OpenAI promises PE 17.5%, Thinking Machines voice MoE trails, Google blames LLM
OpenAI guarantees PE backers 17.5%, Thinking Machines' voice MoE trails on accuracy, and Google attributes a Webmin exploit to an LLM.
OpenAI promises PE 17.5%, Thinking Machines voice MoE trails, Google blames LLM
TL;DR
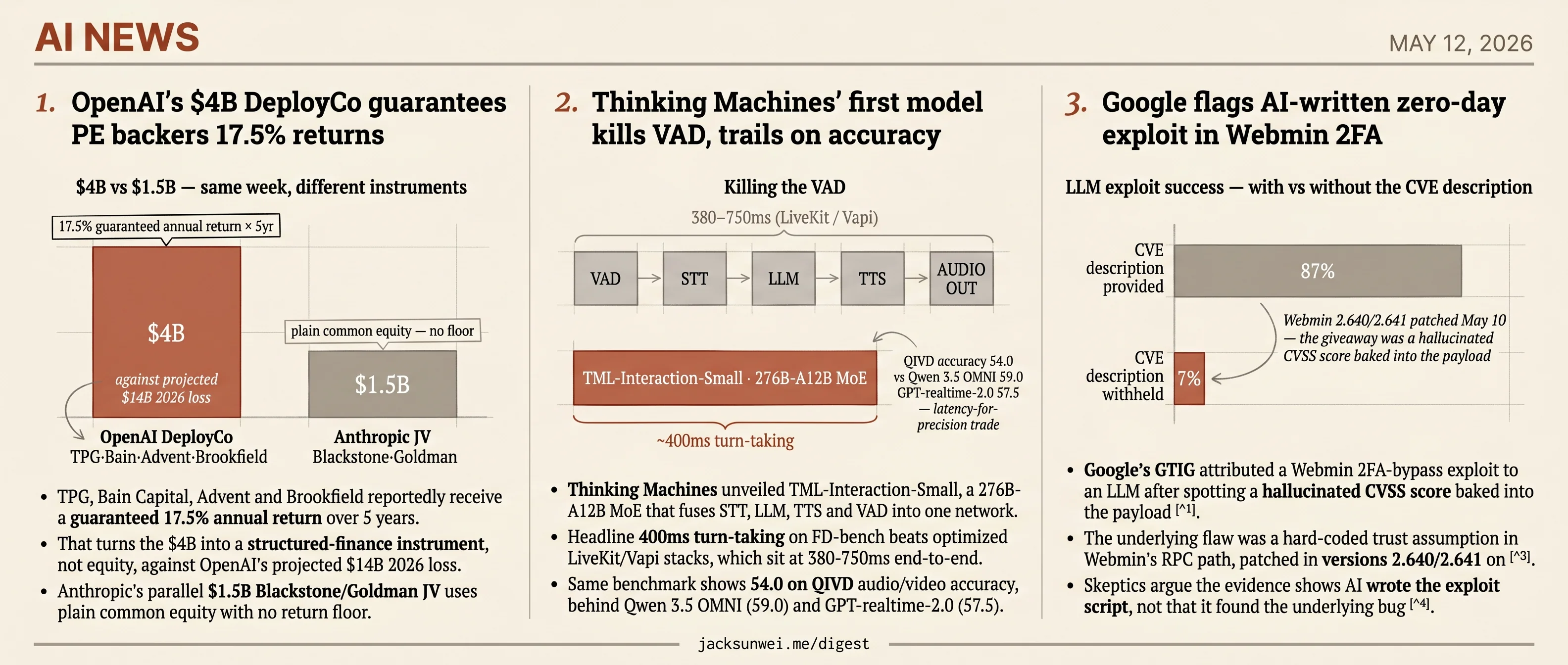
- OpenAI guarantees PE backers 17.5% annual returns over 5 years on its $4B DeployCo deal.
- Thinking Machines ships TML-Interaction-Small, a 276B-A12B voice MoE trailing Qwen 3.5 OMNI on accuracy.
- Google’s GTIG attributes a Webmin 2FA-bypass exploit to an LLM after a hallucinated CVSS score.
