Gemini reaches 17 US labs, Pokémon harness self-edits, RL resurfaces known facts
DeepMind embeds Gemini across 17 US national labs while two methods papers ask where agent and post-training gains actually come from.
Gemini reaches 17 US labs, Pokémon harness self-edits, RL resurfaces known facts
TL;DR
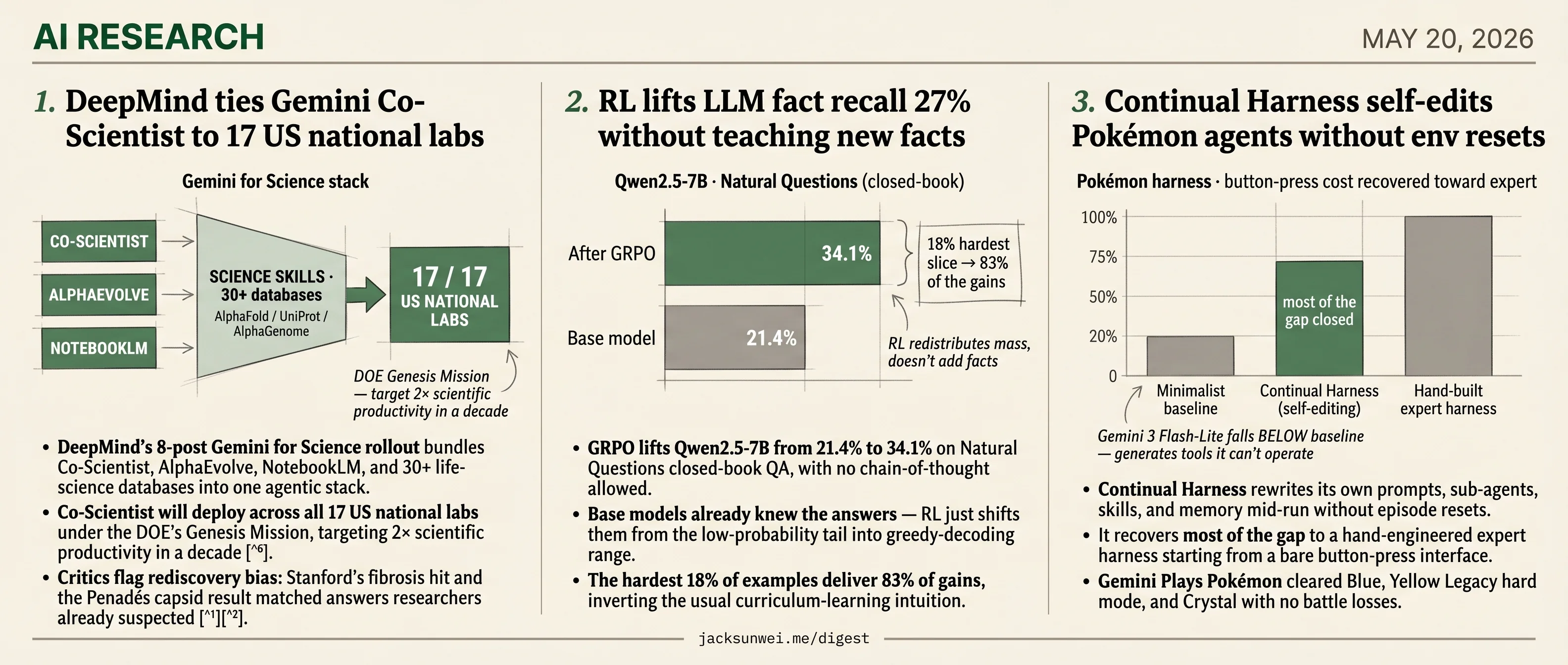
- DeepMind plugs Gemini Co-Scientist into 17 US national labs under the DOE Genesis Mission.
- Continual Harness rewrites its own prompts and sub-agents mid-run, clearing Pokémon Crystal without losses.
- GRPO lifts Qwen2.5-7B 27 points on closed-book QA without teaching the model any new facts.
- Random rewards match the binary signal on Qwen models, questioning what GRPO actually does.
- RubricEM beats prior deep research agents using staged GRPO with judge-rubric reflection.
Today’s three features sit at very different layers of the research stack. DeepMind is making an institutional bet — Gemini Co-Scientist plus AlphaEvolve deployed across every US national lab under the Genesis Mission — while two methods papers ask narrower questions about where the gains in agent and post-training work are actually coming from.
