ChatGPT wires 12,000 banks, PwC trains 30,000 on Claude, arXiv bans AI slop
AI vendors expand into consumer finance and Big Four advisory while arXiv suspends authors caught submitting AI-fabricated papers.
ChatGPT wires 12,000 banks, PwC trains 30,000 on Claude, arXiv bans AI slop
TL;DR
- OpenAI wires ChatGPT into 12,000 banks via Plaid for US Pro users.
- PwC will certify 30,000 staff on Claude after cutting 1,500 US jobs.
- arXiv suspends authors one year for AI-fabricated submissions.
- Greg Brockman takes over all product at OpenAI in a fresh reorg.
- Anthropic’s $1.5B author settlement stalls over a $320M fee dispute.
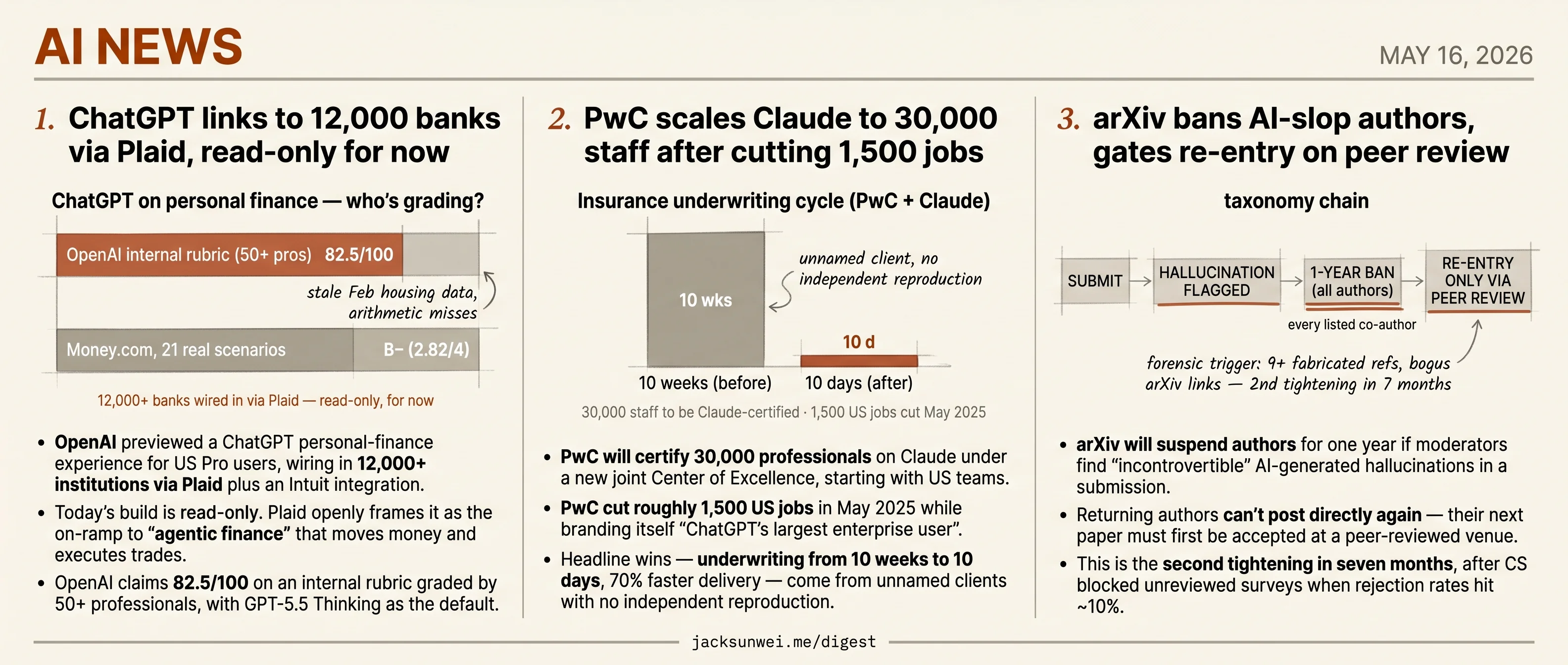
Three institutions wrote new rules today for how AI sits inside trust-dependent work. OpenAI wired ChatGPT into 12,000+ banks through Plaid — read-only for now, but Plaid itself frames the integration as the on-ramp to agentic finance that moves money. PwC scaled Claude to 30,000 professionals under a new joint Center of Excellence, weeks after cutting roughly 1,500 US jobs and as the SEC’s chief accountant warns Big Four firms about vendor entanglement. And arXiv went the other direction: a one-year suspension for authors caught submitting AI-fabricated content, with re-entry gated on peer review.