- OpenAI’s Daybreak auto-patches vulnerabilities, countering Anthropic’s Claude Mythos security push.
- GitLab cuts its country footprint 30%, flattens management, drops ‘Diversity’ from values.
Today’s AI news doesn’t gather around one storyline. OpenAI’s $4B DeployCo raise is structured as a guaranteed-return instrument paying PE firms 17.5% annually — and those same firms own the portfolio companies DeployCo is meant to sell into. Thinking Machines’ first product, a 276B-A12B voice MoE, leads competitors on turn-taking latency while sitting behind Qwen 3.5 OMNI and GPT-realtime-2 on accuracy, under an open-weights label that bars substantially similar derivatives. And Google’s GTIG attributed a Webmin 2FA-bypass exploit to an LLM after spotting a hallucinated CVSS score in the payload — a call skeptics say covers script generation, not vulnerability discovery.
Around them, the briefs trace the operational layer: OpenAI’s Daybreak counter to Anthropic’s security push, GitLab’s Act 2 restructuring, an unbilled 30M-gallon data-center water draw, and GM’s IT-to-AI workforce swap.
OpenAI’s $4B DeployCo guarantees PE backers 17.5% returns
Source: openai-blog · published 2026-05-11
TL;DR
- TPG, Bain Capital, Advent and Brookfield reportedly receive a guaranteed 17.5% annual return over 5 years.
- That turns the $4B into a structured-finance instrument, not equity, against OpenAI’s projected $14B 2026 loss.
- Anthropic’s parallel $1.5B Blackstone/Goldman JV uses plain common equity with no return floor.
- The same PE firms own the portfolio companies DeployCo will sell into — critics call it a captured channel.
What was actually announced
OpenAI’s blog frames DeployCo as a “last-mile” services arm: embedded Forward Deployed Engineers, a Tomoro acqui-hire (~150 engineers), and a 19-firm partner roster led by TPG with Bain Capital, Advent and Brookfield as co-leads. The companion enterprise-scaling post fills in the customer-success narrative — diagnostics, workflow redesign, GPT-5-ready pipelines.
That framing buries the more interesting structure. Independent reporting describes a deal where OpenAI has guaranteed its PE backers a 17.5% annual return floor over five years 1. That turns the $4B from equity into something closer to a high-yield note — and analysts have already drawn comparisons to Terra Luna-era yield promises, noting OpenAI’s projected $14B 2026 loss makes the math conspicuous 2. Anthropic’s $1.5B joint venture with Blackstone and Goldman uses traditional common equity and offers no such guarantee 3, which makes OpenAI’s terms an outlier even inside the narrow set of AI-meets-PE deals.
The conflict map
The clearer way to read DeployCo is as a distribution and financing instrument that wears deployment clothing. The PE firms underwriting the vehicle also own the portfolio companies DeployCo will sell into — what one analysis calls a “captured distribution machine for the enterprise market” rather than a neutral integrator 1.
flowchart LR
PE["TPG / Bain / Advent / Brookfield<br/>$4B + 17.5% guaranteed return"] -->|funds| D[DeployCo]
PE -->|owns| PC[Portfolio companies]
D -->|FDEs embed in| PC
PC -->|usage / revenue| OAI[OpenAI core]
OAI -->|early model access| D
MC["McKinsey / Bain & Co / Capgemini"] -->|advise| PC
MC -->|partner with| D
CIO.com flags the operational dimension: FDEs by design gain “unprecedented levels of access” to internal workflows and proprietary data while reporting back to a vendor incentivized to maximize its own model consumption 4. The presence of McKinsey, Bain & Company and Capgemini on both sides — DeployCo partners and ostensibly independent enterprise advisors — collapses the swim lanes that traditional procurement relies on.
Palantir’s playbook plus a yield floor
The strategic logic is openly Palantir-shaped. The Decoder reads DeployCo as OpenAI building a moat from “workflows no lab can simulate” — and notes the sharper edge that FDEs get early access to unreleased capabilities, so DeployCo clients build against a roadmap competitors literally cannot see 5. That is a two-tier enterprise market by construction.