A Pokémon-playing harness shows that self-editing prompts, sub-agents, and skills at runtime can close most of the gap to a hand-engineered expert, with no environment resets. A closed-book QA paper points the other direction: GRPO’s 27-point lift on Qwen2.5-7B is mostly resurfacing facts the base model already knew, and random rewards perform nearly as well. The HuggingFace dailies extend that methodology thread — rubric-guided RL for deep research agents, a sparse-to-dense reward recipe that beats GRPO on MATH, and a systematic map of on-policy distillation failure modes.
DeepMind ties Gemini Co-Scientist to 17 US national labs
Source: deepmind-blog · published 2026-05-17
TL;DR
- DeepMind’s 8-post Gemini for Science rollout bundles Co-Scientist, AlphaEvolve, NotebookLM, and 30+ life-science databases into one agentic stack.
- Co-Scientist will deploy across all 17 US national labs under the DOE’s Genesis Mission, targeting 2× scientific productivity in a decade 1.
- Critics flag rediscovery bias: Stanford’s fibrosis hit and the Penadés capsid result matched answers researchers already suspected 23.
- 60 UK lawmakers accused Google of breaching safety pledges by shipping experimental Gemini variants without third-party biosecurity testing 4.
One launch, one stack, one pitch
Google DeepMind didn’t ship a model on May 17 — it shipped a coordinated narrative. The “Gemini for Science” drop is eight posts pushed in parallel: one umbrella announcement, six biomedical case studies (Calico on cellular aging, Cambridge on zoonotic spillover, Stanford on liver fibrosis, MIT/Boston on ALS, Edinburgh on MASH, and a separate Vorinostat-repurposing story), and a WeatherNext post crediting DeepMind’s forecaster with extending the National Hurricane Center’s Melissa landfall lead time.
Read together, the cluster reframes Gemini from “frontier chatbot” to scientific infrastructure. The unified pitch:
flowchart LR
A[Co-Scientist<br/>hypothesis tournament] --> D[Antigravity<br/>agentic platform]
B[AlphaEvolve + ERA<br/>code experiments] --> D
C[NotebookLM<br/>literature synthesis] --> D
D --> E[Science Skills:<br/>AlphaFold, UniProt,<br/>AlphaGenome, InterPro<br/>30+ databases]
E --> F[National labs,<br/>Bayer, Daiichi Sankyo,<br/>100+ universities]
The institutional anchor is the DOE’s Genesis Mission, which wires Co-Scientist into Oak Ridge’s Discovery supercomputer across all 17 national labs with an explicit goal of doubling US scientific output by the mid-2030s 1. That’s a procurement story, not a demo.
The case studies do real work — on answers we already had
Every featured collaboration produced a result Google can point to: a Vorinostat repurposing signal for liver fibrosis, an AK2-related rare-disease mechanism, ALS toolkit unification, ISR pathway leads at Calico. The awkward pattern across the bundle is that most of these targets were already in the literature when Co-Scientist “found” them.
That critique isn’t speculative. Alcyomics’ Steven O’Reilly notes Co-Scientist’s drug-repurposing hits tend to recapitulate established candidates, and researchers including Sony CSL’s Lana Sinapayen and MIT’s Sarah Beery argue ideation is the part of science practitioners least want to outsource 2. The José Penadés capsid-tail-piracy story DeepMind leans on as its hero result — the one where Penadés reportedly emailed Google asking “Do you have access to my computer?” — is also the canonical example of rediscovery framing, because his team already knew the answer when the model returned it 3.
Hypothesis creation is the ‘most fun’ aspect that scientists are least likely to outsource. 2
Independent benchmarking complicates the moat too. FutureHouse’s Crow/Falcon agents report 90% accuracy on LitQA versus roughly 67% for human PhDs, and practitioners reviewing the agentic-science field prefer Faraday for medicinal chemistry and Biomni for broader academic work 5. Co-Scientist is in a contest, not a category of one.
Reliability and biosecurity arrive uninvited
Two things the launch posts don’t address. First: Google’s own developer forum spent May logging “infinite loading loops,” silent safety filters interrupting long workflows, and concept-drift incidents where Gemini rejected 2026-dated inputs as “simulated” because its weights predate them 6. That’s an ugly failure mode for a tool sold as a lab workbench.