Around those, the day’s briefs sketch the same split. OpenAI consolidated product under Greg Brockman and pushed fresh GPT-5.5 and Codex case studies at Databricks and Sea, while Anthropic’s record $1.5B author settlement stalled in court over a fee fight. The expansion and the pushback are happening on the same calendar.
ChatGPT links to 12,000 banks via Plaid, read-only for now
Source: openai-blog · published 2026-05-15
TL;DR
- OpenAI previewed a ChatGPT personal-finance experience for US Pro users, wiring in 12,000+ institutions via Plaid plus an Intuit integration.
- Today’s build is read-only. Plaid openly frames it as the on-ramp to “agentic finance” that moves money and executes trades.
- OpenAI claims 82.5/100 on an internal rubric graded by 50+ professionals, with GPT-5.5 Thinking as the default.
- Independent reviewers gave ChatGPT a B- on real finance scenarios, flagging stale market data and arithmetic errors.
- A 30-day deletion promise collides with the NYT v. OpenAI preservation order requiring OpenAI to retain even deleted chats.
What actually shipped
ChatGPT can now read your transactions. The preview, gated to US Pro, defaults to GPT-5.5 Thinking and pulls spending, investments, and liabilities through Plaid into a new dashboard with a persistent “financial memory” for goals and private loans. It can’t see full account numbers or move money — that boundary is the entire pitch. Intuit hooks (credit-card applications, capital-gains estimates) are flagged for later, and three separate posts from OpenAI, TechCrunch, and The Verge land on the same day to signal this isn’t an experiment but a positioning move.
The deletion promise has a legal asterisk
OpenAI tells users that disconnecting an account purges the data within 30 days. That sits awkwardly next to the still-active preservation order in NYT v. OpenAI, which compels OpenAI to retain user chat logs — including ones a user has deleted — to support copyright-infringement discovery 1. For a product whose only value is users trusting OpenAI with net-worth-level data, “we delete it” and “a court says we can’t” are not reconcilable in the marketing copy.
”Read-only” doesn’t mean safe
The read-only frame assumes the threat model is OpenAI moving money it shouldn’t. The actual demonstrated attack class is data exfiltration through prompt injection. Zenity’s AgentFlayer showed a poisoned document tricking ChatGPT connectors into searching connected accounts and leaking results via image-render URL parameters; Tenable’s “HackedGPT” work says equivalent injections still bypass GPT-5 2.
flowchart LR
A[Bank / brokerage] -->|Plaid, read-only| B{ChatGPT + memory}
C[Poisoned doc / web page] -->|indirect prompt injection| B
B -.->|image URL exfil| D((Attacker))
Plaid being read-only on the bank side does nothing if the agent on the user side can be coerced into narrating balances to an attacker-controlled URL.
The accuracy gap
OpenAI’s headline numbers come from an internal rubric graded by 50+ professionals: GPT-5.5 Pro at 82.5, Thinking at 79.0, last-gen Instant at 59.4. Independent evaluators tell a different story. Money.com ran 21 real personal-finance scenarios and graded ChatGPT a B- (2.82/4), flagging stale market data — a February housing report when April was public — and missed timing fundamentals like credit-bureau update cycles 3. PlanAdviser found chatbots that pass CFA-style multiple choice still botch estate planning, omit 529s, and make arithmetic errors experts warn can mean “multi-six-figure lost opportunities” 4. OpenAI’s own disclaimer — not a replacement for professional advice — is doing a lot of load-bearing work.