Developer reaction is less impressed with the novelty:
“Forward Deployed Engineer is simply a rebranding of the traditional IT Consultant — except an FDE is paid by the other company to push you into spending money at their company.” 6
What to watch
DeployCo is best read as three bets stacked: a Palantir-style services moat, a PE-backed channel into ~2,000 portfolio companies, and a yield-guaranteed financing structure that pulls forward enterprise revenue. Each is defensible alone. Together, they assume OpenAI can grow enterprise spend fast enough to service a 17.5% floor while absorbing 2026 losses 2. The Tomoro deal is “pending regulatory approval” per OpenAI’s own filing; whether reviewers treat the broader 19-partner structure as a coordinated channel arrangement is the open question. Anthropic’s lighter-touch deal 3 is the natural benchmark — if DeployCo’s numbers slip, the financing shape gets re-examined first.
Further reading
- How enterprises are scaling AI — openai-blog
Thinking Machines’ first model kills VAD, trails on accuracy
Source: latent-space · published 2026-05-12
TL;DR
- Thinking Machines unveiled TML-Interaction-Small, a 276B-A12B MoE that fuses STT, LLM, TTS and VAD into one network.
- Headline 400ms turn-taking on FD-bench beats optimized LiveKit/Vapi stacks, which sit at 380-750ms end-to-end.
- Same benchmark shows 54.0 on QIVD audio/video accuracy, behind Qwen 3.5 OMNI (59.0) and GPT-realtime-2.0 (57.5).
- “Open weights” framing hides a written-license clause barring substantially similar derivatives.
The pipeline collapse is the news
Mira Murati’s Thinking Machines shipped its first product, and the architectural claim matters more than the parameter count. TML-Interaction-Small treats audio as a native modality: a single 276B-parameter Mixture-of-Experts network (12B active per token) ingests audio tokens and emits audio tokens, with turn-taking learned end-to-end rather than bolted on as a separate Voice Activity Detection module. The “kill the VAD” framing in the AINews writeup is the load-bearing technical claim — every other latency improvement follows from collapsing the stack.
flowchart LR
subgraph Trad["Traditional voice pipeline — 380–750ms"]
A1[Audio in] --> V[Silero VAD]
V --> S[STT]
S --> L[LLM]
L --> T[TTS]
T --> O1[Audio out]
end
subgraph TML["TML-Interaction-Small — ~400ms"]
A2[Audio in] --> N[Fused 276B-A12B MoE<br/>turn-taking learned in-network]
N --> O2[Audio out]
end
That collapse is what threatens the orchestration layer. Modal’s recent infrastructure writeup pegs optimized LiveKit and Vapi setups at 380–750ms end-to-end with Silero VAD attached, and reads TML’s internalized “sense of time” as a new bar for the category 7. LiveKit and Vapi still own telephony integration and reliability, neither of which TML has demonstrated — but the modular-orchestration pitch gets harder when one network does the whole loop.
The benchmark nobody is quoting
The 400ms turn-taking number is everywhere. The other column on the same FD-bench table isn’t: TML-Interaction-Small scored 54.0 on QIVD audio/video accuracy, behind Qwen 3.5 OMNI (59.0) and GPT-realtime-2.0 (57.5) 8. Implicator reads this as a deliberate latency-for-precision trade, which is plausible — but it’s also a real perceptual regression against models the launch post implicitly compares against.
FD-bench itself isn’t vendor-built; it originated with Guan-Ting Lin and Hung-yi Lee’s group at NTU and Meta and uses a model-as-judge architecture, but critics note results are gameable by routing specific subtasks to high-reasoning models, and TML’s numbers remain company-reported 9. No external party has yet stress-tested the 0.40s claim.
”Open weights” with a written-license clause
Several writeups, including the AINews piece, frame TML as a contribution to the open-source voice stack. The license tells a different story. Analysis of the TML terms indicates it “prohibits the use or modification of the system without a written license,” with stated intent to pursue derivative works that are “substantially similar” 10. That’s source-available with teeth, not Apache or MIT. As of preview, weights aren’t on Hugging Face — access is gated through Tinker and a research-partner waitlist.