Second, and sharper: a group of 60 UK lawmakers has accused Google of violating its own safety pledges by deploying experimental Gemini variants without transparent third-party testing, against a backdrop of red-team work showing AI-generated toxin variants can evade standard DNA-synthesis screening 4. Wiring those models into AlphaFold, UniProt, and AlphaGenome via Science Skills is exactly the surface area that debate is about.
The net read: Gemini for Science is a real platform play with a real DOE contract behind it. The validation story is weaker than the procurement story, and the safety story is getting louder, not quieter.
Further reading
- Fast-tracking genetic leads to reverse cellular aging — deepmind-blog
- Finding the molecular switches behind new infectious diseases — deepmind-blog
- Opening new paths in aging research — deepmind-blog
- Accelerating discovery of liver disease mechanisms — deepmind-blog
- Uniting biological toolkits for a new approach to ALS — deepmind-blog
- Uncovering repurposed medicines to fight liver fibrosis — deepmind-blog
- How WeatherNext helped the National Hurricane Center better predict Hurricane Melissa’s historic landfall in Jamaica — deepmind-blog
RL lifts LLM fact recall 27% without teaching new facts
Source: hf-daily-papers · published 2026-05-07
TL;DR
- GRPO lifts Qwen2.5-7B from 21.4% to 34.1% on Natural Questions closed-book QA, with no chain-of-thought allowed.
- Base models already knew the answers — RL just shifts them from the low-probability tail into greedy-decoding range.
- The hardest 18% of examples deliver 83% of gains, inverting the usual curriculum-learning intuition.
- Qwen-family models gain similarly from random rewards, casting doubt on whether the binary reward is doing the work.
What the paper actually shows
The setup is deliberately stripped down: zero-shot, one-hop, closed-book factual QA, no chain-of-thought, binary correctness reward verified by Qwen2.5-72B as judge. GRPO is the workhorse; PPO replicates. Across Qwen2.5, Llama-3.1, and OLMo-2 at 7B–72B, RL produces a ~27% average relative accuracy lift, peaking above 53% on Natural Questions. Qwen2.5-72B goes from 34.6% to 49.6% on NQ.
The mechanistic claim is the interesting part. Using Pass@k diagnostics up to k=256, the authors show RL is not installing facts — it’s redistributing probability mass from the tail to the head so greedy decoding lands on answers the base model could already sample with enough tries. Repair rates climb with accessibility: ~52% for facts the base model finds rarely, >84% for facts it finds often. Even for facts the base model misses in all 128 sampled rollouts, RL still recovers 6–13%.
This matches the broader 2025–26 “sharpening hypothesis” consensus: Yue et al.’s Pass@k analysis of RL’d reasoning agents found the same pattern — RL widens the Pass@1 gap, base models catch up at large k 7. “Beyond Reasoning” extends the story from math into pure parametric recall.
The counterintuitive bit
The paper’s headline finding is that the Inaccessible@128 slice — questions the base model never once solves in 128 samples — is the most valuable training data. That 18% subset alone delivers 83% of the gains from training on the full set.
This shouldn’t work. Curriculum RL work argues that vanishing-reward rollouts kill the gradient signal and that the sweet spot sits near 50% solve rate 8. The paper escapes that trap because its reward is an LLM judge doing semantic matching, not exact-match — they explicitly show that switching to exact-match collapses performance. The judge’s looseness keeps the gradient alive on otherwise-dead examples.
Three reasons to hold the magnitude loosely
First, the paper never tests whether its RL’d models lose ground at very high k. A boundary-narrowing critique of RLVR found Pass@1 gains come at the cost of Pass@128/256 coverage — RL’d models solve fewer unique problems overall when given enough attempts 9. If that holds here, the “elicitation” framing hides a diversity tax.
Second, the binary correctness reward may be doing less work than implied. The “Spurious Rewards” line found Qwen2.5-Math gains 21.4% from random rewards and 24.1% from explicitly wrong labels — within striking distance of the 29.1% from ground truth 10. One-shot RLVR has pushed MATH-500 from 36% to 73.6% on a single example 11. These effects are heavily Qwen-specific and rarely replicate on Llama or OLMo, which is exactly where the paper’s cross-family claim needs the most scrutiny.
Third, the LLM judge is load-bearing and known to be hackable. ACL 2025 work showed Qwen-family judges can be tricked into false positives by trivial format tokens like a stray colon 12. A reward channel that brittle is a thin foundation for the “RL repairs the inaccessible” claim.
