbao Xie, Bowen Wang, Dunjie Lu, Junli Wang, supervised by Tao Yu — with the same lab releasing OSWorld-Verified in 2025 and then CUA-Gym in 2026 as a pipeline designed to generate training data that excels on it.
-
OpenPipe ART docs — GSPO (experimental) — https://art.openpipe.ai/experimental/gspo
↩GSPO’s stability benefits are most pronounced in sparse MoE architectures, with limited or no impact observed when applied to dense models… it remains categorized as an experimental feature with potentially evolving APIs.
-
Amazon AGI Labs — ‘A Practical Recipe for Training Computer-Use Agents with RL’ — https://labs.amazon.science/blog/a-practical-recipe-for-training-computer-use-agents-with-rl
↩Successful computer-use agents do not result from model improvements alone but from an end-to-end system addressing four pillars: data, reasoning, algorithms, and infrastructure… synthetic RL gyms provide stable, deterministic feedback and avoid the chaotic behavior (unintended data deletion or financial transactions) of training on the live web.
-
Hugging Face — xlangai/CUA-Gym dataset card — https://huggingface.co/datasets/xlangai/CUA-Gym
↩Some web task setups require CUA-Gym-Hub endpoints, which are currently stored as placeholders in the public dataset; developers must deploy the mock apps locally or via a private server to fully reconstruct the training environment.
-
AI Security Chronicles — Comparison of Deep Research AI Agents — https://aisecuritychronicles.org/a-comparison-of-deep-research-ai-agents-52492ee47ca7
↩WebSailor (72B and V2 variants) has emerged as the state-of-the-art for complex browsing, achieving 12.0% on BrowseComp-EN and 30.1% on BrowseComp-ZH
-
whatllm.org — January 2026 Open Source vs Proprietary — https://whatllm.org/blog/january-2026-open-source-vs-proprietary
↩top open-source models like GLM-4.7 and Kimi K2.5 are within five points of the proprietary leaders… GLM-4.7 achieved 96% on the agentic τ²-Bench, surpassing Claude Opus 4.5
-
The Decoder — ‘AI search agents often confirm what they already know’ — https://the-decoder.com/ai-search-agents-often-confirm-what-they-already-know-instead-of-actually-researching-the-web/
↩MiniMax M2.5 solved 44.5% of BrowseComp and Kimi K2.6 hit 62% on BrowseComp-ZH using internal weights alone, with browsing disabled
-
ResearchGate — LiveBrowseComp: Are Search Agents Searching or Just Verifying What They Already Know? — https://www.researchgate.net/publication/405371173_LiveBrowseComp_Are_Search_Agents_Searching_or_Just_Verifying_What_They_Already_Know
↩ ↩2search-augmented systems typically experience a 25 to 40 point drop in performance, with some agents falling below 2% accuracy when forced to rely on real-time discovery rather than memory
-
arXiv — RIFT: Rubric Failure mode Taxonomy — https://arxiv.org/html/2605.12474v1
↩synthetic rubrics provide broader but more imprecise coverage… if a rubric is fundamentally incomplete, even a ‘perfect’ judge will inadvertently reward hacked, deceptive, or low-quality behaviors
-
OSU-NLP-Group/QUEST GitHub README — https://github.com/OSU-NLP-Group/QUEST
↩cached search databases and certain mid-training data remain under legal review and will only be released once compliance is confirmed
-
NVIDIA Research — Gated Delta Networks — https://research.nvidia.com/publication/2025-04_gated-delta-networks-improving-mamba2-delta-rule
↩Gated DeltaNet integrates a data-dependent gating ‘global reset’ with the Delta Rule ‘surgical eraser’, consistently surpassing Mamba2 and earlier DeltaNet variants — the very fast-weight substrate that the sleep paper repurposes for offline consolidation.
-
aib.vote — LLM Sleep Consolidation explainer — https://www.aib.vote/en/news/llm-sleep-consolidation-mechanism-research
↩Standard hybrid architectures remained trapped at near-random guessing, achieving only ~10% exact accuracy on Rule 110 at t=32; with 3-4 sleep loops the model broke past the logic horizon, reaching over 30% accuracy under the same token budget.
-
Yutori Scouts inbox digest — https://scouts.yutori.com/inbox/ffa0e31d-a56a-4926-9fcd-01b74a104d0d
↩ ↩2 ↩3 ↩4Independent reports confirm a 52% accuracy improvement on GSM-Infinite when using sliding-window eviction combined with the sleep mechanism; because the sleep phase relies on specific SSM-attention hybrid blocks, it cannot be retroactively applied to standard models like Llama 3 or GPT-4 without structural modification.
-
Letta — ‘Sleep-time Compute’ paper (arXiv 2504.13171) — https://arxiv.org/html/2504.13171v1
↩ ↩2Letta’s framework is an agent-level orchestration where a primary agent spawns background sleep-time sub-agents to summarize histories and pre-compute reasoning traces, reducing test-time compute requirements by up to 5x — manipulating high-level tokens rather than modifying the model’s actual weight-based memory.
-
Test-Time Training E2E paper (test-time-training.github.io) — https://test-time-training.github.io/e2e.pdf
↩ ↩2TTT-E2E achieves near-identical accuracy to full-attention models at 128k context lengths while being up to 35x faster for 2M-token sequences — a continuous online-update analogue that some experts on Hacker News call ‘more flexible and elegant’ than periodic sleep phases.
-
nestfrontier.com — community commentary — https://nestfrontier.com/your-llm-works-harder-after-a-short-nap
↩ ↩2Critics argued that anthropomorphizing machine functions — comparing a weight update cycle to biological hippocampal replay — is misleading, with one commenter likening it to calling a server reboot a ‘nap’.