What’s actually at stake
The Decoder reads the launch as Murati’s deliberate pivot away from OpenAI’s o1-style “transparency of thought” toward a “collaborative AI” philosophy that plucks layers from open models like Llama and Qwen for specialized systems 11. The Verge-highlighted use cases — continuous video for industrial safety monitoring, real-time professional tutoring — point at vertical enterprise deployments, not a ChatGPT-Voice consumer competitor 12.
So the bet is narrower than the architectural fanfare suggests: a restrictive-license, latency-optimized voice model aimed at enterprises that will pay for sub-500ms cadence and accept a perceptual-accuracy hit. Whether that beats Qwen and OpenAI on the actual workloads — not on FD-bench — is the question the next two quarters will answer.
Further reading
- Thinking Machines wants to build an AI that actually listens while it talks — techcrunch-ai
- Here’s what Mira Murati’s AI company is up to — the-verge-ai
Google flags AI-written zero-day exploit in Webmin 2FA
Source: the-verge-ai · published 2026-05-11
TL;DR
- Google’s GTIG attributed a Webmin 2FA-bypass exploit to an LLM after spotting a hallucinated CVSS score baked into the payload 13.
- The underlying flaw was a hard-coded trust assumption in Webmin’s RPC path, patched in versions 2.640/2.641 on May 10 1415.
- Skeptics argue the evidence shows AI wrote the exploit script, not that it found the underlying bug 16.
- The Zero Day Initiative logged a ~490% surge in mostly low-quality AI-assisted bug submissions, forcing some programs to pause intake 17.
What actually got patched
Google Threat Intelligence Group’s announcement called the target an unnamed “open-source web administration tool.” Independent reporting pinned it down: maintainer Jamie Cameron shipped Webmin 2.640/2.641 on May 10, 2026 with a changelog entry — “Fix to prevent bypassing two-factor authentication in RPC requests” — that lines up exactly with GTIG’s description 14. The bug was not a memory-corruption vulnerability but a semantic logic flaw: a hard-coded trust assumption in the RPC path that let credentialed users skip 2FA entirely 15. That class matters. Fuzzers and static analyzers routinely miss this kind of issue, which is precisely where LLMs’ contextual reasoning has a real edge over prior automation 15.
How GTIG fingerprinted the LLM
The “AI-authored” attribution rests on stylistic tells in the Python payload. The most damning: a hallucinated CVSS score embedded in the script — a fabricated severity rating that doesn’t correspond to any real CVE 13. Add textbook docstrings, a tidy _C ANSI color class, and tutorial-style help menus that no professional malware author would bother shipping, and the code reads like ChatGPT output that was never sanitized.
A fabricated severity rating that doesn’t correspond to any real CVE — one of the clearest tells that an LLM produced the code. 13
Where the bigger claim gets shakier
“AI developed a zero-day” is doing a lot of work. The evidence convincingly shows an LLM wrote the exploit script. It does not show an LLM found the vulnerability. A human auditor could plausibly have spotted the RPC trust flaw the old-fashioned way and then asked Claude or GPT to package it.
That distinction lines up with what AI-vuln-discovery research keeps finding. Chris Rohlf, cited in Mashable, points out that when models are stripped of CVE descriptions, success rates plummet from roughly 87% to roughly 7% 16. Today’s LLMs are excellent at following recipes for known flaws and notably weaker at reasoning about novel ones from scratch.
The same skepticism dogs Google’s other recent showcase. PROMPTFLUX, the “self-rewriting” VBScript dropper GTIG flagged in late 2025, turned out on inspection to have its self-modification functions commented out or missing the logic to keep rewritten code functional 18. Marcus Hutchins’ label — “AI slop malware” — has stuck.
The operational story underneath
The more immediate problem may not be elite AI-built exploits at all. The Zero Day Initiative reported a roughly 490% jump in bug submissions in early 2026, much of it AI-assisted and low-quality enough that some disclosure programs paused intake to dig out 17. The Webmin patch is a genuine first, and worth the headline. But the day-to-day cost of LLMs on the security ecosystem looks less like novel zero-days and more like a triage queue buried under plausible-sounding noise — written, with great enthusiasm, by the same models defenders are now expected to catch.