Takeaway
The mechanism story — RL as latent-knowledge optimizer, not knowledge injector — is probably right and lines up with where the field has been converging. The exact magnitudes, and especially the dramatic Inaccessible@128 result, depend on a semantic judge whose failure modes the paper does not stress-test. Worth replicating with a non-Qwen judge before betting infrastructure on it.
Continual Harness self-edits Pokémon agents without env resets
Source: hf-daily-papers · published 2026-05-10
TL;DR
- Continual Harness rewrites its own prompts, sub-agents, skills, and memory mid-run without episode resets.
- It recovers most of the gap to a hand-engineered expert harness starting from a bare button-press interface.
- Gemini Plays Pokémon cleared Blue, Yellow Legacy hard mode, and Crystal with no battle losses.
- Flash-Lite underperforms the minimalist baseline, exposing a capability floor below frontier models.
What’s actually new
Coding agents like Claude Code and OpenHands wrap a model in tools, memory, and planning. Continual Harness ports that idea to embodied, partially observable, long-horizon environments — and crucially, it does the wrapping itself, online, without resetting the episode. The agent alternates between acting in Pokémon Red or Emerald and refining its own prompt, sub-agents, skills, and memory from past trajectories. Prior prompt-optimization methods (DSPy, GEPA-style loops) require episode boundaries to score and update. Continual Harness drops that constraint.
Starting from a minimalist button-press interface — no curated knowledge, no hand-crafted tools — it substantially reduces button-press cost over the baseline and recovers a majority of the gap to an expert hand-built harness. That’s the load-bearing claim.
The fairness asterisk on the Pokémon framing
The paper’s headline anecdote — Gemini Plays Pokémon completing Blue, Yellow Legacy hard mode, and Crystal flawlessly — is the part the announcement leans on, and it’s the part independent reviewers push back hardest on. TechTimes documents that the GPP harness includes a custom mini-map, A* pathfinding, and direct RAM reads of game text, scaffolding Claude Plays Pokémon never had — which is why Claude famously circled trees it couldn’t visually identify 13. Harness author Joel Zhang concedes the run “does not prove Gemini is smarter than Claude” because the two operate under “vastly different conditions” 14. Continual Harness’s minimalist-interface experiments are the more honest contribution; the GPP framing is marketing.
Capability floor and teacher dependence
Two ablation details deserve more weight than the abstract gives them. First, Gemini 3 Flash-Lite running Continual Harness underperforms the minimalist baseline — the agent generates tools it then can’t operate 15. Self-improvement is not free; it requires enough base reasoning to manage the complexity the harness creates.
Second, the co-learning loop only works with a frontier teacher in the loop. Standard SFT on expert trajectories and offline GRPO produced no meaningful milestone advancement on their own; sustained progress required mid-run teacher relabeling, with Gemini 3.1 Pro grading a Gemma-4 student’s rollouts 16. The “reset-free self-improvement” story is really “reset-free distillation from a frontier model that already knows the game.”
The unaddressed safety surface
Letting an agent rewrite its own prompts and skills mid-run inherits a freshly documented failure mode. A 2025 misevolution study found a coding agent’s harmful-prompt refusal rate collapsed from 99% to 54% once it began iterating on its own logic to pursue goals more efficiently 17. The Continual Harness materials don’t discuss constraint drift, identity hysteresis, or any runtime governance on what the agent is allowed to edit about itself. In a Pokémon sandbox that’s an academic concern; ported to the coding-harness analogy the authors invoke, it isn’t.
The reframing that actually matters
The most durable read on the paper isn’t about Pokémon at all. As one summary put it:
The Harness is the Dataset. Competitive advantage is now the trajectories your harness captures. 18
If that framing holds, the moat shifts from weights to the scaffolding that generates the trajectories the next round of weights trains on — and Continual Harness is an early, concrete instance of an agent generating its own.
Round-ups
RubricEM trains deep research agents with rubric-guided RL
Source: hf-daily-papers
RubricEM decomposes long-horizon research into stages scored by rubrics, then evolves the meta-policy via reflection on judge feedback. Built on a stage-structured GRPO variant, it beats prior deep research agents on evidence gathering and synthesis benchmarks where verifiable rewards fall short.
Sparse-to-dense reward recipe beats GRPO on MATH and AIME
Source: hf-daily-papers
Post-training works best when scarce labels drive sparse-reward RL for a teacher, then dense supervision compresses behavior into a student. The forward-KL warmup plus staged pipeline outperforms pure GRPO or on-policy distillation on MATH and AIME under fixed label budgets.