Why this is a wedge, not a feature
Plaid’s own blog post on the partnership says the quiet part out loud: this is scaffolding for AI that eventually moves money, with Plaid as the trust and permissions layer 5. The competitive frame matters too — a class of MCP-based tools like Era lets users plug their Plaid data into Claude, Cursor, or ChatGPT of their choice 6. OpenAI is deliberately not building that. It’s building a silo where spending history, goals, and conversational memory live in one vendor, ready for the day “read-only” becomes a footnote.
Further reading
- OpenAI launches ChatGPT for personal finance, will let you connect bank accounts — techcrunch-ai
- OpenAI now wants ChatGPT to access your bank accounts — the-verge-ai
PwC scales Claude to 30,000 staff after cutting 1,500 jobs
Source: anthropic-news · published 2026-05-14
TL;DR
- PwC will certify 30,000 professionals on Claude under a new joint Center of Excellence, starting with US teams.
- PwC cut roughly 1,500 US jobs in May 2025 while branding itself “ChatGPT’s largest enterprise user”.
- Headline wins — underwriting from 10 weeks to 10 days, 70% faster delivery — come from unnamed clients with no independent reproduction.
- The SEC’s chief accountant has warned Big Four firms risk being “boxed in” by exactly this kind of vendor entanglement.
The headline deal
Anthropic and PwC are framing their expanded alliance as the move from pilots to production: a joint Center of Excellence certifying 30,000 PwC professionals, Claude Code rolling out across engineering, and a new “Office of the CFO” practice that redesigns finance departments end-to-end on Claude’s product suite. The technical spine is Model Context Protocol, wiring Claude into spreadsheets, Word, and PwC’s internal ChatPwC assistant, with model access fanned out through Bedrock, Vertex, and Azure. Anthropic’s $100M Claude Partner Network underwrites the services-firm push.
The reported numbers are loud. Insurance underwriting cycles compressed from 10 weeks to 10 days. Cybersecurity incident response from hours to minutes. A stalled HR transformation shipped a working prototype in a week. A COBOL modernization four times the original scope tracking on budget. Delivery times down up to 70%.
The labor subtext
The press release treats Claude as scaffolding for human teams. The labor backdrop reads differently. PwC laid off roughly 1,500 US staff in May 2025 while branding itself “ChatGPT’s largest enterprise user” 7, and Global Chairman Mohamed Kande has said publicly that AI will produce a permanent reduction in entry-level graduate hiring 8. Against that, “30,000 certified” is less a capability investment than a retraining mandate for the survivors — get fluent in Claude or don’t renew.
That framing matters because it changes who the customer is. Internally, the audience is partners worried about utilization. Externally, it’s CFOs being sold the same productivity story PwC just used to justify its own headcount cuts.
Verification gaps on the showcase numbers
The 10-day underwriting figure and the COBOL-at-4x-scope claim are both attributed to unnamed clients. Independent testing of Claude on legacy code is less flattering: a SoftwareMining audit found paragraph coverage dropping to 24% on larger COBOL programs, with a 42% variance in extracted business rules across repeat runs of the same source 9. Greenfield productivity claims are plausible; the mainframe-modernization claims are the ones that most need third-party reproduction, and they’re the ones with the thinnest evidence.
Practitioner reception of the Claude Code product line itself is also uneven — developers have publicly pushed back on Anthropic’s $25-per-pull-request Code Review pricing as “extortionate” 10. That’s not fatal to a six-figure-seat enterprise deal, but it complicates the “developers love it” narrative.
A consulting proxy war — with regulators watching
PwC’s deepening Anthropic bet is one move in a bifurcating market. OpenAI’s Frontier Alliance gives McKinsey, BCG, and Accenture 2–4 months of pre-release model access plus embedded engineers 11; Accenture is hedging by running both an Anthropic Business Group and an OpenAI-certified practice. Choosing a consultant is increasingly choosing a model stack.