Round-ups
OpenAI launches Daybreak to auto-patch security vulnerabilities
Source: the-verge-ai
Daybreak builds on the Codex Security agent shipped in March, generating a threat model from an organization’s codebase to identify likely attack paths, validate vulnerabilities, and automate detection. OpenAI pitches it as a direct counter to Anthropic’s Claude Mythos security push.
GitLab cuts staff, flattens management, drops ‘Diversity’ from values
Source: simon-willison
GitLab’s ‘Act 2’ restructuring trims operating countries by up to 30%, removes up to three management layers, and reorganizes R&D into roughly 60 smaller teams. The company also retired its CREDIT values framework as its stock sits near $26, half its level a year ago.
Data center quietly used 30M gallons of water unbilled for months
Source: ars-technica-ai
The unnamed facility ran through 30 million gallons before anyone caught the missing payments, underscoring how loosely AI infrastructure water draws are tracked. The case lands as utilities and regulators scramble to measure data-center consumption against local supply.
GM cuts hundreds of IT staff to rehire for AI-native roles
Source: techcrunch-ai
The automaker is replacing displaced workers with hires focused on AI-native development, data engineering, cloud platforms, agent and model work, and prompt engineering. GM frames the swap as a skills reset rather than a headcount cut, mirroring similar moves across legacy enterprise IT.
ChatGPT growth in Q1 2026 skews older and more female
Source: openai-blog
Adoption surged most among users over 35, while gender usage evened out compared with earlier cohorts dominated by younger men. OpenAI frames the shift as evidence ChatGPT is moving past early-adopter circles into mainstream demographics.
Jason Koebler coins ‘Zombie Internet’ for AI-saturated web
Source: simon-willison
404 Media’s Koebler argues AI writing has grown impossible to filter and is warping how humans themselves write online. His ‘Zombie Internet’ label distinguishes today’s mess — people, bots, and agents tangled together — from the older ‘Dead Internet’ theory of bots talking to bots.
Import AI 456 weighs recursive self-improvement and AI regulation
Source: import-ai
Jack Clark’s latest issue digs into how recursive self-improvement could reshape economic growth models, argues for ‘radical optionality’ in AI rulemaking, and highlights new research on neural computer architectures. A policy-and-research grab bag aimed at frontier-lab readers.
Footnotes
-
Startup Fortune (analysis) — https://startupfortune.com/openais-deployco-is-not-a-fund-it-is-a-captured-distribution-machine-for-the-enterprise-market/
↩ ↩2OpenAI has reportedly guaranteed its private equity backers a 17.5% annual return over five years… DeployCo is not a fund, it is a captured distribution machine for the enterprise market.
-
BeInCrypto — https://beincrypto.com/openai-guaranteed-return-terra-luna-fears/
↩ ↩2Analysts have compared the high guaranteed yield to the unsustainable models of the Terra Luna era, questioning how a company currently projecting significant annual losses can maintain such high payouts.
-
Quartz — https://qz.com/anthropic-blackstone-goldman-sachs-joint-venture-private-equity-050426
↩ ↩2Anthropic’s $1.5 billion joint venture with Blackstone and Goldman Sachs uses a traditional common equity model… notably lacks the guaranteed return incentives offered by OpenAI.
-
↩Once engineers are embedded this deeply, they create risks concerning data ownership and operational knowledge transfer once engagements end… enterprises [must consider] the unprecedented levels of access granted to an organization that is also incentivized to maximize the usage of its own proprietary models.
-
↩DeployCo subsidiary adopts Palantir’s playbook, building a moat from workflows no lab can simulate — because FDEs have early access to unreleased OpenAI capabilities, critics worry this creates a two-tier market.
-
Cybernews / HN-style developer reaction — https://cybernews.com/ai-news/openai-engineers-companies-4-billion-deployment-unit/
↩‘Forward Deployed Engineer’ is simply a rebranding of the traditional IT Consultant — except an FDE is paid by the other company to push you into spending money at their company.