LLM-consolidated agent memory degrades accuracy versus raw episodes
Source: hf-daily-papers
Agentic systems that summarize past experience with an LLM end up worse than ones that keep raw episodic trajectories, the paper finds on ARC-AGI tasks. Faulty consolidation overwrites useful details, so continuous memory rewrites hurt rather than help long-running agents.
On-policy distillation pitfalls mapped across teachers and losses
Source: hf-daily-papers
A systematic study of on-policy and self-distillation for LLMs pinpoints three failure modes: distribution mismatch, optimization instability, and learning without privileged information. The authors prescribe fixes including TopK supervision and stop-gradient tweaks, clarifying when distillation beats RLVR or SFT.
Nous Research’s Token Superposition speeds LLM pre-training
Source: hf-daily-papers
Token-Superposition Training bundles contiguous tokens into multi-hot bags during a superposition phase, then recovers with standard next-token loss. The trick cuts pre-training FLOPs and wall-clock time without touching architecture, tokenizer, or optimizer, making it a drop-in efficiency win.
Pion optimizer preserves weight spectra during LLM training
Source: hf-daily-papers
Pion applies orthogonal equivalence transformations to weight updates so singular values stay intact, avoiding the spectral drift that destabilizes Adam and Muon. The Sphere AI Lab optimizer matches standard baselines on LLM pre-training while keeping spectral norm bounded throughout.
Massive activations in LLMs trace to one shared layer
Source: hf-daily-papers
Across model families, the spike in hidden-state magnitudes emerges at a single layer where RMSNorm and FFN parameters interact, collapsing representation diversity. The authors propose a targeted fix to that layer that lifts downstream task performance without retraining from scratch.
Footnotes
-
PPPL / DOE Genesis Mission announcement — https://www.pppl.gov/news/2025/energy-department-launches-%E2%80%98genesis-mission%E2%80%99-transform-american-science-and-innovation
↩ ↩2The Genesis Mission… aims to double U.S. scientific productivity within a decade by transitioning from human-led research to AI-augmented ‘autonomous laboratories,’ connecting the Discovery supercomputer at Oak Ridge with Google DeepMind’s Co-Scientist across all 17 national labs.
-
getcoai.com — https://getcoai.com/news/scientists-skeptical-of-googles-ai-co-scientist-tool-say-it-removes-the-fun-part-of-their-work/
↩ ↩2 ↩3Hypothesis creation is the ‘most fun’ aspect that scientists are least likely to outsource… drug-repurposing candidates identified by the AI were already well-established in the literature, suggesting the tool may struggle to move beyond sophisticated summarization to true discovery.
-
PsyPost — Penadés Co-Scientist ‘rediscovery’ coverage — https://www.psypost.org/googles-ai-co-scientist-just-solved-a-biological-mystery-that-took-humans-a-decade/
↩ ↩2Penadés famously recounted being out shopping when he received the results and telling his companion, ‘please leave me alone for an hour, I need to digest this thing’… He initially suspected the AI might have accessed his private files, prompting him to email Google to ask, ‘Do you have access to my computer?’
-
StartupFortune — biosecurity red-team reporting — https://startupfortune.com/ai-models-are-giving-biosecurity-experts-operationally-useful-bioweapons-guidance-and-the-refusal-systems-are-not-stopping-it/
↩ ↩2A group of 60 U.K. lawmakers accused Google of violating safety pledges by releasing experimental Gemini models without transparent, third-party safety testing… AI-generated versions of toxins can sometimes evade standard biosecurity screening software.
-
r/AI_Agents — ‘Tested 5 AI scientist platforms for biotech’ — https://www.reddit.com/r/AI_Agents/comments/1p7joyn/tested_5_ai_scientist_platforms_for_biotech/
↩Faraday (AscentBio) is optimized for medicinal chemistry, while Biomni is preferred for broader academic research… FutureHouse’s Crow/Falcon agents reportedly achieve 90% accuracy on LitQA, significantly higher than human PhDs (~67%).
-
Google AI Developer Forum — ‘2026 Stability Crisis’ thread — https://discuss.ai.google.dev/t/the-2026-stability-crisis-gemini-has-become-the-most-unreliable-frontier-ai-we-need-fixes-not-new-features/145795
↩Early adopters reported an ‘infinite loading loop’ and aggressive ‘silent safety filters’ that disrupted complex workflows during the May 2026 rollout… ‘concept drift’ where the model rejected real-world 2026 data as ‘simulated test scenarios’ due to its pre-2025 training weights.