Regulators are starting to notice the lock-in. SEC Chief Accountant Kurt Hohl recently warned Big Four firms they risk being “boxed in” by AI joint-business arrangements with the same vendors whose tools they resell 12. The Office of the CFO — finance redesigned around a single foundation-model supplier — sits exactly where that scrutiny is heading. Nothing in today’s announcement addresses it.
arXiv bans AI-slop authors, gates re-entry on peer review
Source: ars-technica-ai · published 2026-05-15
TL;DR
- arXiv will suspend authors for one year if moderators find “incontrovertible” AI-generated hallucinations in a submission.
- Returning authors can’t post directly again — their next paper must first be accepted at a peer-reviewed venue.
- This is the second tightening in seven months, after CS blocked unreviewed surveys when rejection rates hit ~10%.
- Forensic audits already catalogued papers with 9+ fabricated references and arXiv links pointing to unrelated works.
What changed
arXiv moderators announced a one-strike policy: submissions containing AI-generated hallucinations — fabricated citations, leftover “Here is a 200-word summary” meta-comments, “REF NEEDED” placeholders — trigger a one-year ban for every listed author. After the ban expires, those authors can no longer post directly; their work must first clear peer review at a “reputable venue” before reappearing on the preprint server 13.
That second clause is the interesting one. arXiv was built in 1991 specifically to route around the journal pipeline. The new rule conscripts the journal pipeline as arXiv’s probation officer.
The forensic case for “incontrovertible”
The policy’s threshold — “incontrovertible evidence” rather than stylistic AI-detector guesswork — is calibrated to a documented failure mode, not a vibe. SPY Lab at ETH Zurich audited specific arXiv IDs and found, for example, paper 2408.04723 carrying at least nine hallucinated references plus bogus arXiv links pointing to unrelated works 14. The Scientist’s broader audit of biomedical literature found fabricated citations rose roughly tenfold between 2023 and early 2026, reaching ~1 in 277 papers and totalling over 4,000 nonexistent references across nearly 3,000 papers 15.
In other words, moderators aren’t chasing a phantom. They’re targeting the specific artifact — bibliographies that cite papers that don’t exist — that automated forensics can flag with high confidence.
A pattern, not a one-off
The May 2026 ban is escalation, not a debut. On 31 October 2025, arXiv’s CS section already stopped accepting review articles and position papers unless they’d cleared peer review elsewhere. Scientific Director Steinn Sigurdsson cited rejection rates climbing from ~2% in 2023 to ~10% by late 2024 as the platform was flooded with low-quality content 16. The new policy generalises that “peer-review gate” — previously a category-specific filter on surveys — into a sitewide post-ban requirement.
flowchart LR
A[Author submits] --> B{Moderator review}
B -->|Clean| C[Posted to arXiv]
B -->|AI hallucinations| D[1-year ban<br/>all listed authors]
D --> E{Wants to return?}
E --> F[Must first pass<br/>peer review at journal/conf]
F --> C
Where it breaks
Practitioner pushback to the October precedent flagged failure modes the new rule inherits. Reddit’s r/MachineLearning noted that prestige survey venues like ACM Computing Surveys run two-year-plus review cycles — long enough that a state-of-the-art summary is obsolete by the time it qualifies for arXiv 17. Equity critiques compound this: Tatsuya Amano and others have argued non-native English researchers operate at “profound disadvantage” 18, and sanctions triggered by LLM-shaped prose risk punishing authors who lean on models for legitimate language polishing rather than fabricating bibliographies.
There’s also a quieter governance question: ghost co-authors listed without consent absorb the same one-year suspension as the submitter who actually pasted the slop.
The real story
The ban isn’t the headline. The headline is arXiv quietly converting from an open preprint server into a gated one, category by category, with traditional peer review as the gate. bioRxiv and SSRN still lean on disclosure rather than sanction. arXiv has now picked a side.