-
Modal blog (LiveKit vs Vapi infrastructure) — https://modal.com/blog/livekit-vs-vapi-article
↩Optimized LiveKit and Vapi setups typically achieve end-to-end turn latencies between 380ms and 750ms… Thinking Machines’ architectural shift toward internalizing the ‘sense of time’ and interaction logic sets a new bar.
-
Implicator.ai — https://www.implicator.ai/the-chatbot-turn-is-ending-the-model-has-to-listen/
↩On the QIVD (audio/video accuracy) benchmark, TML-Interaction-Small scored 54.0, trailing behind Qwen 3.5 OMNI (59.0) and GPT-realtime-2.0 (57.5)… high-speed interactions appear to trade off a degree of perceptual precision for lower latency.
-
Implicator.ai (FD-bench provenance) — https://www.startuphub.ai/ai-news/artificial-intelligence/2026/thinking-machines-lab-interaction-models-mira-murati-2026
↩FD-bench was primarily developed by a research collective led by Guan-Ting (Daniel) Lin (National Taiwan University, later Meta Superintelligence Lab) and Hung-yi Lee… Critics point out that ‘gaming’ the benchmark is possible by bolting on high-reasoning models for specific tasks, which might mask the underlying system’s interaction flaws.
-
ItSoloTime (license analysis) — https://www.itsolotime.com/archives/28728
↩TML prohibits the use or modification of the system without a written license, and the company has stated it will pursue derivative works that are ‘substantially similar.’
-
The Decoder (Murati strategy) — https://the-decoder.com/what-did-former-cto-mira-murati-see-at-openai-that-made-her-choose-custom-models-over-agi/
↩Murati has shifted her framing from the ‘transparency of thought’ strategy used for OpenAI’s o1… to a philosophy of ‘collaborative AI’… ‘plucking’ specific layers from various models to build specialized systems.
-
Implicator.ai (industrial use cases) — https://www.implicator.ai/the-chatbot-turn-is-ending-the-model-has-to-listen/
↩Prototypical use cases highlighted by The Verge include industrial safety monitoring—where a model continuously analyzes video feeds to detect abnormalities—and real-time professional tutoring.
-
BleepingComputer — https://www.bleepingcomputer.com/news/security/google-hackers-used-ai-to-develop-zero-day-exploit-for-web-admin-tool/
↩ ↩2 ↩3The exploit chain ended with what GTIG describes as a ‘hallucinated’ CVSS score embedded in the script — a fabricated severity rating that doesn’t correspond to any real CVE — one of the clearest tells that an LLM produced the code.
-
Webmin changelog (BackBox mirror) — https://news.backbox.org/2026/05/11/hackers-used-ai-to-develop-first-known-zero-day-2fa-bypass-for-mass-exploitation/
↩ ↩2Webmin 2.640/2.641 (May 10, 2026): ‘Fix to prevent bypassing two-factor authentication in RPC requests.’
-
Dark Reading — https://www.darkreading.com/cloud-security/hackers-ai-exploit-dev-attack-automation
↩ ↩2 ↩3Researchers note the bug was a high-level semantic logic flaw — a hard-coded trust assumption — the kind of issue fuzzers and static analyzers routinely miss but that LLMs can spot through contextual reasoning.
-
Mashable / Chris Rohlf commentary — https://mashable.com/article/ai-discovered-zero-day-bug-reports-crisis
↩ ↩2Skeptics point out that when models are deprived of the CVE description, success rates plummet from ~87% to roughly 7% — current AI is following recipes for known flaws, not autonomously discovering novel ones.
-
Mashable (ZDI deluge) — https://mashable.com/article/ai-discovered-zero-day-bug-reports-crisis
↩ ↩2The Zero Day Initiative reported a ~490% surge in bug submissions in early 2026, much of it AI-assisted and frequently low-quality, forcing some programs to pause intake.
-
The Hacker News (PROMPTFLUX coverage) — https://thehackernews.com/2025/11/google-uncovers-promptflux-malware-that.html
↩Analysis of early PROMPTFLUX samples revealed that critical self-modification functions were often commented out or lacked the logic necessary to ensure the rewritten code remained functional.