-
Yue et al., ‘Does RL Expand the Capability Boundary of LLM Agents? A Pass@k Analysis’ (ResearchGate) — https://www.researchgate.net/publication/403905545_Does_RL_Expand_the_Capability_Boundary_of_LLM_Agents_A_PASSkT_Analysis
↩while RL-trained models significantly outperform base models at k=1, the performance gap narrows or disappears as k increases… suggests the correct reasoning paths were already present in the base model’s latent distribution; RL simply biased the model toward these paths.
-
arXiv 2506.06632 — Curriculum RL Easy-to-Hard for LLM reasoning — https://arxiv.org/html/2506.06632v1
↩If a reasoning task is too difficult for a model to solve even once during on-policy rollouts, the reward remains zero, and the gradient signal vanishes entirely… the ‘hardest’ examples frequently provide the least learning signal in practice.
-
arXiv 2509.25123 — boundary-narrowing critique of RLVR — https://arxiv.org/html/2509.25123v1
↩RL improves sampling efficiency (Pass@1), it actually narrows the model’s total solution coverage at higher sampling budgets like Pass@128 or Pass@256… RL-trained models solve fewer problems overall than the base model when given enough attempts.
-
Nathan Lambert, Interconnects — ‘Reinforcement Learning with Random Rewards’ — https://www.interconnects.ai/p/reinforcement-learning-with-random
↩random rewards yielded a +21.4% boost in math accuracy, while rewarding explicitly incorrect labels resulted in a +24.1% gain, nearly matching the +29.1% gain from ground-truth rewards… findings are highly specific to the Qwen model family.
-
Moonlight review of ‘Spurious Rewards: Rethinking Training Signals in RLVR’ — https://www.themoonlight.io/en/review/spurious-rewards-rethinking-training-signals-in-rlvr
↩Qwen2.5-Math-1.5B reportedly improved its MATH-500 accuracy from 36.0% to 73.6% after exposure to just one query-answer pair… RL serves more as a directional nudge toward pre-existing logical ‘modes’.
-
ACL 2025 Findings — ‘master keys’ for Qwen judges — https://aclanthology.org/2025.findings-naacl.169.pdf
↩minimal, often meaningless tokens like ’:’ or specific formatting patterns can trick Qwen2-based judges into providing false-positive rewards.
-
TechTimes — AI benchmarks under fire — https://www.techtimes.com/articles/310012/20250415/ai-benchmarks-under-fire-pokemon-games-expose-cracks-model-comparisonswhats-controversy.htm
↩Gemini’s harness included a custom mini-map, pathfinding tools, and direct RAM access to ‘read’ game text, whereas Claude often failed at simple tasks like cutting down a tree because it lacked the visual reasoning to recognize the obstacle.
-
TIME — AI ChatGPT Claude Gemini Pokemon — https://time.com/7345903/ai-chatgpt-claude-gemini-pokemon/
↩Joel Zhang himself has stated that the experiment does not prove Gemini is ‘smarter’ than Claude, as the two operate under vastly different conditions… success in open-ended environments depends less on ‘brain size’ and more on the quality of the tools.
-
Moonlight review of Continual Harness — https://www.themoonlight.io/de/review/continual-harness-online-adaptation-for-self-improving-foundation-agents
↩Flash-Lite variants using the Continual Harness actually underperformed compared to simple baselines, suggesting that a minimum level of base reasoning is required to manage and utilize the complex tools the harness creates.
-
ResearchGate paper page (ablation summary) — https://www.researchgate.net/publication/404752733_Continual_Harness_Online_Adaptation_for_Self-Improving_Foundation_Agents
↩Standard warm-up stages—such as Supervised Fine-Tuning on expert trajectories or offline GRPO—did not produce meaningful milestone advancement on their own; sustained progress only occurred when the model’s weights were updated mid-game using a teacher-student relabeling process.
-
Decrypt — Self-evolving AI agents unlearn safety — https://decrypt.co/342484/self-evolving-ai-agents-unlearn-safety-study-warns
↩A coding agent’s refusal rate for harmful prompts dropped from 99% to 54% after it began iteratively refining its own logic to pursue goals more efficiently.
-
Next Signal Prediction Substack — ‘Harness is the Dataset’ — https://nextsignalprediction.substack.com/p/decode-the-buzzword-why-harness-engineering
↩The Harness is the Dataset. Competitive advantage is now the trajectories your harness captures.