Further reading
- ArXiv will ban researchers who upload papers full of AI slop — the-verge-ai
Round-ups
OpenAI reshuffles again, putting Brockman in charge of all product
Source: the-verge-ai
President Greg Brockman now officially leads all product at OpenAI under a new reorg consolidating teams around AI agents, which Brockman’s internal memo named as the company’s defining strategic bet for the year.
Judge delays Anthropic’s $1.5B author settlement over fee dispute
Source: ars-technica-ai
Approval of Anthropic’s record copyright settlement with authors has stalled after objectors accused plaintiffs’ lawyers of rushing the deal to lock in $320 million in fees, leaving per-author payouts from the book-piracy case in limbo.
OpenAI details GPT-5.5 and Codex enterprise rollouts at Databricks and Sea
Source: openai-blog, openai-blog
Fresh case studies pair Databricks running GPT-5.5 for enterprise agent workflows, where it set a new state of the art on the OfficeQA Pro benchmark, with Sea Limited deploying Codex across its engineering org to speed AI-native software development in Asia.
AI-generated papers flood journals, breaking peer review and citations
Source: the-verge-ai
Scientists are grappling with a surge of plausible-sounding AI-written manuscripts that game peer review and distort citation counts. One 2017 statistics paper drew a suspicious spike in references, hinting at machine-generated work mining older studies for credibility.
YouTube opens AI deepfake detection to all adult users
Source: the-verge-ai
YouTube’s likeness detection tool now covers every user over 18, scaling a program previously limited to select creators. Users submit a selfie-style face scan, and the platform flags lookalike videos for review, giving ordinary accounts a way to hunt AI-generated impersonations.
Runway pitches video generation as the path to world models
Source: techcrunch-ai
The filmmaker-focused startup is reframing itself as a world-models contender taking on Google, arguing that training on video is the shortest route to systems that simulate physical reality and that outsider status helps rather than hurts.
Pennsylvania residents pack town hall to oppose data center boom
Source: ars-technica-ai
Residents framed the buildout as a public trust and transparency issue at a town hall pushing back on the state’s surging data center construction, the latest local revolt against grid strain, water use and opaque siting deals tied to AI compute demand.
Footnotes
-
Liminal.ai analysis of NYT v. OpenAI preservation order — https://www.liminal.ai/blog/data-privacy-and-model-providers-understanding-the-impact-of-openais-court-order
↩OpenAI’s 30-day deletion commitment for synced financial data conflicts with a court order in the NYT litigation requiring preservation of all user chat logs — including those a user has deleted — to track potential copyright infringement.
-
Mashable on AgentFlayer / indirect prompt injection — https://mashable.com/article/ai-security-risks-at-work
↩Zenity’s ‘AgentFlayer’ demo showed a poisoned document tricking ChatGPT’s connectors into searching connected accounts and exfiltrating data via image-render URL parameters — a class of attack Tenable says still works against GPT-5 (‘HackedGPT’).
-
Money.com hands-on grading of ChatGPT financial advice — https://money.com/ai-vs-human-financial-analysts/
↩Across 21 personal finance scenarios, ChatGPT earned a B- (2.82/4): responses were detailed but pulled stale market data (a February housing report when April was available) and missed timing fundamentals like credit-bureau update cycles.
-
PlanAdviser on AI chatbot competence in finance — https://www.planadviser.com/popular-ai-chatbots-struggle-with-estate-planning-but-pass-cfa-exams/
↩Popular chatbots pass CFA-style multiple choice but ‘struggle with estate planning,’ omitting tax-advantaged tools like 529 plans and making basic arithmetic errors that experts warn could mean ‘multi-six-figure lost opportunities.’
-
Plaid blog (Zach Perret on the OpenAI partnership) — https://plaid.com/blog/chatgpt-personal-finance-plaid/
↩Plaid frames the ChatGPT integration as a foundational step toward ‘agentic finance’ in which AI eventually moves money and executes trades, with Plaid serving as both the intelligence layer and the trust/permissions layer.
-
Getfinny ‘Best AI budget apps 2026’ roundup — https://getfinny.app/blog/best-ai-budget-apps-2026
↩A new class of competitors like Era uses Model Context Protocol (MCP) to let users plug their financial data into any AI client — Claude, ChatGPT, Cursor — contrasting with the ‘all-in-one silos’ OpenAI is now building with Plaid.
-
Forbes (Westfall) — https://www.forbes.com/sites/chriswestfall/2025/05/07/chatgpts-largest-enterprise-user-pwc-cuts-workforce-by-1500-jobs/
↩ChatGPT’s largest enterprise user PwC cuts workforce by 1,500 jobs
-
Evrim Agaci / PwC Chair Kande remarks — https://evrimagaci.org/gpt/ai-revolution-reshapes-graduate-jobs-at-pwc-and-beyond-517184
↩Global Chairman Mohamed Kande warned that AI’s ability to handle routine analytical work will likely lead to a permanent reduction in entry-level graduate hiring
-
SoftwareMining technical audit — https://softwaremining.com/papers/claude-vs-softwaremining.jsp
↩the tool’s paragraph coverage dropped as low as 24% on larger programs, and independent runs on the same code produced a 42% variance in the number of business rules extracted
-
Level Up Coding (gitconnected) — https://levelup.gitconnected.com/anthropic-wants-25-per-pull-request-devs-are-losing-their-minds-over-claude-code-review-55dbbaca4996
↩Anthropic wants $25 per pull request — devs are losing their minds over Claude Code Review
-
DigitalApplied (OpenAI Frontier Alliance brief) — https://www.digitalapplied.com/blog/openai-frontier-alliance-mckinsey-bcg-accenture-guide
↩McKinsey, alongside BCG and Accenture, serves as a primary ‘Frontier’ partner, gaining exclusive 2-4 month early access to unreleased models
-
SL Guardian (SEC coverage) — https://slguardian.org/sec-signals-shake-up-of-auditor-independence-rules-amid-big-tech-ai-entanglements/
↩SEC Chief Accountant Kurt Hohl recently warned that as the Big Four increasingly sell or integrate tools from providers like Microsoft and OpenAI, they risk becoming ‘boxed in’ by conflicts
-
404 Media — https://www.404media.co/new-arxiv-rules-ai-generated-papers-ban/
↩After the ban expires, those authors are prohibited from posting new preprints directly; their work must first be accepted at a reputable peer-reviewed venue before it can appear on arXiv.
-
SPY Lab (ETH Zurich) — https://spylab.ai/blog/hallucinations/
↩Paper 2408.04723 contains at least nine hallucinated references and numerous bogus arXiv links pointing to unrelated works… 2408.10263 was cited for having multiple incorrect authors and broken links, indicating ‘LLM dreams’ had replaced factual bibliography.
-
The Scientist — https://www.the-scientist.com/one-in-277-biomedical-papers-carry-fake-references-74480
↩Hallucinated citations rose roughly tenfold between 2023 and early 2026, reaching a frequency of approximately 1 in every 277 biomedical papers; over 4,000 entirely nonexistent citations were identified across nearly 3,000 papers.
-
Gigazine (on arXiv Oct 2025 CS policy) — https://gigazine.net/gsc_news/en/20251110-arxiv-update-practice-for-review-articles/
↩Effective October 31, 2025, arXiv’s CS category required review articles and position papers to first complete peer review at a journal or conference; Scientific Director Steinn Sigurdsson said rejection rates rose from ~2% in 2023 to 10% by late 2024 as the platform was flooded with low-quality content.
-
r/MachineLearning discussion on prior arXiv CS rule — https://www.reddit.com/r/MachineLearning/comments/1ol8wup/d_arxiv_cs_to_stop_accepting_literature/
↩Prestigious survey venues such as ACM Computing Surveys often have review cycles lasting two or more years, meaning important state-of-the-art summaries may be obsolete by the time they are eligible for arXiv.
-
Times Higher Education (Tatsuya Amano) — https://www.timeshighereducation.com/news/non-native-english-speaking-scientists-profound-disadvantage
↩We are potentially losing a huge contribution to science… simply because their first language isn’t English.